As discussed IRL, these will need to change for all the upcoming multi-Data Center stuff.
See also T94028: DB master connections requested by Flow on GET/HEAD requests
| aaron | |
| Mar 26 2015, 2:41 PM |
| F2950978: Screen Shot 2015-11-10 at 15.51.10.png | |
| Nov 10 2015, 2:59 PM |
| F2950979: Screen Shot 2015-11-10 at 15.51.23.png | |
| Nov 10 2015, 2:59 PM |
As discussed IRL, these will need to change for all the upcoming multi-Data Center stuff.
See also T94028: DB master connections requested by Flow on GET/HEAD requests
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| Expire Flow caches after 1 day | operations/mediawiki-config | master | +1 -0 |
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T128228 Improve how transactions work for board moves | |||
| Resolved | aaron | T88445 MediaWiki active/active datacenter investigation and work (tracking) | |||
| Resolved | SBisson | T120009 Flow: Use WAN cache delete() and replica-based filling to avoid merge() | |||
| Resolved | matthiasmullie | T94029 Spike: Avoid use of merge() in Flow caches |
Not sure if there is an additional task for this (other than T94028: DB master connections requested by Flow on GET/HEAD requests), but we've talked about changing the backend to drop the Index layer as a solution to this.
Is this on anyone's plate to work on. The use of merge() is not just slow (like master queries) but totally broken for multi DC MW. I wonder if it would just be easier to remove the caching layers mostly rather than try to replace them.
Stripping out the caching layer is probably the easiest way to go about this, and tbh i don't think the caching layer in Flow ended up being incredibly useful.
Yes. I already scheduled a meeting on Wednesday to discuss this. This is both because it's still blocking multi-DC and because other issues are still occasionally cropping up (though not that often). E.g.
I think where we ended up in the meeting was that we should gradually reduce the memcached time to live, preferably while keeping performance metrics, and rewriting the database fallback queries.
The other possible approach is to replace merge with delete. WANObjectCache has special provisions to allow a delete() to win even if a stale set() happens shortly after the delete(), but before the slave DB is up to date (hence, stale).
Implementing WANObjectCache is likely going to be more work than I had anticipated.
We use BufferedBagOStuff, which:
We would probably have to refactor significant pieces of code. And since we're considering throwing away the cache layer...
I just submitted https://gerrit.wikimedia.org/r/#/c/247575/, which will make our code stop backfilling cache from DB.
That also means we no longer have to read from DB_MASTER (which we did to ensure data in cache is current)
And this also means we should be able to start lowering $wgFlowCacheTime until we can set $wgFlowUseMemcache = false.
Cache will gradually hold less data & we can monitor how badly that affects the DB.
Current summary (https://tendril.wikimedia.org/host/view/db1029.eqiad.wmnet/3306)
db1029 : replication family
| Host | IPv4 | Release | RAM | Up | Act. | QPS | Rep | Lag | Tree |
| db1029 | 10.64.16.18 | 5.5.30 | 64G | 945d | 0s | 2392 | - | - | masters: n/a slaves: db1031, db2009 |
| db1031 | 10.64.16.20 | 5.5.30 | 64G | 945d | 3s | 466 | Yes | 0s | masters: db1029 slaves: n/a |
| db2009 | 10.192.0.12 | 10.0.15 | 64G | 307d | 9s | 1 | Yes | 0s | masters: db1029 slaves: n/a |
Slow query log: https://tendril.wikimedia.org/report/slow_queries?host=family%3Adb1029
Blocked on https://gerrit.wikimedia.org/r/#/c/247575/. Only after that has merged, we can start lowering cache TTL to examine if getting rid of the cache is viable.
It's been merged. I'm moving it back into dev so you can continue with the next steps.
Change 249402 had a related patch set uploaded (by Matthias Mullie):
Expire Flow caches after 1 day
Moved back to blocked. First patch to lower cache TTL is on Gerrit, but I'd like to first see the impact of https://gerrit.wikimedia.org/r/#/c/247575/, once it hits production. That'll take another week.
Current summary (https://tendril.wikimedia.org/host/view/db1029.eqiad.wmnet/3306)
db1029 : replication family
| Host | IPv4 | Release | RAM | Up | Act. | QPS | Rep | Lag | Tree |
| db1029 | 10.64.16.18 | 5.5.30 | 64G | 955d | 9s | 2531 | - | - | masters: n/a slaves: db1031, db2009, dbstore1002 |
| db1031 | 10.64.16.20 | 5.5.30 | 64G | 955d | 2s | 464 | Yes | 0s | masters: db1029 slaves: n/a |
| db2009 | 10.192.0.12 | 10.0.15 | 64G | 317d | 8s | 1 | Yes | 0s | masters: db1029 slaves: n/a |
Summary (https://tendril.wikimedia.org/host/view/db1029.eqiad.wmnet/3306)
Slow query log: https://tendril.wikimedia.org/report/slow_queries?host=family%3Adb1029
Prior to https://gerrit.wikimedia.org/r/#/c/247575/:
| Host | IPv4 | Release | RAM | Up | Act. | QPS | Rep | Lag | Tree |
| db1029 | 10.64.16.18 | 5.5.30 | 64G | 945d | 0s | 2392 | - | - | masters: n/a slaves: db1031, db2009 |
| db1031 | 10.64.16.20 | 5.5.30 | 64G | 945d | 3s | 466 | Yes | 0s | masters: db1029 slaves: n/a |
| db2009 | 10.192.0.12 | 10.0.15 | 64G | 307d | 9s | 1 | Yes | 0s | masters: db1029 slaves: n/a |
After:
| Host | IPv4 | Release | RAM | Up | Act. | QPS | Rep | Lag | Tree |
| db1029 | 10.64.16.18 | 5.5.30 | 64G | 966d | 5s | 979 | - | - | masters: n/a slaves: db1031, db2009, dbstore1001, dbstore1002 |
| db1031 | 10.64.16.20 | 5.5.30 | 64G | 966d | 8s | 1938 | Yes | 0s | masters: db1029 slaves: n/a |
| db2009 | 10.192.0.12 | 10.0.15 | 64G | 328d | 4s | 1 | Yes | 0s | masters: db1029 slaves: dbstore2001, dbstore2002 |
Traffic diff
DB_MASTER:
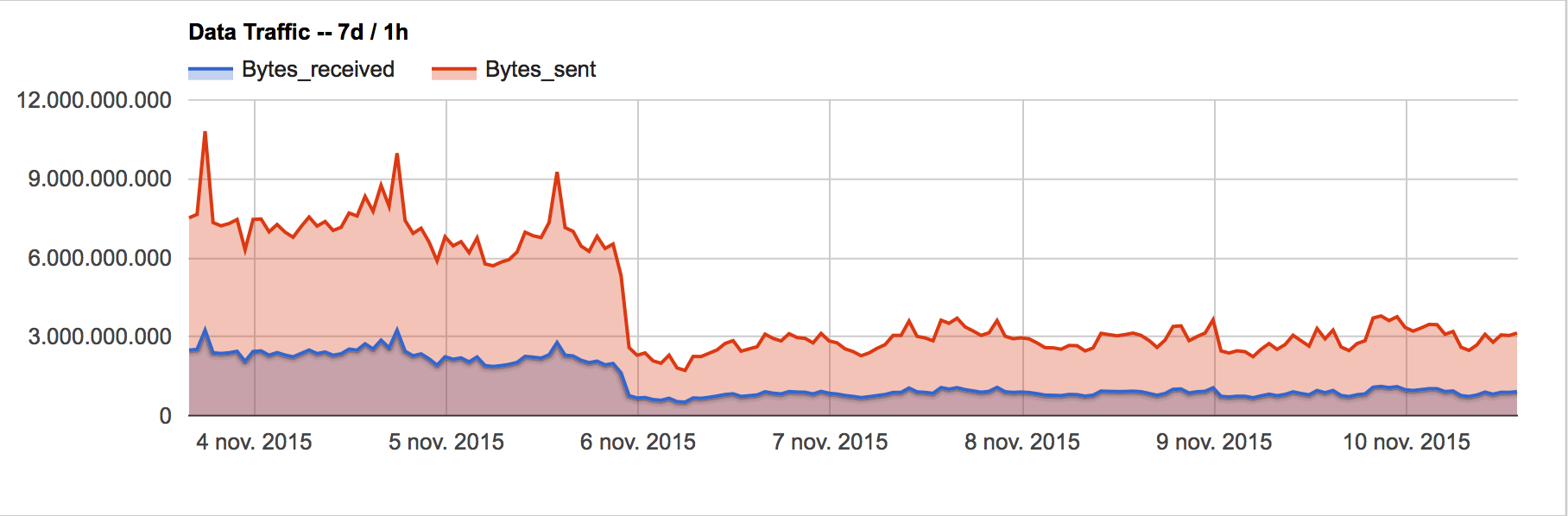
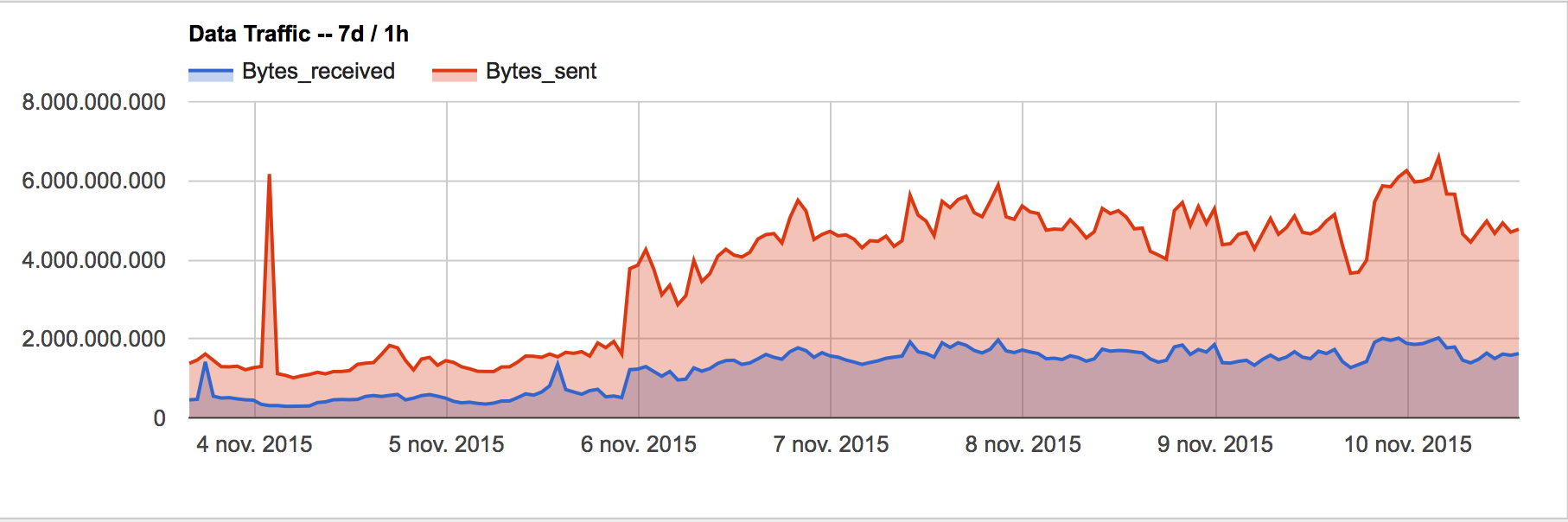
Queries to master have decreased a lot.
I'm currently not seeing worrying stats or slow queries on flow_* columns.
Let's proceed & lower cache TTL: https://gerrit.wikimedia.org/r/249402
I'd like to mitigate at least some of T118434: Reduce Flow DB queries on Special:Contributions before we do this. Right now, that bug's impact is probably reduced in production because of the caches.
In today's meeting, we decided to try the WANCache delete()/locally populate from slave approach.
We decided there were too many tasks about this. This was originally a spike to investigate this. There are remaining tasks about it, e.g. T120009: Flow: Use WAN cache delete() and replica-based filling to avoid merge().