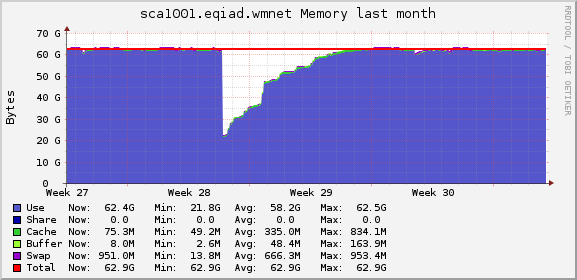
Apertium opens a ton of processes that eat up a ton of RAM on sca1001.
root@sca1001:~# ps -u apertium -fa | wc -l 4383
most of these processes are even one week old, some are fresh. All the ones I straced were listening on a FIFO pipe open with the apertium process, which suggests me a subprocess call from apertium that is not handled correctly.
This is a serious problem as those processes are eating up a sizeable amount of ram.