˜/Reedy 10:40> #1290: The MariaDB server is running with the --read-only option so it cannot execute this statement
˜/icinga-wm 10:41> PROBLEM - haproxy failover on dbproxy1003 is CRITICAL: CRITICAL check_failover servers up 2 down 1
˜/icinga-wm 10:41> PROBLEM - haproxy failover on dbproxy1008 is CRITICAL: CRITICAL check_failover servers up 2 down 1
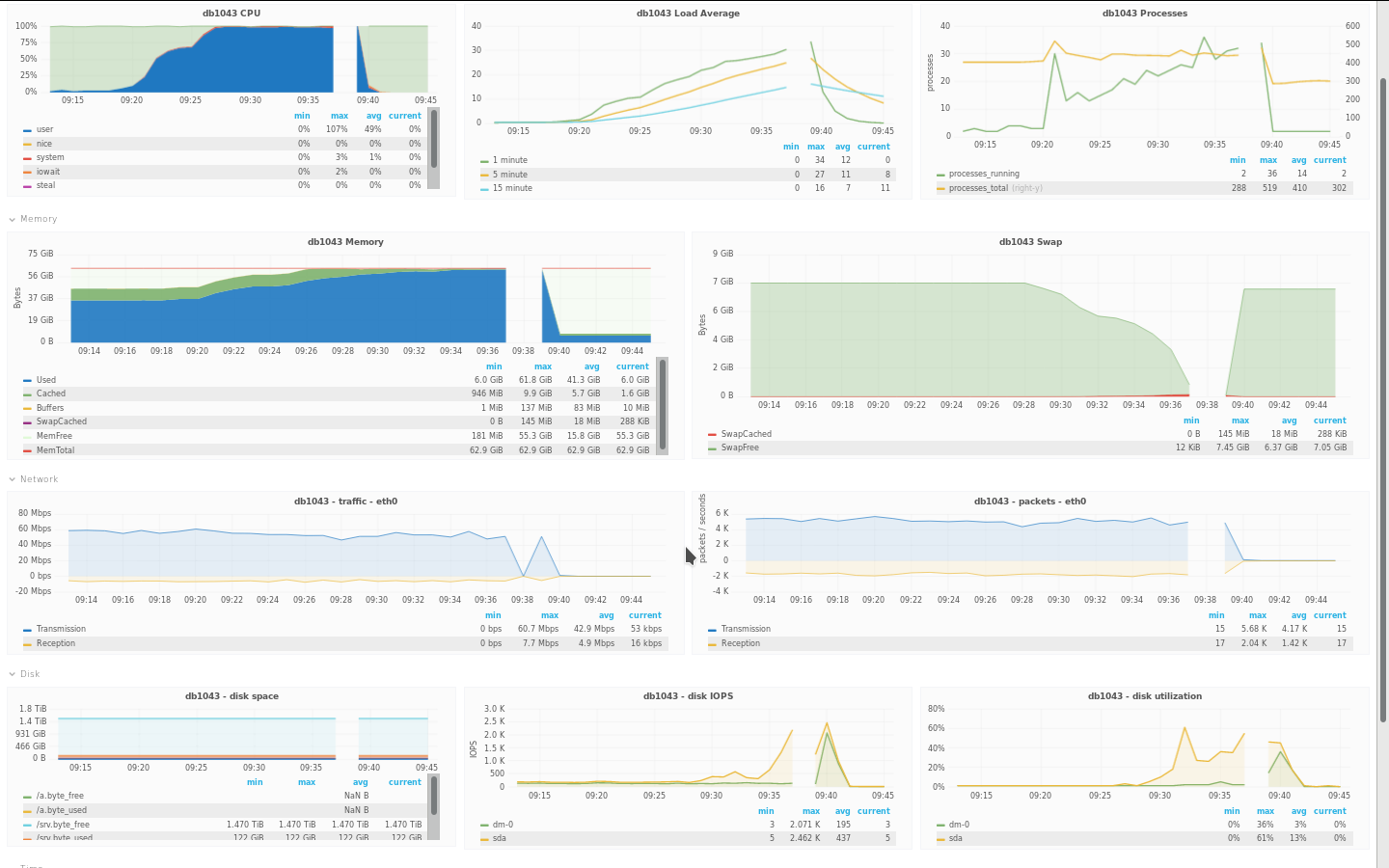
Looks like MySQL crashed:
170201 9:39:04 [ERROR] InnoDB: InnoDB: Unable to allocate memory of size 8104. 2017-02-01 09:39:04 7fc382ee9700 InnoDB: Assertion failure in thread 140477692024576 in file ha_innodb.cc line 18984 InnoDB: We intentionally generate a memory trap. InnoDB: Submit a detailed bug report to http://bugs.mysql.com. InnoDB: If you get repeated assertion failures or crashes, even InnoDB: immediately after the mysqld startup, there may be InnoDB: corruption in the InnoDB tablespace. Please refer to InnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html InnoDB: about forcing recovery. %%%%"%"""%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%"""%%%%%%%%""%%%%%%%%%"""""""""%"%"%%%%%%%%%%%%%%%%%%%%%%%%""%""170201 9:39:05 [ERROR] mysqld got signal 6 ; This could be because you hit a bug. It is also possible that this binary or one of the libraries it was linked against is corrupt, improperly built, or misconfigured. This error can also be caused by malfunctioning hardware. To report this bug, see http://kb.askmonty.org/en/reporting-bugs We will try our best to scrape up some info that will hopefully help diagnose the problem, but since we have already crashed, something is definitely wrong and this may fail. Server version: 10.0.23-MariaDB-log key_buffer_size=134217728 read_buffer_size=131072 max_used_connections=1501 max_threads=1511 thread_count=157 It is possible that mysqld could use up to key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 3448842 K bytes of memory Hope that's ok; if not, decrease some variables in the equation. Thread pointer: 0x0x7fc3e8f49008 Killed 170201 09:39:11 mysqld_safe Number of processes running now: 0 170201 09:39:11 mysqld_safe mysqld restarted 170201 9:39:11 [Note] /opt/wmf-mariadb10/bin/mysqld (mysqld 10.0.23-MariaDB-log) starting as process 29023 ... 170201 9:39:11 [Warning] No argument was provided to --log-bin and neither --log-basename or --log-bin-index where used; This may cause repliction to break when this server acts as a master and has its hostname changed! Please use '--log-basename=db1043' or '--log-bin=db1043-bin' to avoid this problem. 2017-02-01 09:39:11 7fa492504780 InnoDB: Warning: Using innodb_locks_unsafe_for_binlog is DEPRECATED. This option may be removed in future releases. Please use READ COMMITTED transaction isolation level instead, see http://dev.mysql.com/doc/refman/5.6/en/set-transaction.html. 170201 9:39:11 [Note] InnoDB: Using mutexes to ref count buffer pool pages 170201 9:39:11 [Note] InnoDB: The InnoDB memory heap is disabled 170201 9:39:11 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins 170201 9:39:11 [Note] InnoDB: Memory barrier is not used 170201 9:39:11 [Note] InnoDB: Compressed tables use zlib 1.2.3 170201 9:39:11 [Note] InnoDB: Using Linux native AIO 170201 9:39:11 [Note] InnoDB: Using CPU crc32 instructions 170201 9:39:11 [Note] InnoDB: Initializing buffer pool, size = 47.0G 170201 9:39:14 [Note] InnoDB: Completed initialization of buffer pool 170201 9:39:14 [Note] InnoDB: Highest supported file format is Barracuda. 170201 9:39:14 [Note] InnoDB: Log scan progressed past the checkpoint lsn 1975103475491 170201 9:39:14 [Note] InnoDB: Database was not shutdown normally! 170201 9:39:14 [Note] InnoDB: Starting crash recovery. 170201 9:39:14 [Note] InnoDB: Reading tablespace information from the .ibd files... 170201 9:39:16 [Note] InnoDB: Restoring possible half-written data pages 170201 9:39:16 [Note] InnoDB: from the doublewrite buffer... InnoDB: Doing recovery: scanned up to log sequence number 1975108718080 InnoDB: Doing recovery: scanned up to log sequence number 1975113960960 InnoDB: Doing recovery: scanned up to log sequence number 1975119203840 InnoDB: Doing recovery: scanned up to log sequence number 1975124446720 InnoDB: Doing recovery: scanned up to log sequence number 1975129689600 InnoDB: Doing recovery: scanned up to log sequence number 1975134932480 InnoDB: Doing recovery: scanned up to log sequence number 1975140175360 InnoDB: Doing recovery: scanned up to log sequence number 1975145418240 InnoDB: Doing recovery: scanned up to log sequence number 1975150661120 InnoDB: Doing recovery: scanned up to log sequence number 1975155904000 InnoDB: Doing recovery: scanned up to log sequence number 1975161146880 InnoDB: Doing recovery: scanned up to log sequence number 1975166389760 InnoDB: Doing recovery: scanned up to log sequence number 1975171632640 InnoDB: Doing recovery: scanned up to log sequence number 1975176875520 InnoDB: Doing recovery: scanned up to log sequence number 1975182118400 InnoDB: Doing recovery: scanned up to log sequence number 1975187361280 InnoDB: Doing recovery: scanned up to log sequence number 1975192604160 InnoDB: Doing recovery: scanned up to log sequence number 1975197847040 InnoDB: Doing recovery: scanned up to log sequence number 1975203089920 InnoDB: Doing recovery: scanned up to log sequence number 1975208332800 InnoDB: Doing recovery: scanned up to log sequence number 1975213575680 InnoDB: Doing recovery: scanned up to log sequence number 1975218818560 InnoDB: Doing recovery: scanned up to log sequence number 1975224061440 InnoDB: Doing recovery: scanned up to log sequence number 1975229304320 InnoDB: Doing recovery: scanned up to log sequence number 1975234547200 InnoDB: Doing recovery: scanned up to log sequence number 1975239790080 InnoDB: Doing recovery: scanned up to log sequence number 1975245032960 InnoDB: Doing recovery: scanned up to log sequence number 1975250275840 InnoDB: Doing recovery: scanned up to log sequence number 1975255518720 InnoDB: Doing recovery: scanned up to log sequence number 1975260761600 InnoDB: Doing recovery: scanned up to log sequence number 1975266004480 InnoDB: Doing recovery: scanned up to log sequence number 1975271247360 InnoDB: Doing recovery: scanned up to log sequence number 1975276490240 InnoDB: Doing recovery: scanned up to log sequence number 1975281733120 InnoDB: Doing recovery: scanned up to log sequence number 1975286976000 InnoDB: Doing recovery: scanned up to log sequence number 1975292218880 InnoDB: Doing recovery: scanned up to log sequence number 1975297461760 InnoDB: Doing recovery: scanned up to log sequence number 1975302704640 InnoDB: Doing recovery: scanned up to log sequence number 1975307947520 InnoDB: Doing recovery: scanned up to log sequence number 1975313190400 InnoDB: Doing recovery: scanned up to log sequence number 1975318433280 InnoDB: Doing recovery: scanned up to log sequence number 1975323676160 InnoDB: Doing recovery: scanned up to log sequence number 1975328919040 InnoDB: Doing recovery: scanned up to log sequence number 1975334161920 InnoDB: Doing recovery: scanned up to log sequence number 1975339404800 InnoDB: Doing recovery: scanned up to log sequence number 1975344647680 InnoDB: Doing recovery: scanned up to log sequence number 1975349890560 InnoDB: Doing recovery: scanned up to log sequence number 1975355133440 InnoDB: Doing recovery: scanned up to log sequence number 1975360376320 InnoDB: Doing recovery: scanned up to log sequence number 1975365619200 InnoDB: Doing recovery: scanned up to log sequence number 1975370862080 InnoDB: Doing recovery: scanned up to log sequence number 1975376104960 InnoDB: Doing recovery: scanned up to log sequence number 1975377824940 170201 9:39:22 [Note] InnoDB: Starting an apply batch of log records to the database... InnoDB: Progress in percent: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 InnoDB: Apply batch completed InnoDB: Last MySQL binlog file position 0 365290759, file name ./db1043-bin.001478 170201 9:39:37 [Note] InnoDB: 128 rollback segment(s) are active. 170201 9:39:37 [Note] InnoDB: Waiting for purge to start 170201 9:39:37 [Note] InnoDB: Percona XtraDB (http://www.percona.com) 5.6.26-76.0 started; log sequence number 1975377824940 2017-02-01 09:39:37 7f97a67f9700 InnoDB: Loading buffer pool(s) from .//ib_buffer_pool 2017-02-01 09:39:37 7f97a67f9700 InnoDB: Cannot open './/ib_buffer_pool' for reading: No such file or directory 170201 9:39:37 [ERROR] Plugin 'unix_socket' already installed 170201 9:39:37 [Note] Recovering after a crash using db1043-bin 170201 9:39:39 [Note] Starting crash recovery... 170201 9:39:39 [Note] Crash recovery finished. 170201 9:39:39 [Note] Server socket created on IP: '::'. 170201 9:39:39 [Note] Server socket created on IP: '::'. 170201 9:39:39 [Warning] 'user' entry 'phstats@iridium' ignored in --skip-name-resolve mode. 170201 9:39:39 [Warning] 'db' entry 'phabricator_user phstats@iridium' ignored in --skip-name-resolve mode. 170201 9:39:39 [Warning] 'proxies_priv' entry '@% root@db1043' ignored in --skip-name-resolve mode. 170201 9:39:39 [Note] Event Scheduler: scheduler thread started with id 2 170201 9:39:39 [Warning] Neither --relay-log nor --relay-log-index were used; so replication may break when this MySQL server acts as a slave and has his hostname changed!! Please use '--log-basename=#' or '--relay-log=db1043-relay-bin' to avoid this problem. 170201 9:39:39 [Note] /opt/wmf-mariadb10/bin/mysqld: ready for connections. Version: '10.0.23-MariaDB-log' socket: '/tmp/mysql.sock' port: 3306 MariaDB Server 170201 9:39:40 [ERROR] mysqld: Table './heartbeat/heartbeat' is marked as crashed and should be repaired 170201 9:39:40 [Warning] Checking table: './heartbeat/heartbeat' 170201 9:39:46 [ERROR] Slave I/O: error connecting to master 'repl@db1048.eqiad.wmnet:3306' - retry-time: 60 retries: 86400 message: SSL connection error: error:00000000:lib(0):func(0):reason(0), Internal MariaDB error code: 2026 170201 9:40:46 [Note] Slave I/O thread: connected to master 'repl@db1048.eqiad.wmnet:3306',replication started in log 'db1048-bin.001436' at position 359 170201 9:40:46 [ERROR] Error reading packet from server: Could not find first log file name in binary log index file ( server_errno=1236) 170201 9:40:46 [ERROR] Slave I/O: Got fatal error 1236 from master when reading data from binary log: 'Could not find first log file name in binary log index file', Internal MariaDB error code: 1236 170201 9:40:46 [Note] Slave I/O thread exiting, read up to log 'db1048-bin.001436', position 359
This is running 10.0.23 which is not affected by the bug that hit: T156373