With the new approach of translation units, each section translation unit can report its progress and translation controller need to sum up it and save. There is no progressbar in translationview to present the progress, but it is used for the dashboard.
Description
Description
Details
Details
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| Translation progress calculation | mediawiki/extensions/ContentTranslation | master | +563 -5 |
| Status | Subtype | Assigned | Task | |
|---|---|---|---|---|
| · · · | ||||
| Resolved | santhosh | T152586 Reorganize the CX classes using OOjs/OOUI (tracker) | ||
| Resolved | santhosh | T162113 CX2: Infrastructure for section-level progress calculation | ||
| · · · |
Event Timeline
Comment Actions
I have been reading the ve code trying to understand where we could hook. I can imagine two possible approaches.
Diffing
We store the original text [1][2] in an attribute of the section node (and expose it in the data model). When progress is queried we apply a similarity algorithm on the current text and stored text. I don't think it will be useful to track this on sub-section level (e.g. sentence annotations).
[1] Only in case of MT provider or source text is used as basis, for scratch we don't need to, as is is 100% user generated content
[2] We can store only the plain text to save space OR start loading the stored MT value from the corpora
Pros
- Can reliably calculate the MT progress at any time
- Likely simpler to implement.
- Can start by storing a hash and only providing boolean value whether the text is modified at all
- Stateless, no need to deal with any events
Cons
- Similarity algorithms such as Levenshtein distance can be slow – caching can be used
- Increased use of network (compression helps a bit) and database storage (unless we start loading the MT section section when restoring)
Change counting
We hook into ve.dm.Surface events history or transact which are related to the undo/redo functionality and document changes. For each event, we identify the affected section and increase the change counter. The progress value is then calculated by subtracting the number of changes from 100% scaled to the section length. I.e. for one word section, one change should be enough to reach at least 50% use generated content.
Pros
- Less additional storage is needed
- Faster to calculate
Cons
- More complex to implement:
- Undo stack works on the document level. For every change we would need to find the affecte section.
- When storing the change counter, if we store in the node itself, we should avoid generating an endless loop of changes. If stored elsewhere, will complicate saving/restoring code
- Undo should decrease changes, not increase
- Not as reliable. Different kind of changes are treated as equal (adding link, vs. deleting a significant amount of text).
Comment Actions
Change 444208 had a related patch set uploaded (by Santhosh; owner: Santhosh):
[mediawiki/extensions/ContentTranslation@master] WIP: Progress calculation
Comment Actions
Change 444208 merged by jenkins-bot:
[mediawiki/extensions/ContentTranslation@master] Translation progress calculation
Comment Actions
@Santosh - when testing in cx2, I noticed that the calculation of the progress is relative to the amount of translation that is done. e.g.
- Translate an article for a big portion of text
- Check the progress; the progress bar will have a correct display according to the amount of translated text.
- Return to the article and add something little - the progress bar will reset and will display the "new" progress, that little amount that was changed.
Comment Actions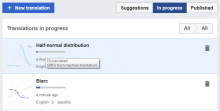
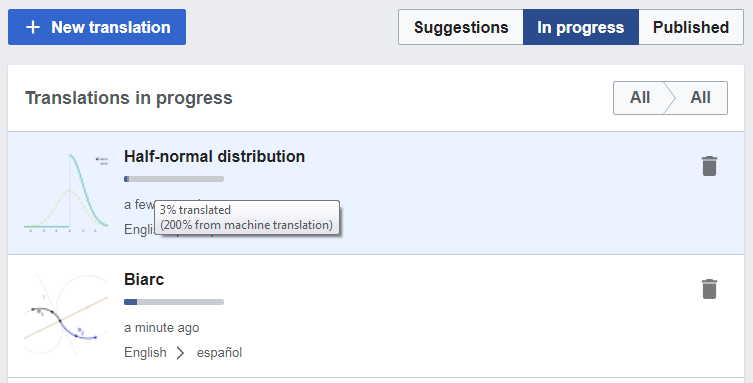
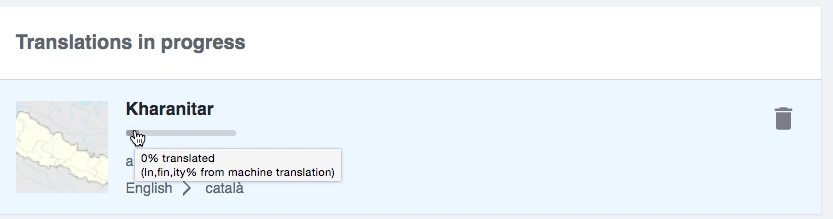
@santhosh, here is another scenario where progress calculation breaks:
- Add two paragraphs
- Switch the second paragraph to "Don't use MT"
- Return to dashboard after saving
Result - X% translated (200% percent from MT):
Comment Actions
Overall progress calculation patch is not yet merged https://gerrit.wikimedia.org/r/c/mediawiki/extensions/ContentTranslation/+/447583 - This has corrections for overall translation progress. What is merged is section level abuse detection.