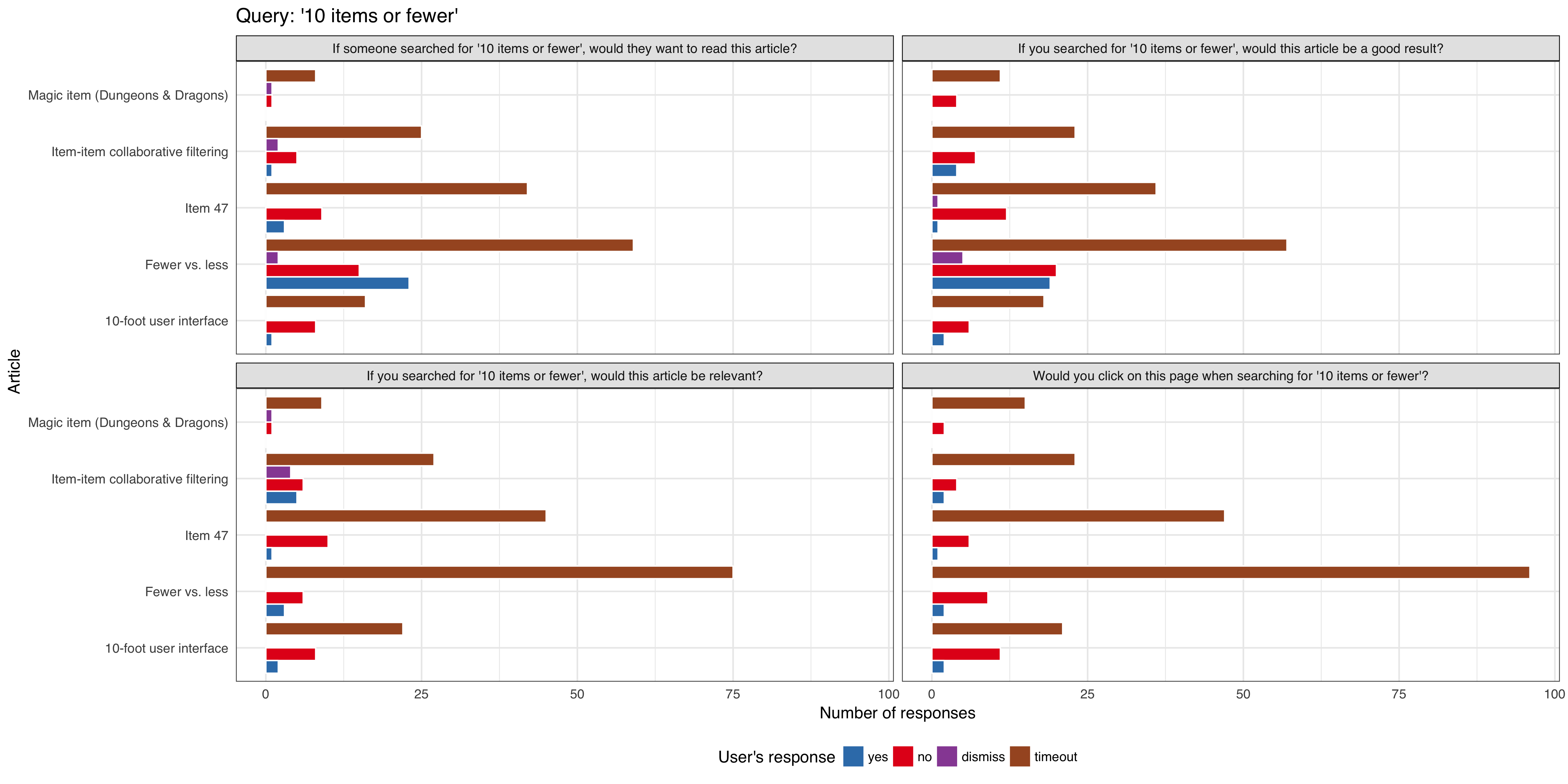
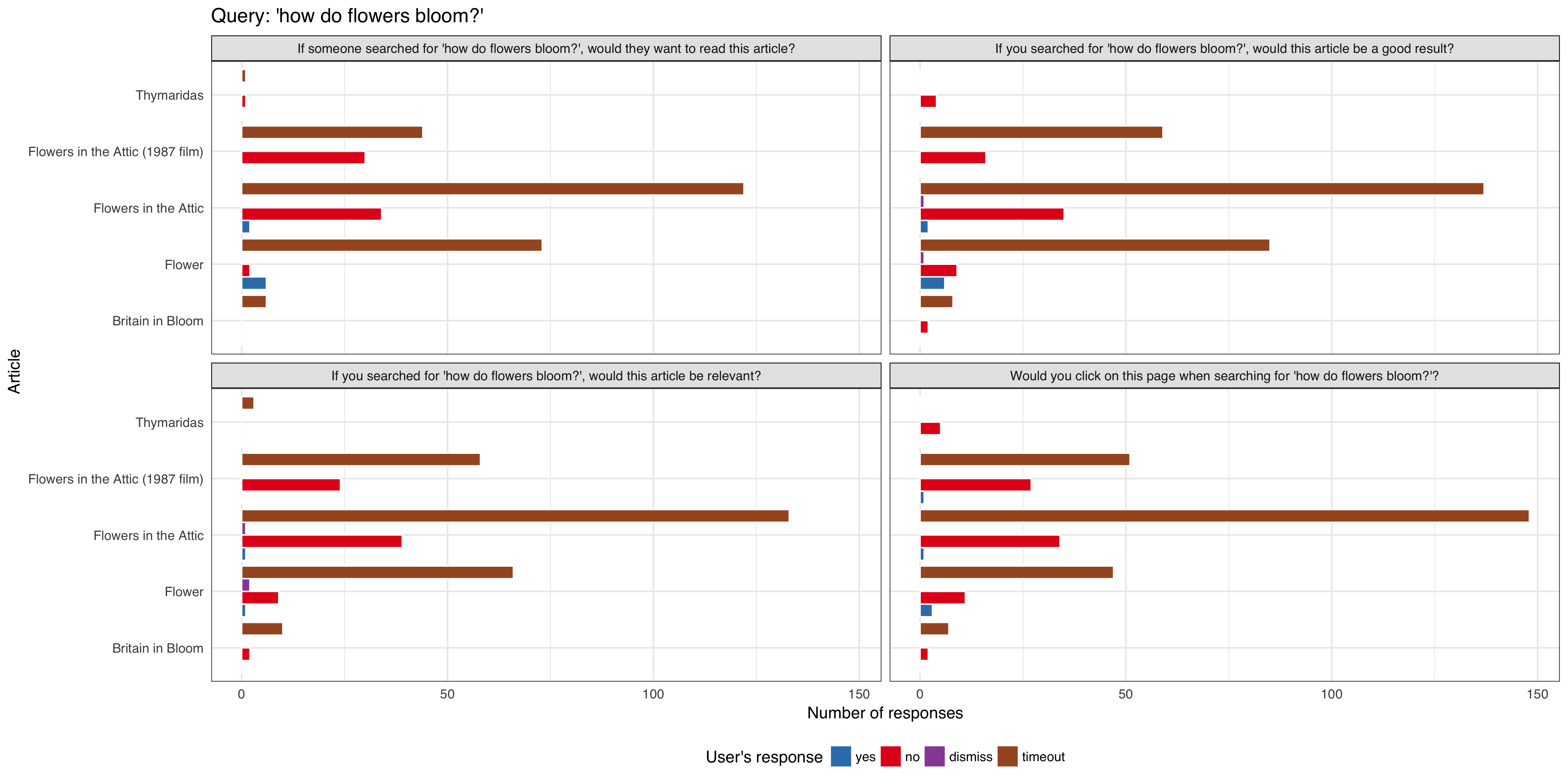
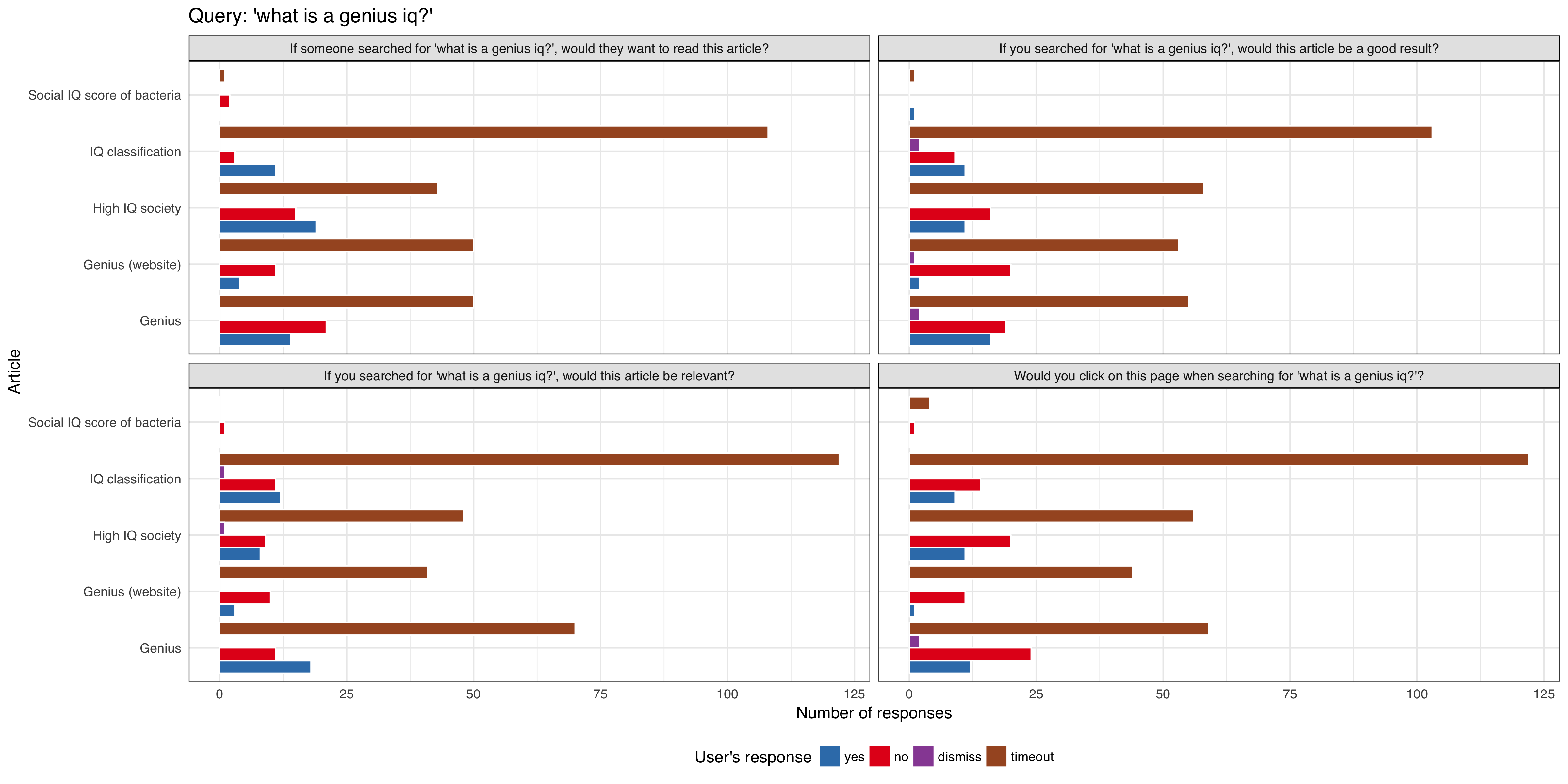
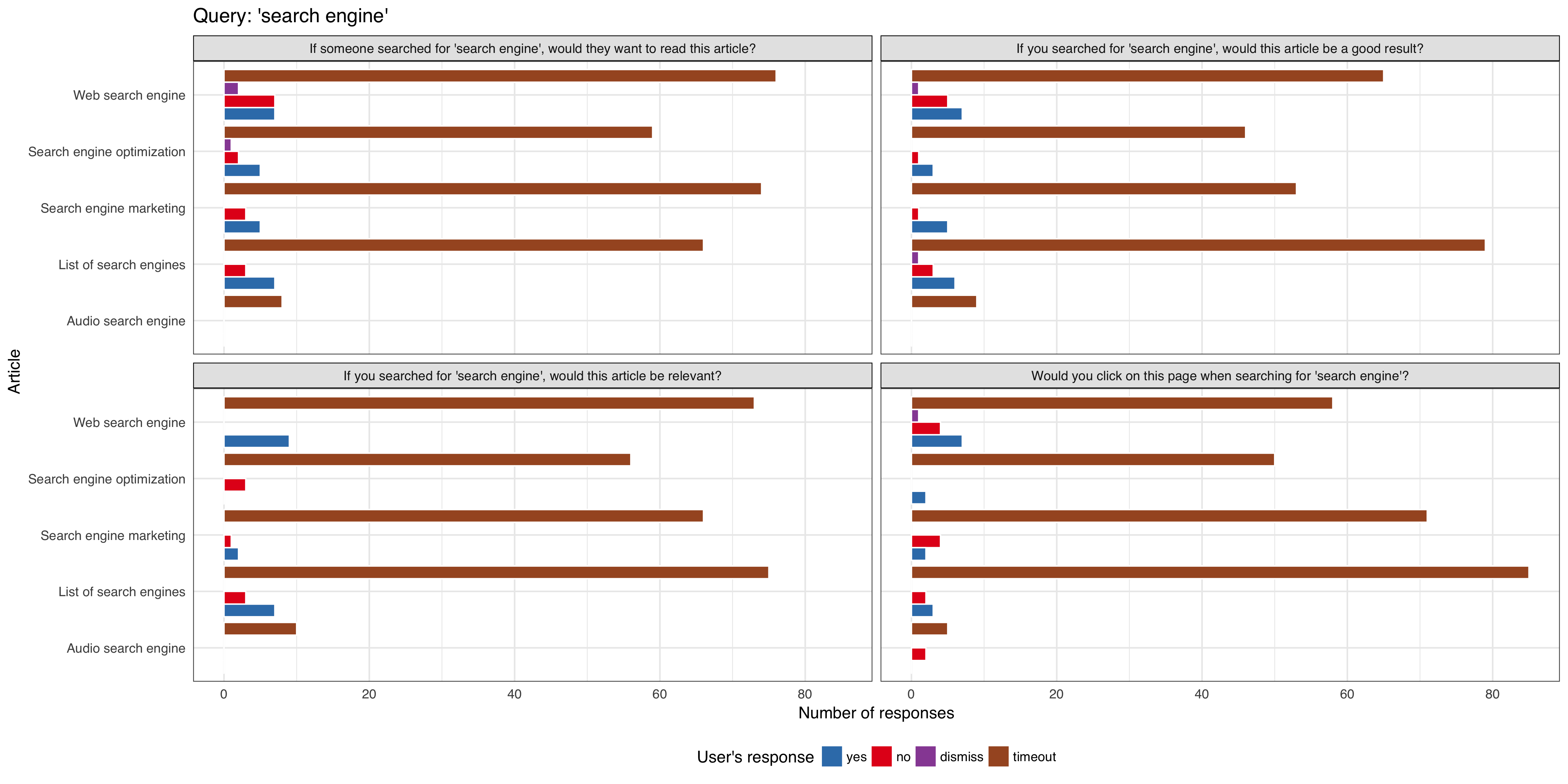
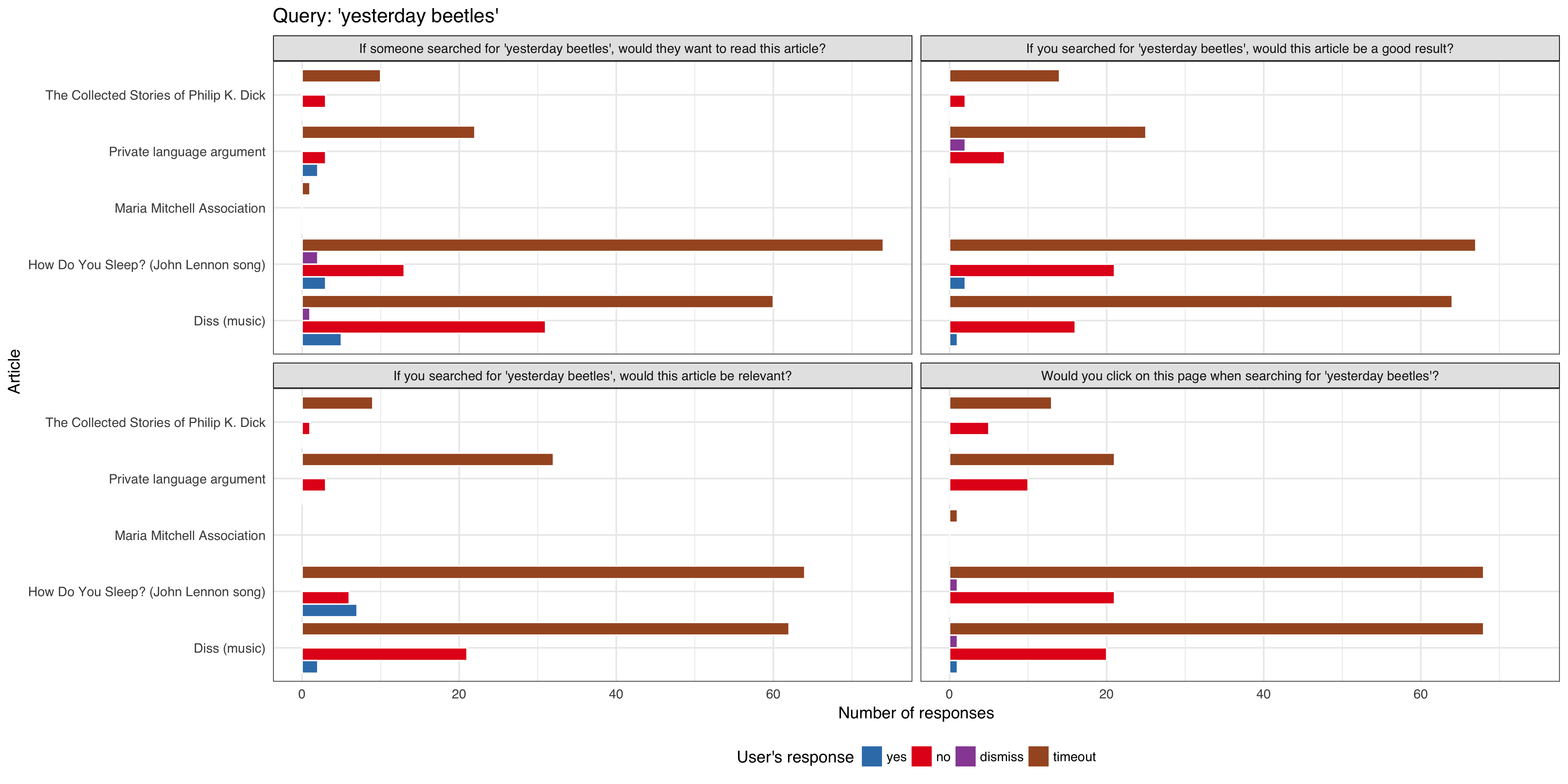
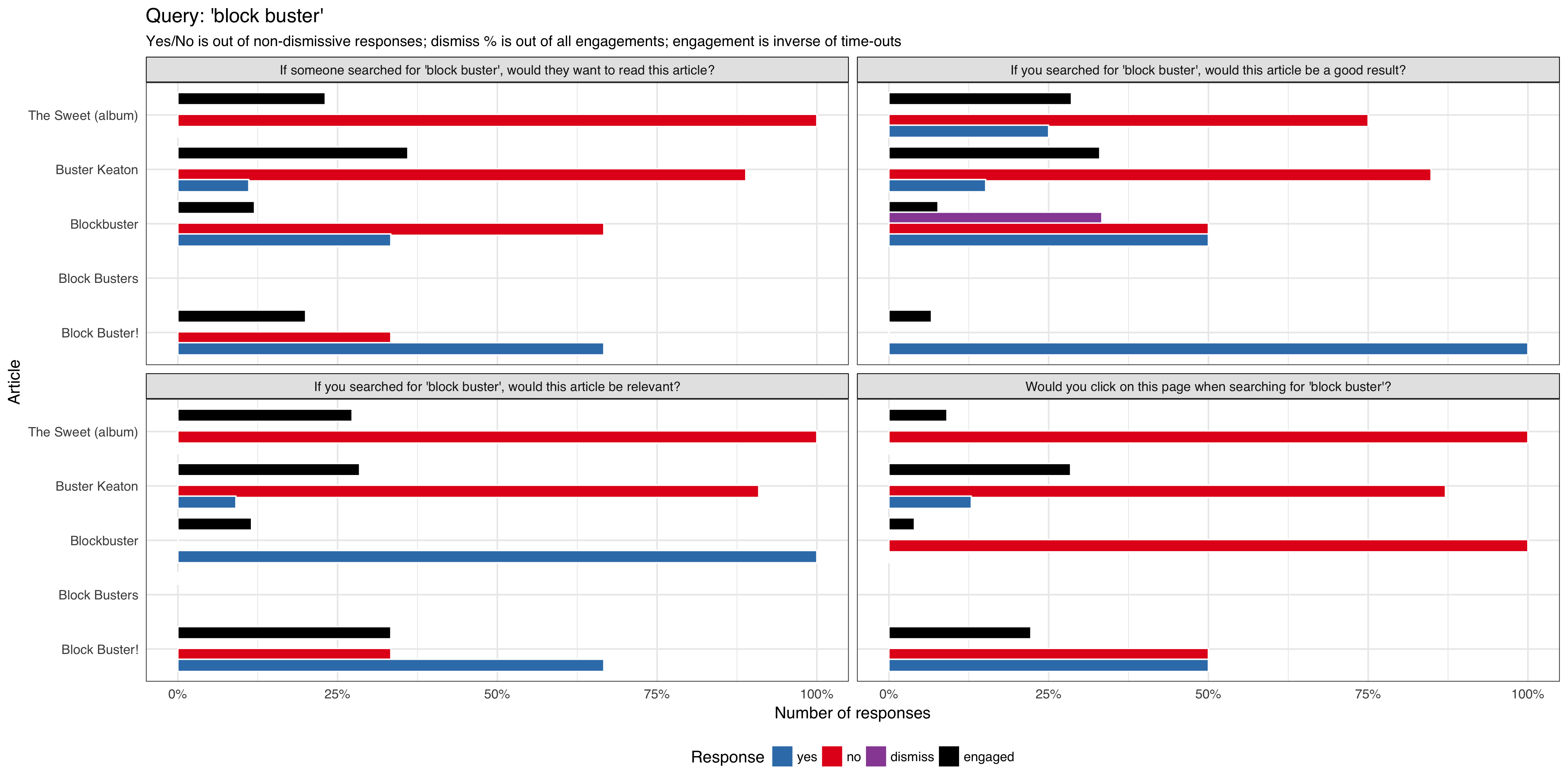
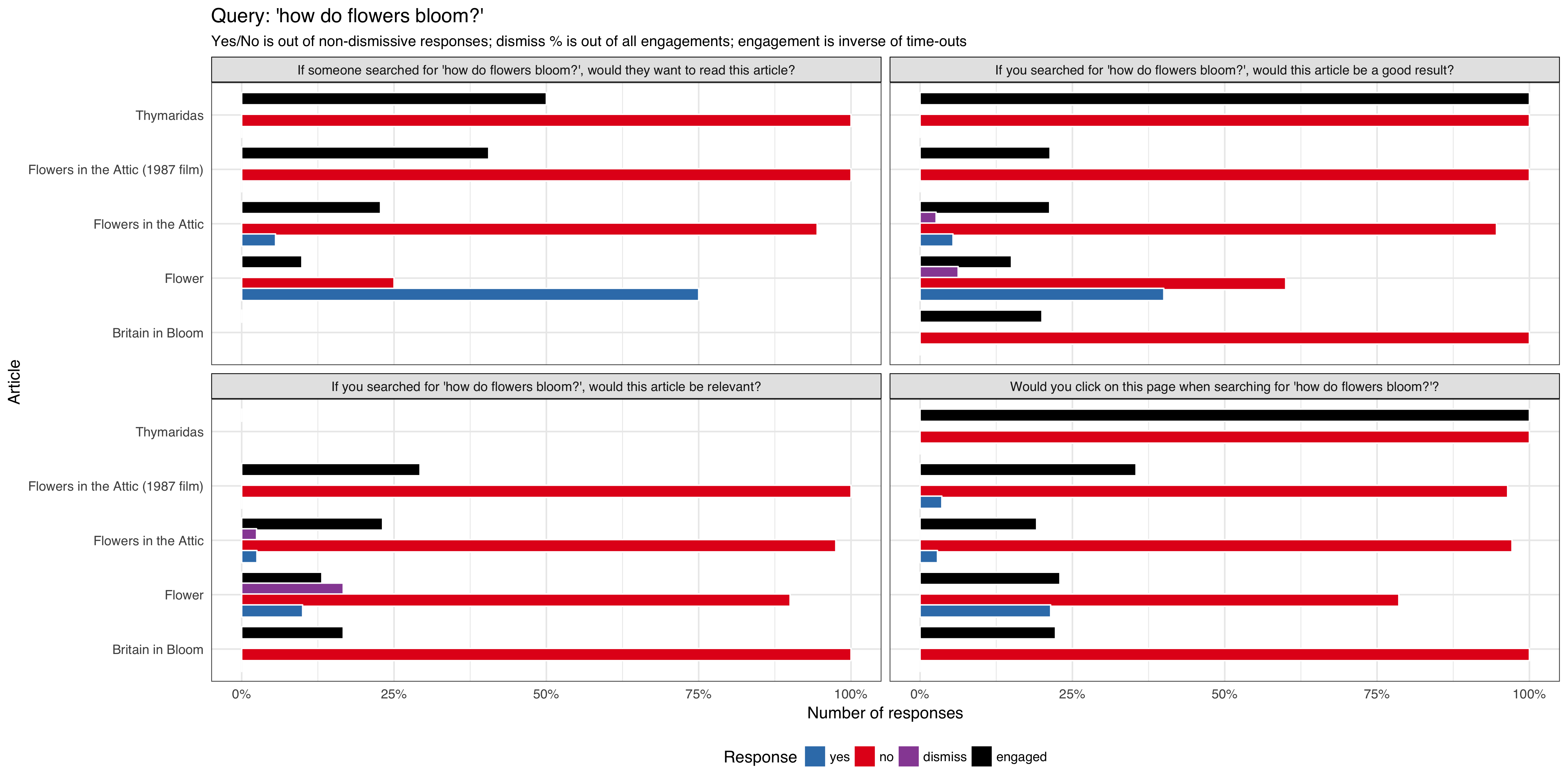
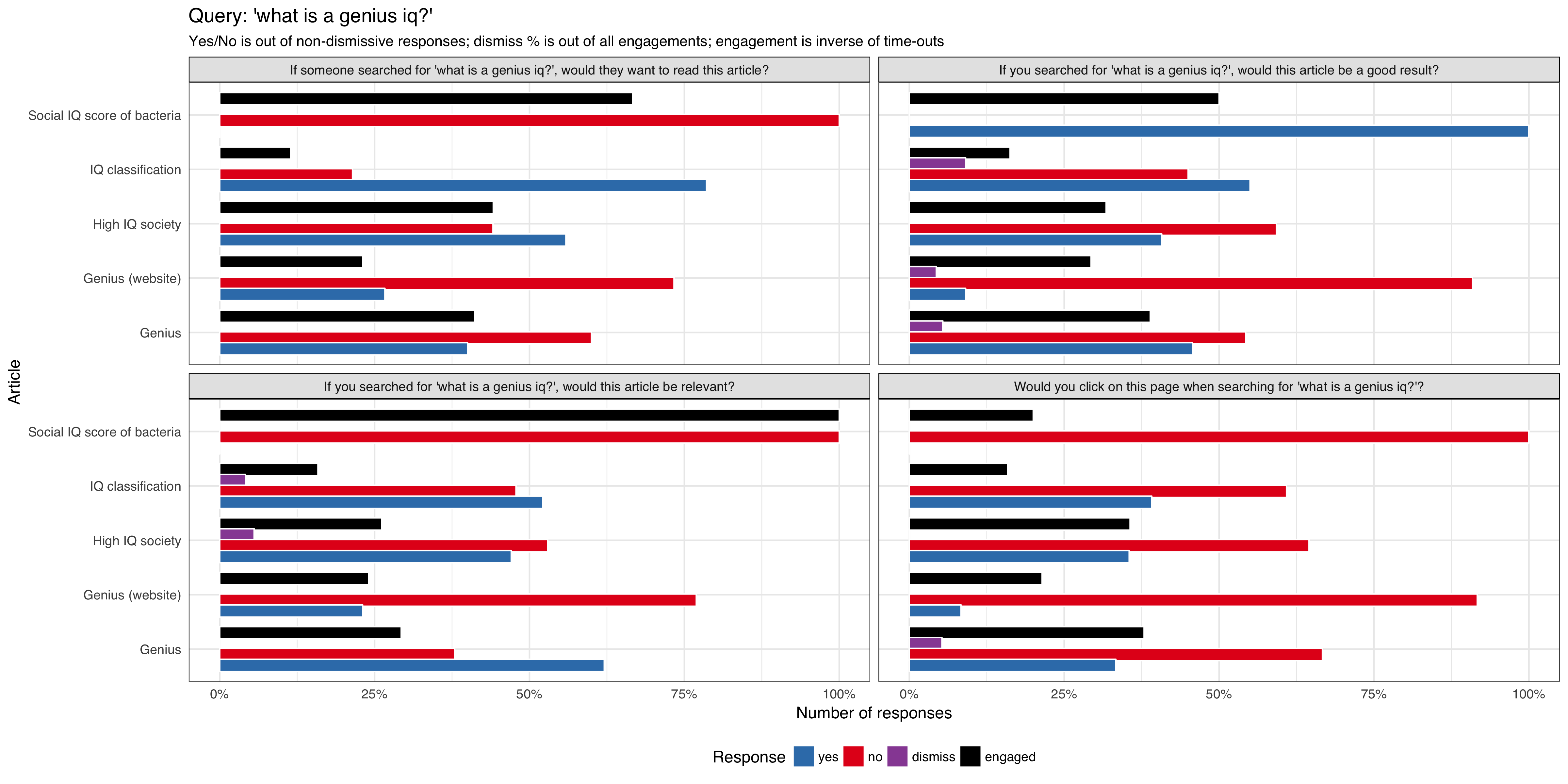
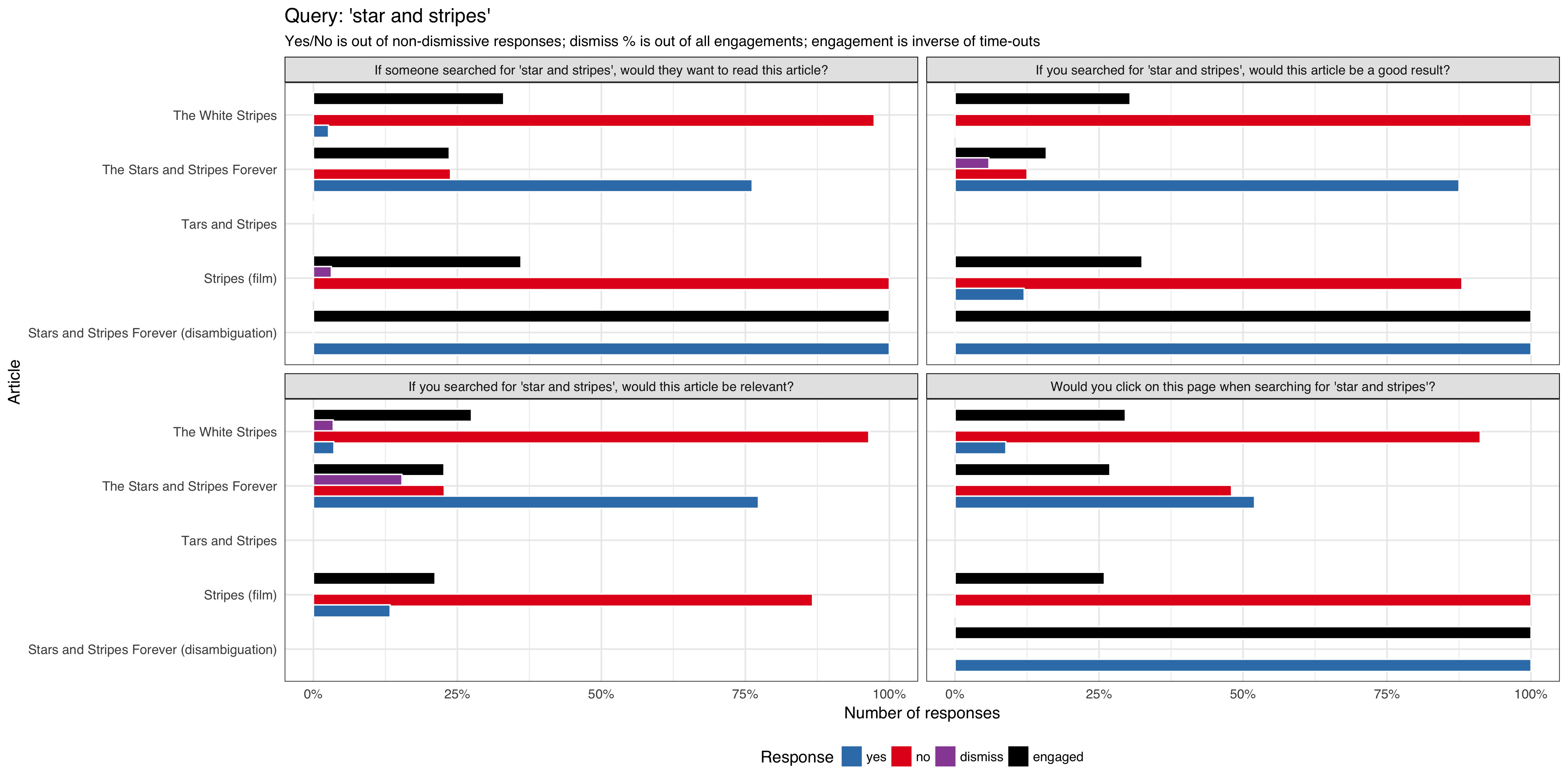
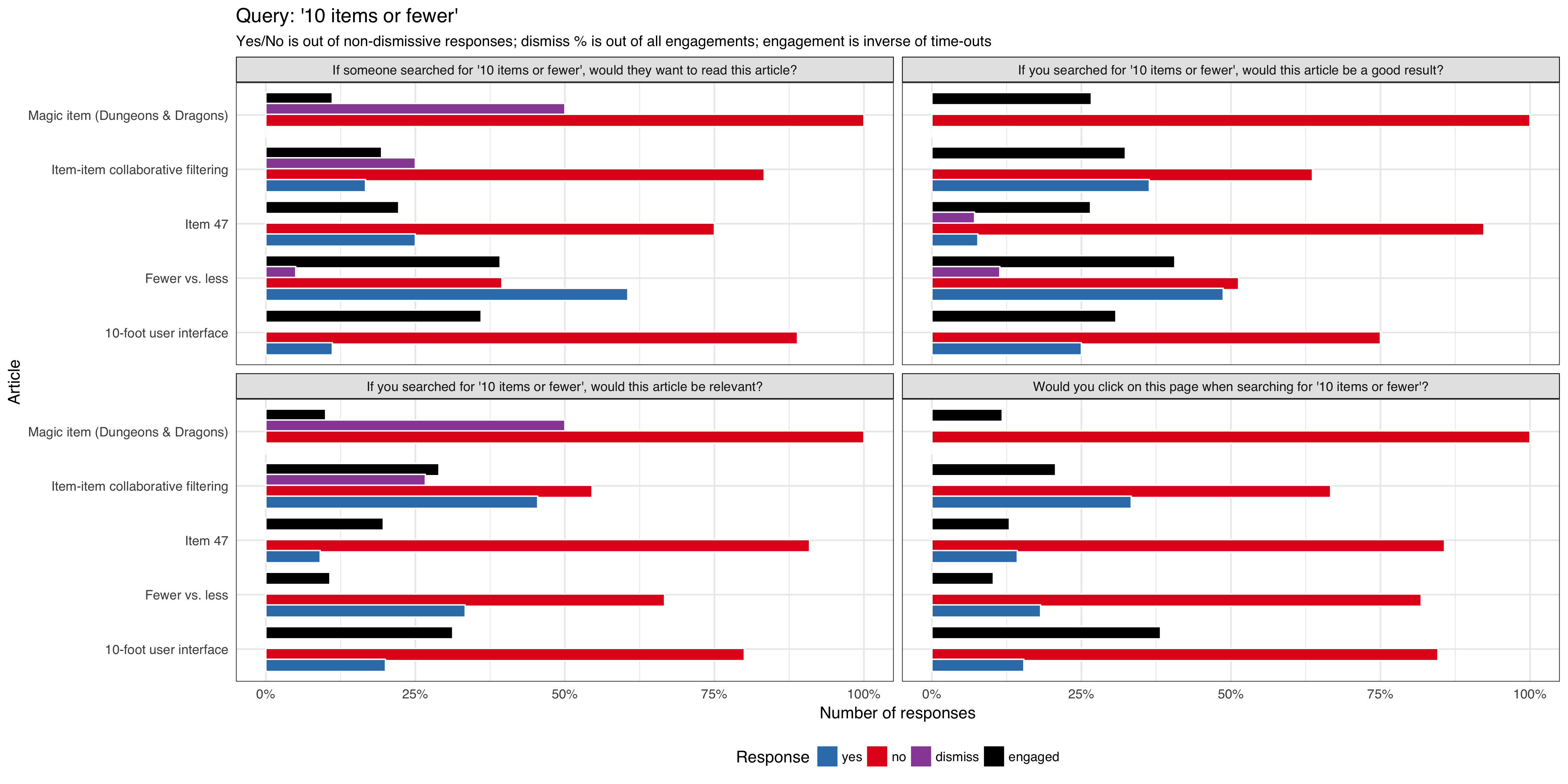
We want to do a series of tests requesting feedback from users that are viewing article pages after viewing a curated list of queries, to be tested on English Wikipedia and is expected to get approximately 1,000 impressions per week using the 'mediawiki.notification' function.
For our MVP (minimum viable product) test, we will be hard-coding a list of queries and articles into the code (using Javascript). This will allow for a small scale evaluation to see if this type of data is useful or if we receive just a bunch of 'noise' from the test.
Some of the initial hardcoded queries are (for MVP only):
- 'sailor soldier tinker spy'
- 'what is a genius iq?'
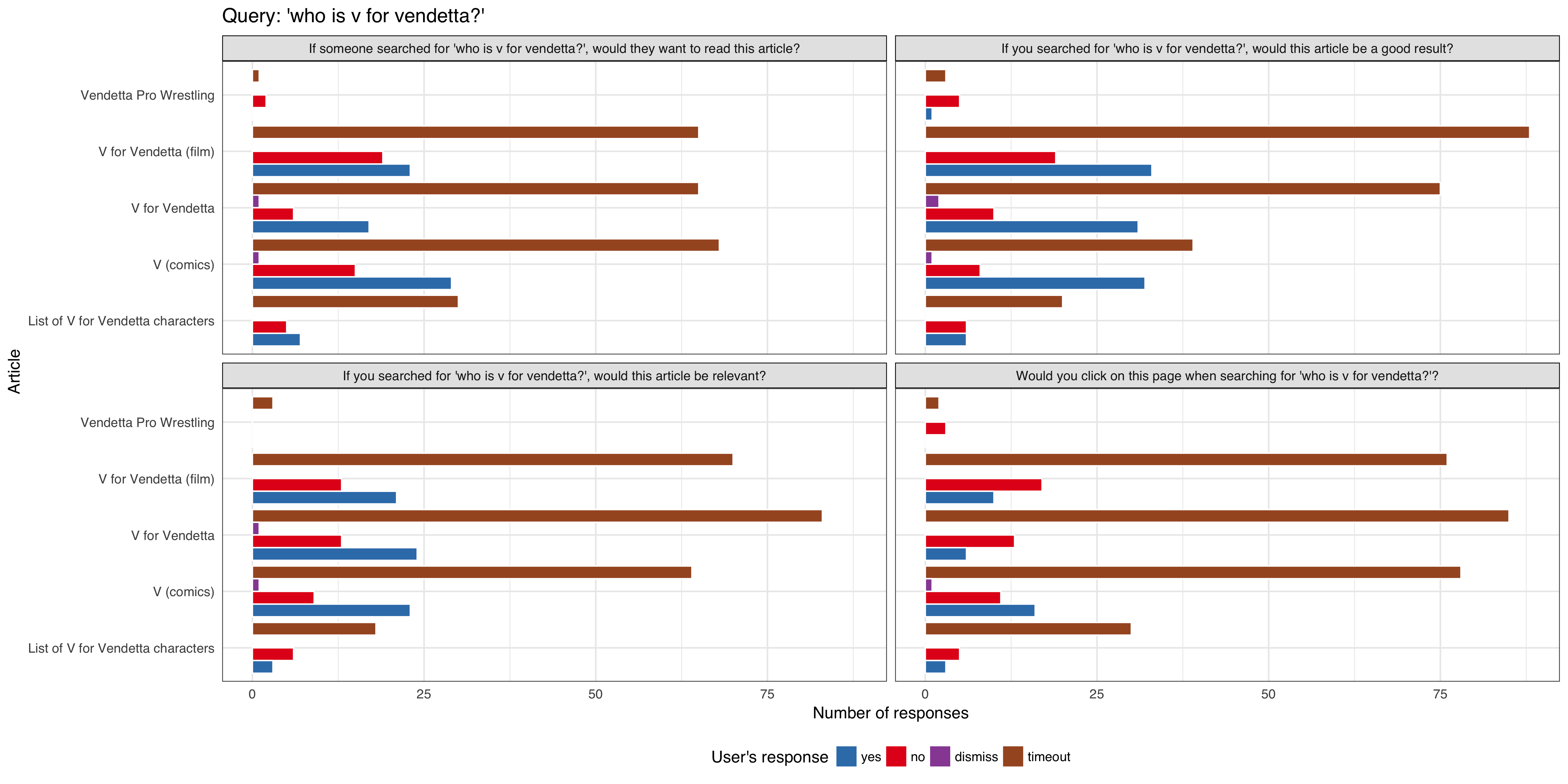
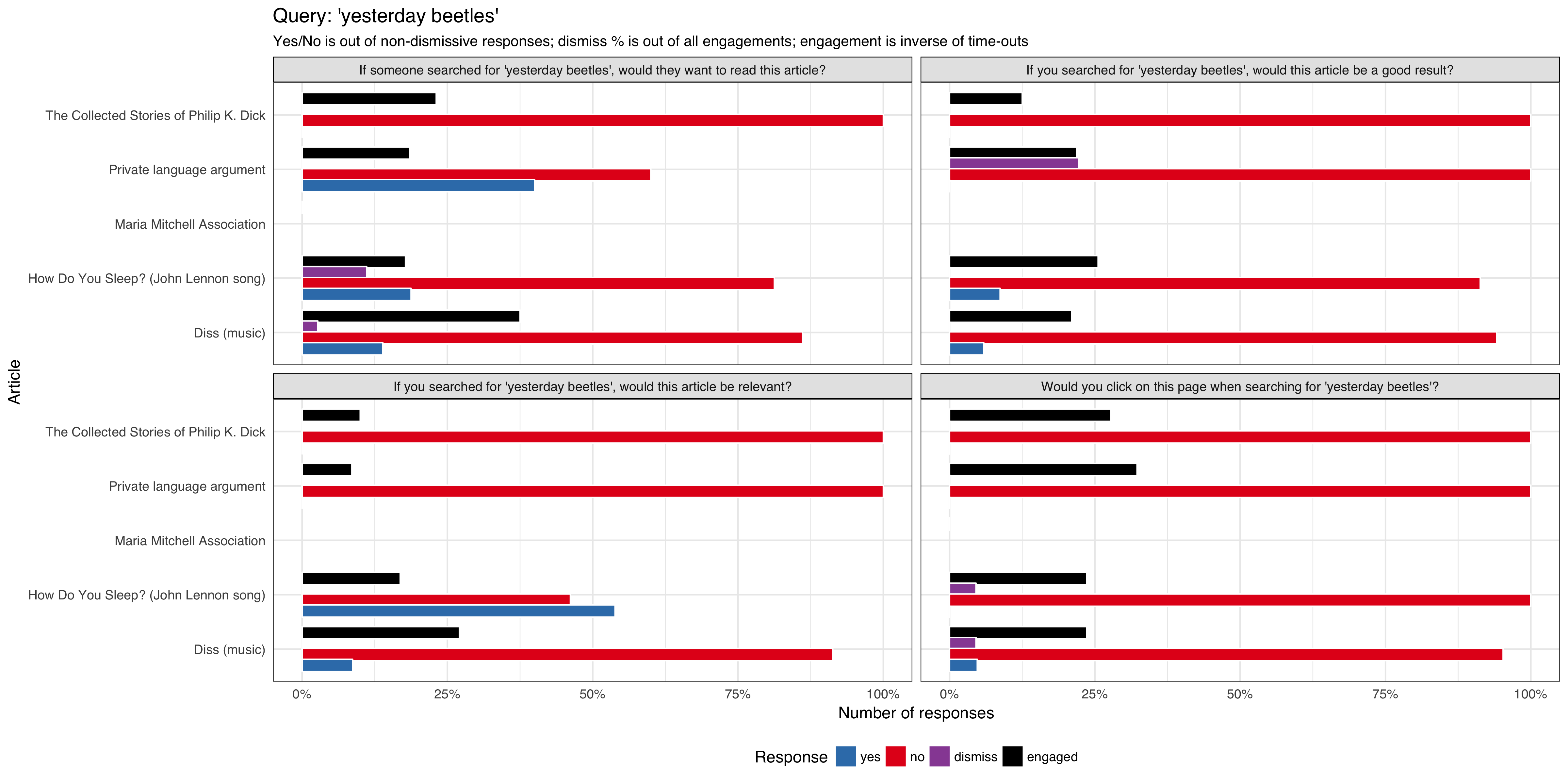
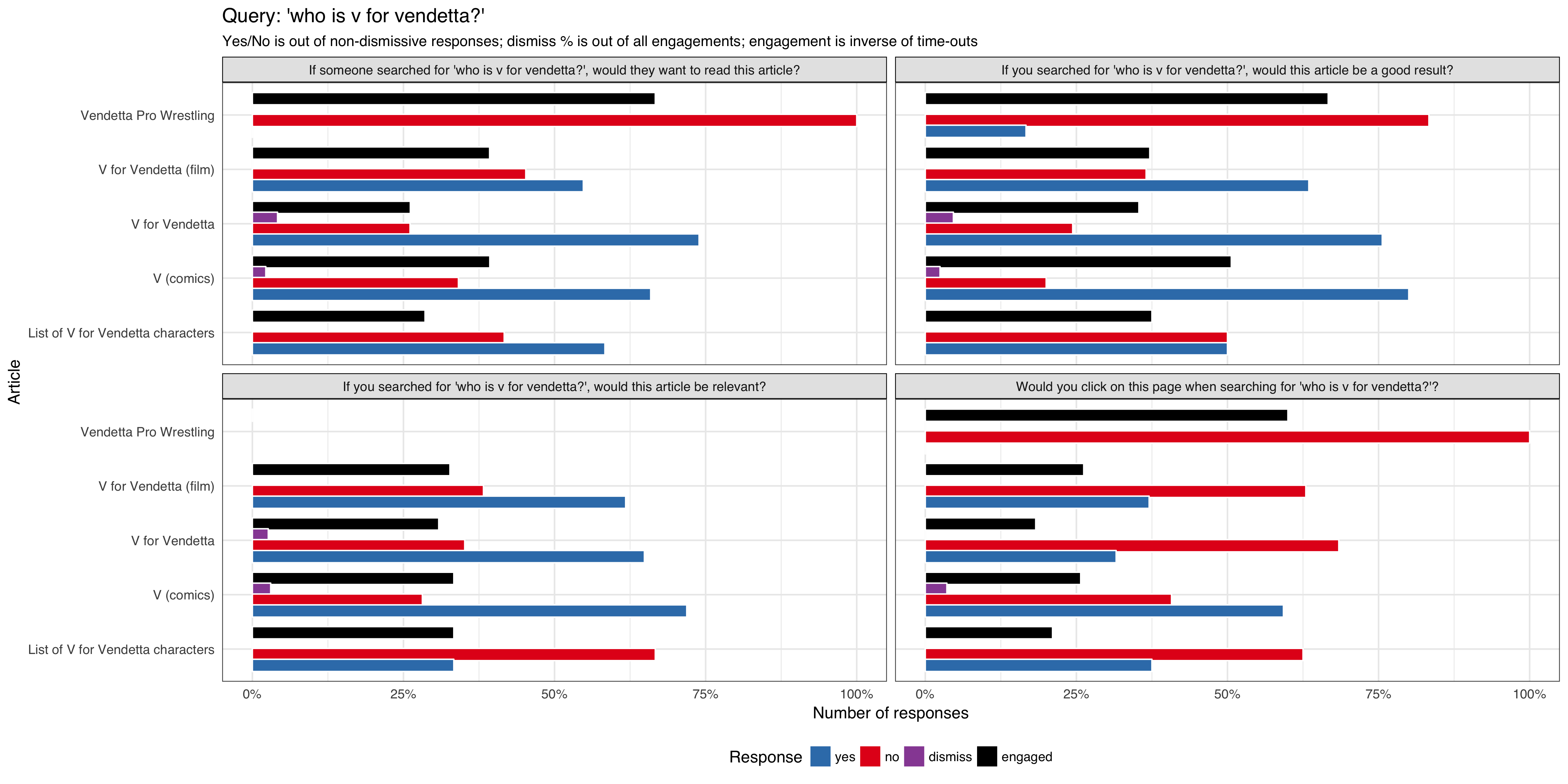
- 'who is v for vendetta?'
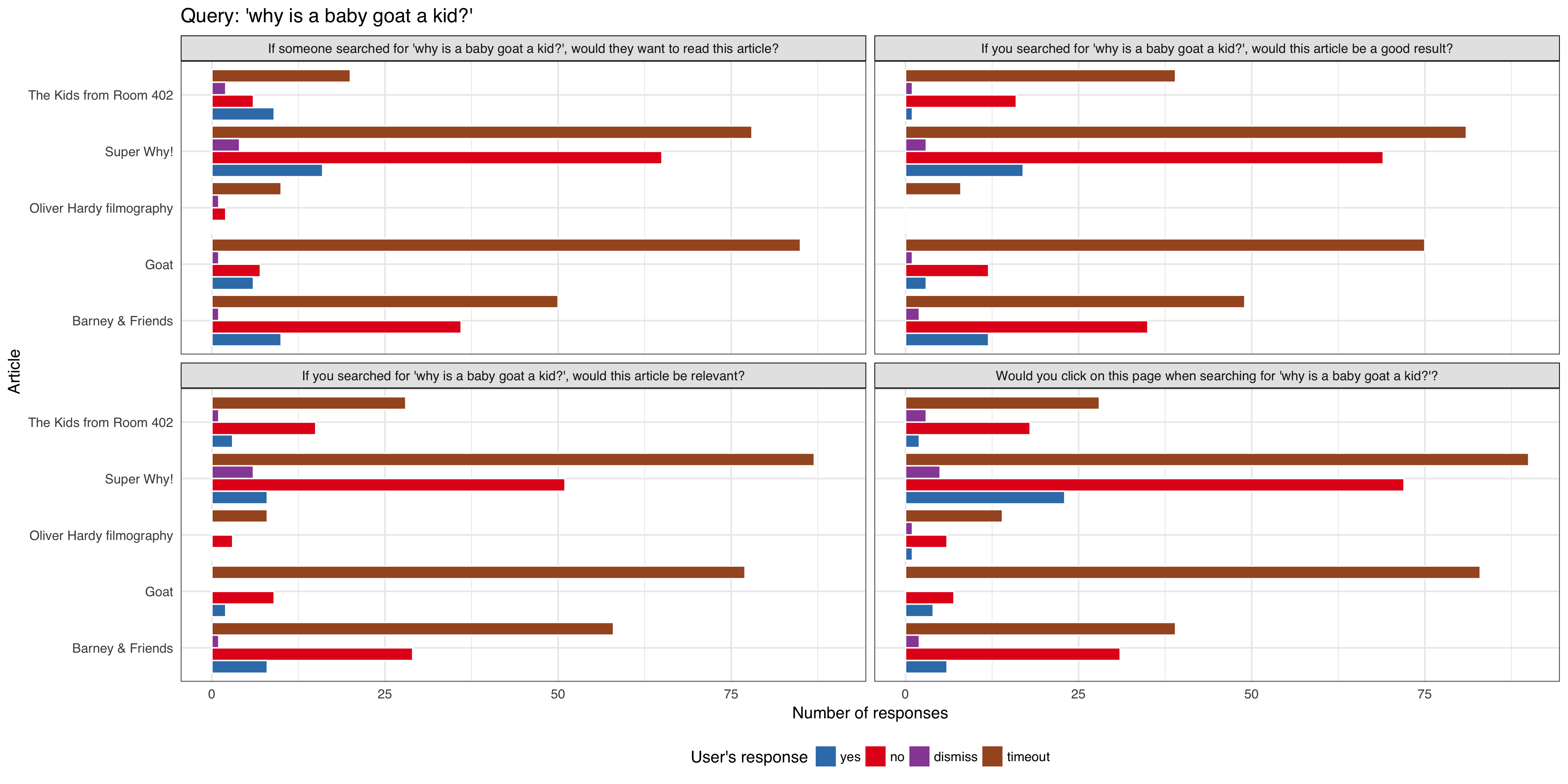
- 'why is a baby goat a kid?'
The test will contain:
- a link to the privacy policy: https://wikimediafoundation.org/wiki/Privacy_policy
- 3 selector buttons that a user can choose: yes, no, I don't know
- ability for the user to dismiss the notification/question
- ability for the user to scroll and the notification/question box does not impede reading of the article
- an auto-timeout to dismiss the notification/question box automatically
- the ability to only select one option before the notification/question box is dismissed
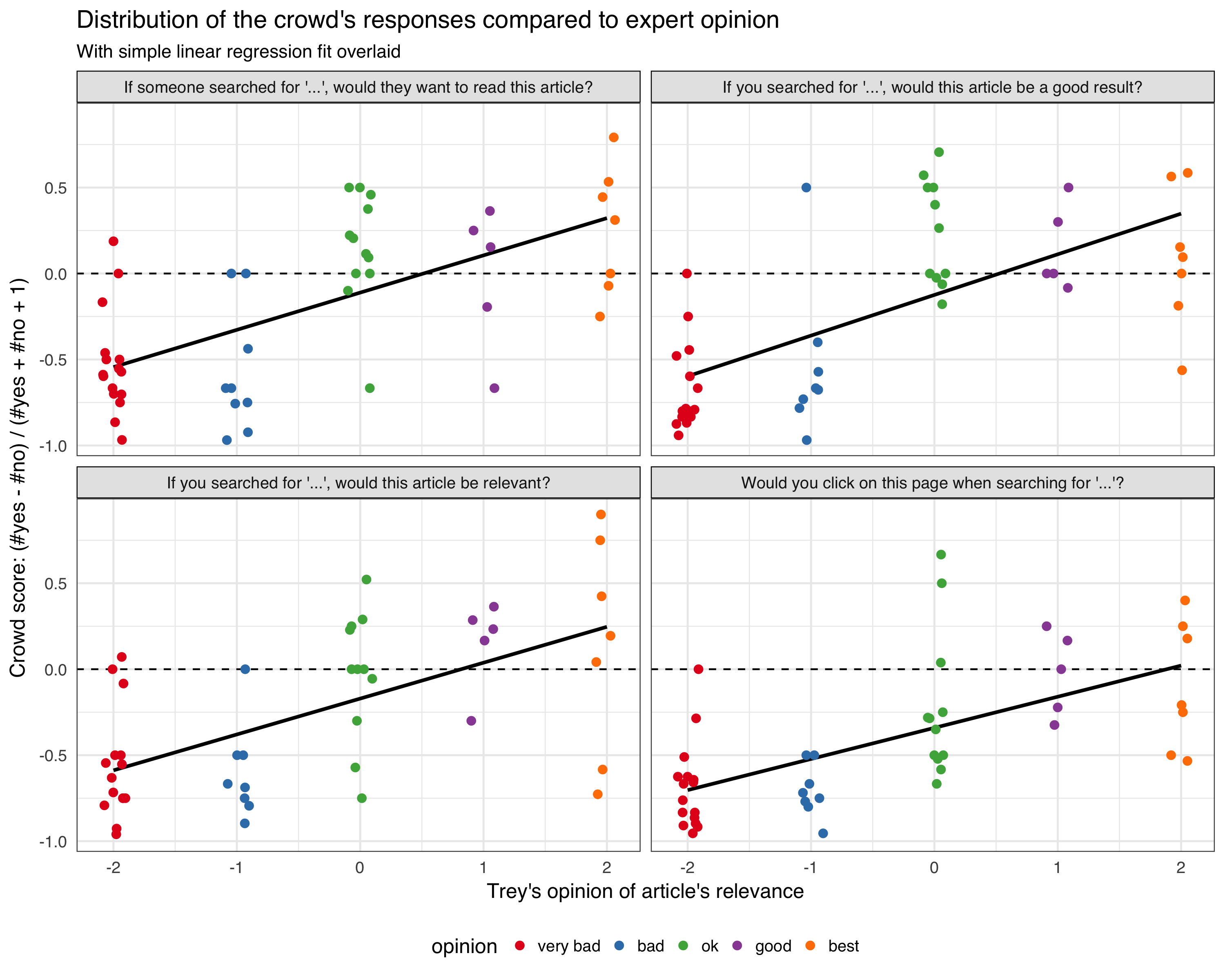
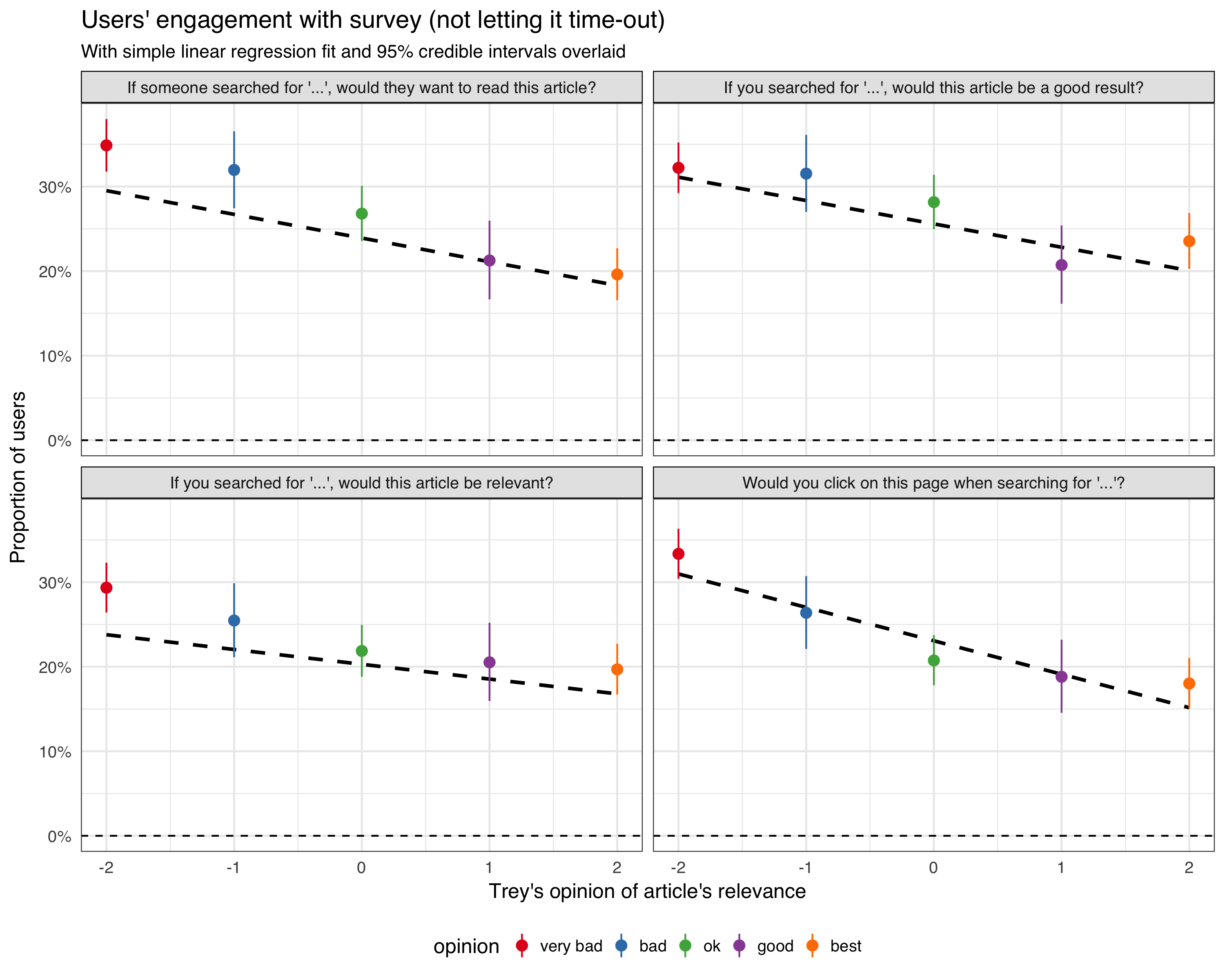
We will track:
- what option the user selected
- if the notification/question box get dismissed by the user
- if the notification/question box get dismissed automatically (it's session timed out without any interaction from the user)
Additional test options to consider:
- should we embed the desired queries into cached page render
- should we use a graphic (smiley face, frowny face, unsure face) instead of the yes/no/not sure text
- should we test on other language wiki's
- would require translating all text
First draft of notification/question box:
Sample smiley face option that could be used in a future test to avoid 'wall of text':