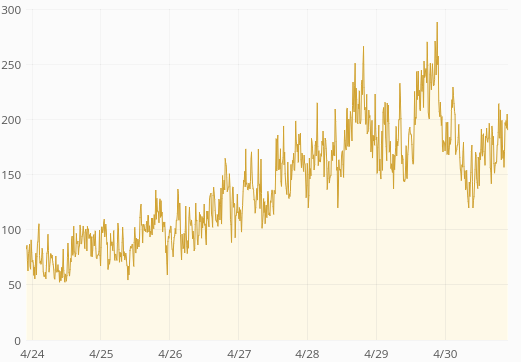
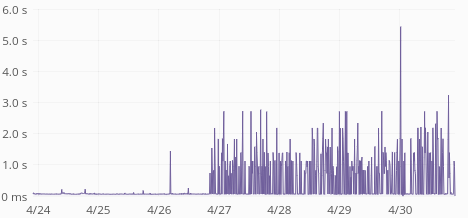
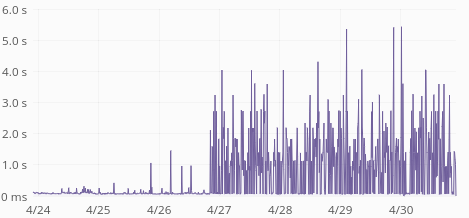
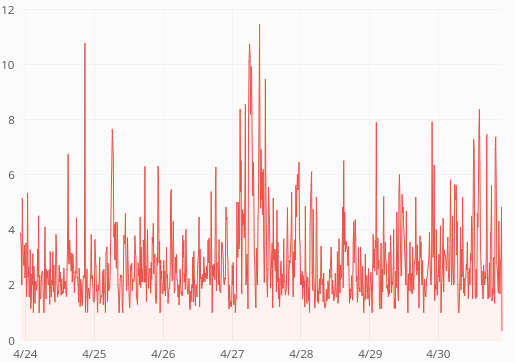
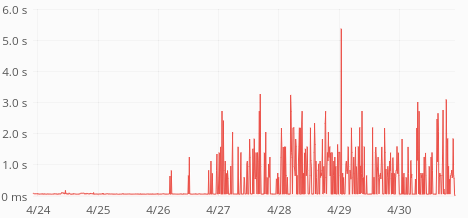
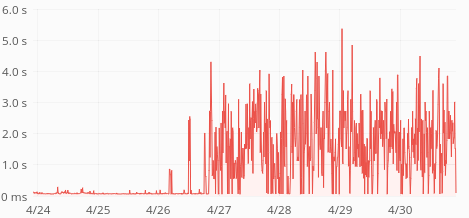
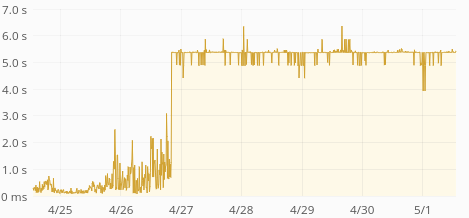
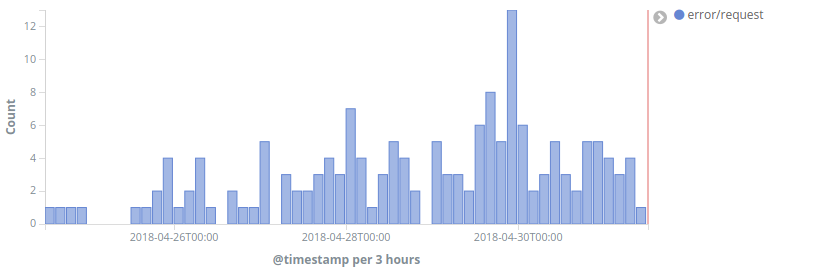
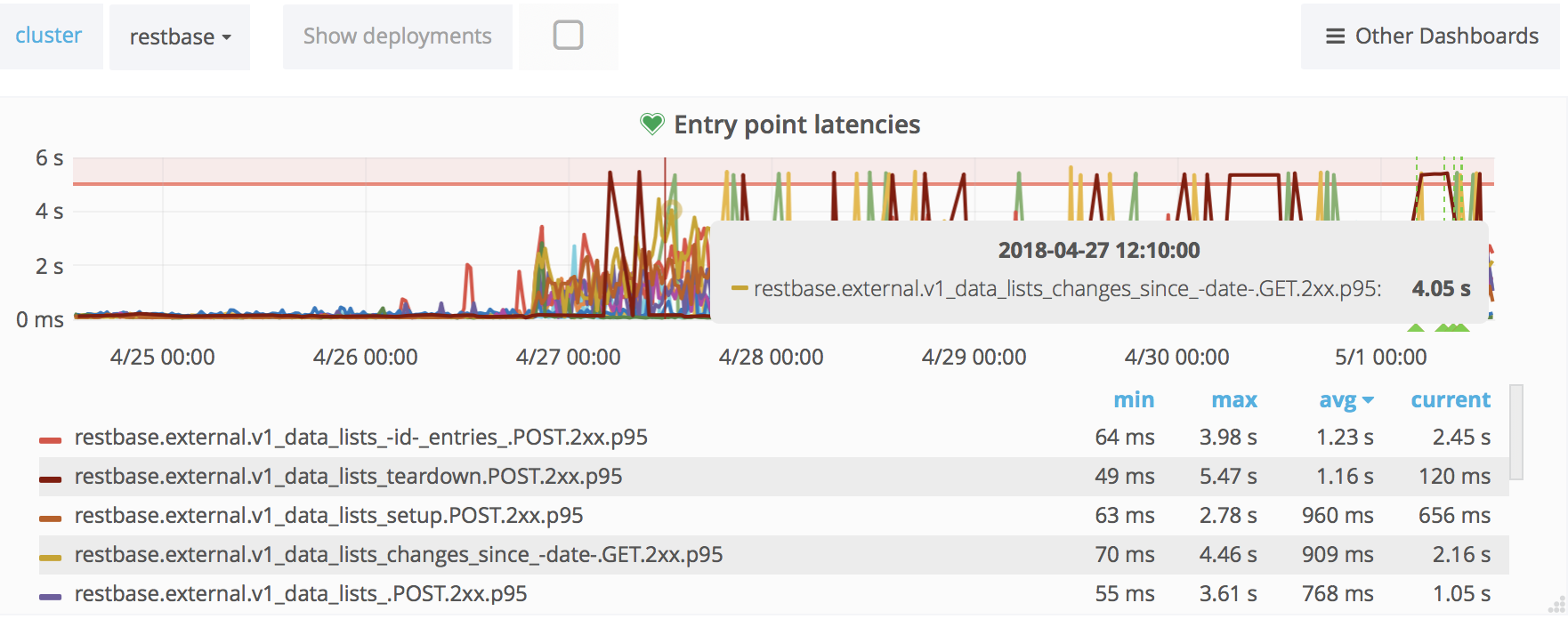
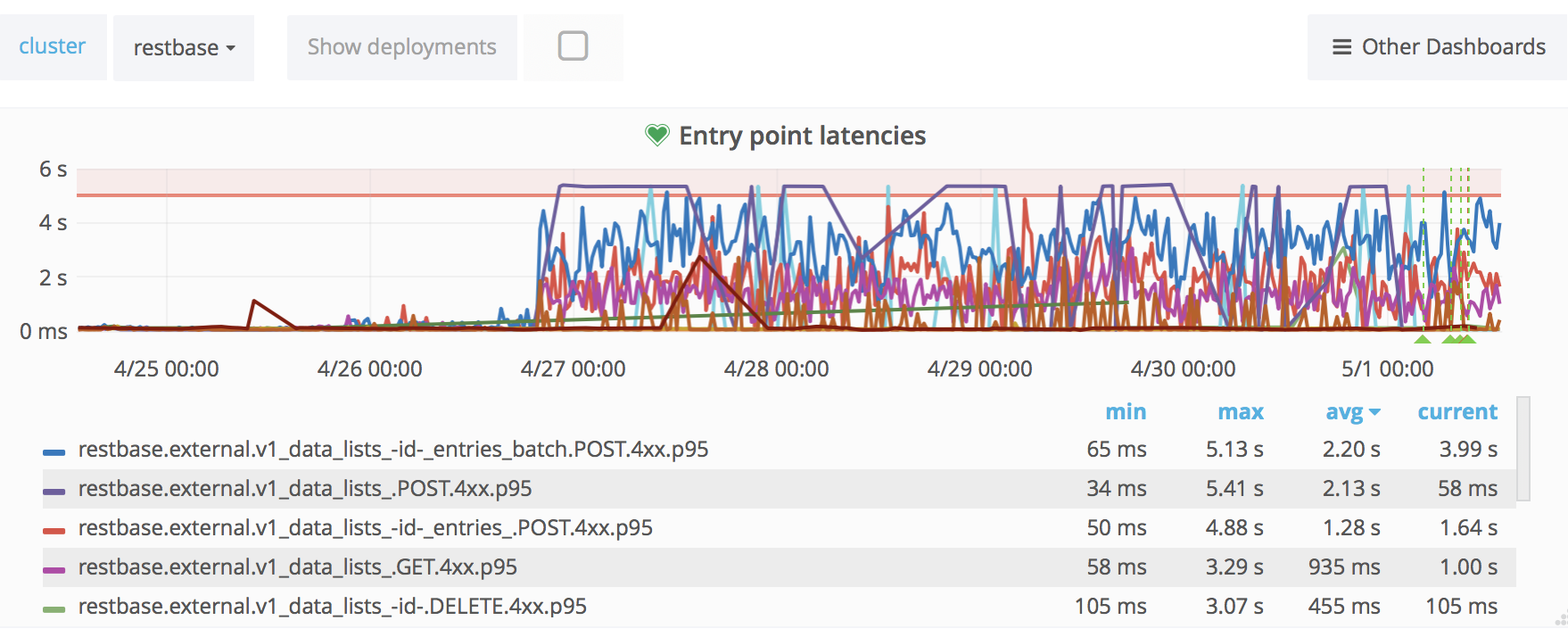
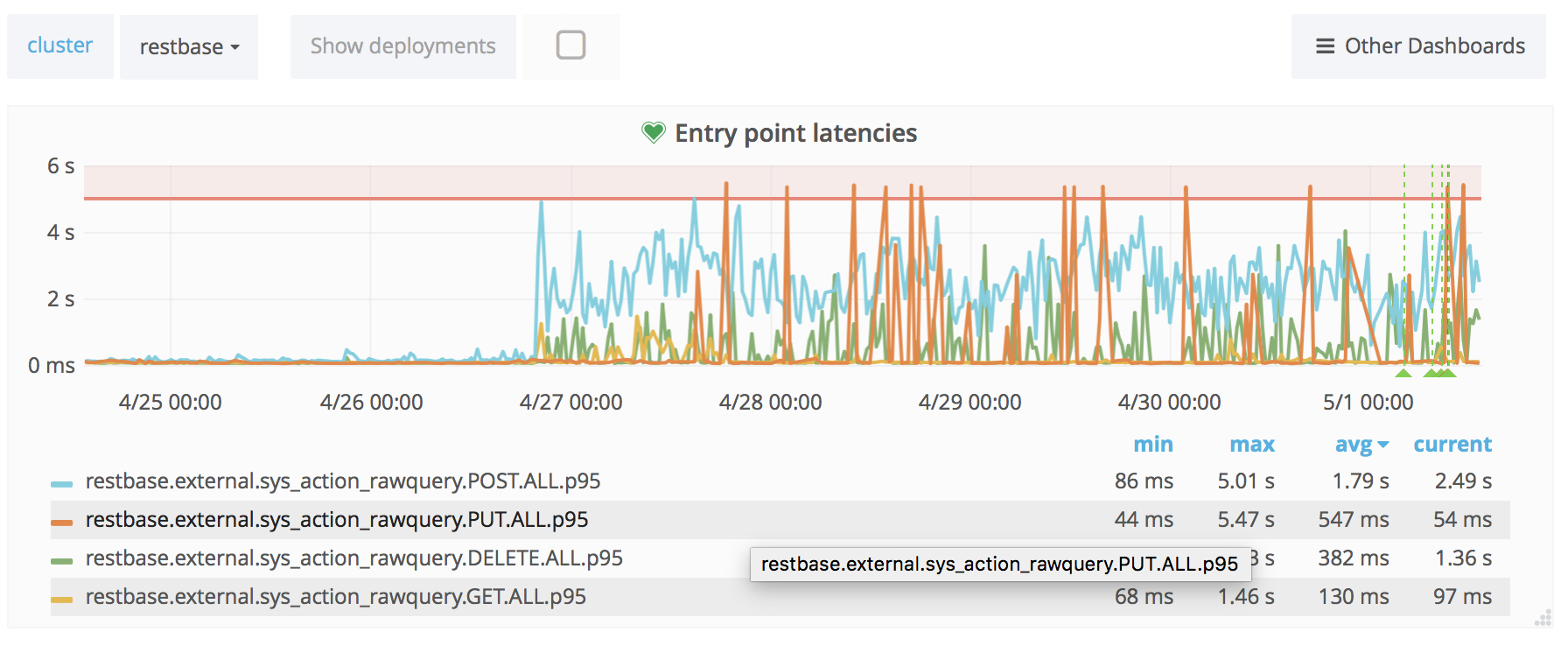
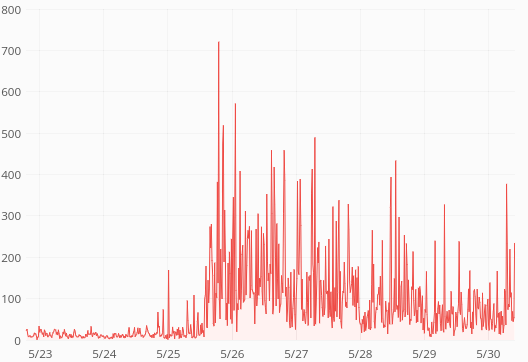
ReadingLists API response times have skyrocketed last week:
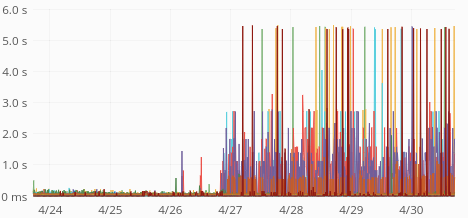
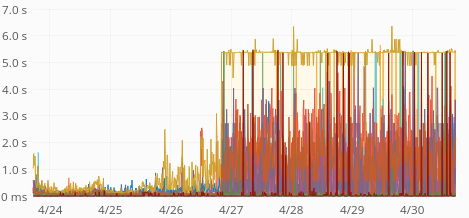
| median | p99 |
 |  |
https://grafana.wikimedia.org/dashboard/db/reading-list-service
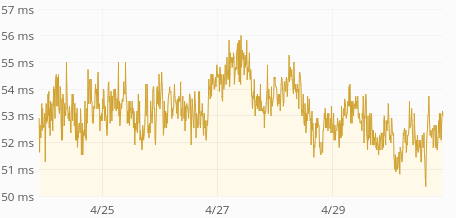
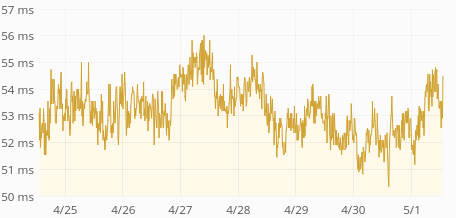
Average response time is up from 60ms to 400ms. p75 is up from 80ms to 1s. p95 is up from 250ms to 3.5s. p99 is up from 0.5s to 5s. Median is unchanged (around 50ms) so this only affects 30-40% of the requests.
The jump coincides with the MW train deploy:

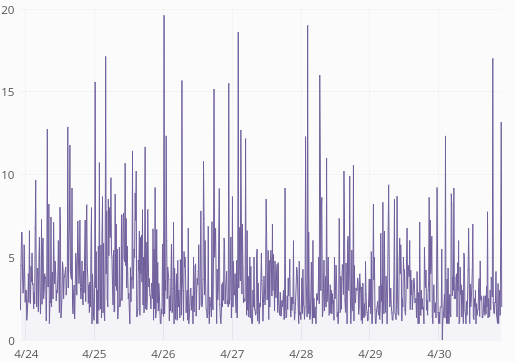
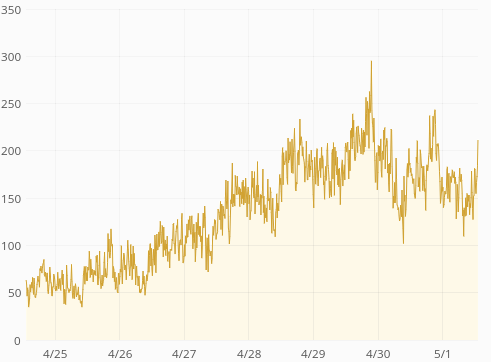
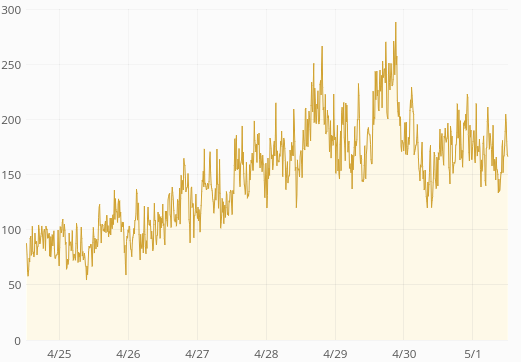
There was traffic growth during the period but not nearly so abrupt as the response time change (and the traffic comes from mobile apps so traffic patterns are not affected by the train).
Action API logs claim almost all request finish well under 50ms, but might be inaccurate due to T193484: API request time logs should happen after DB commit.
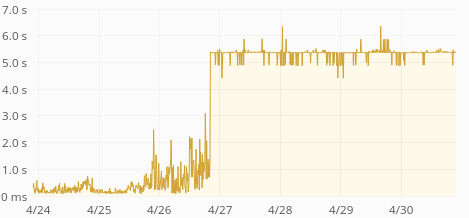
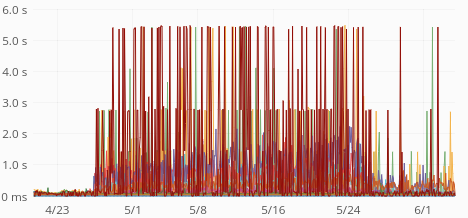
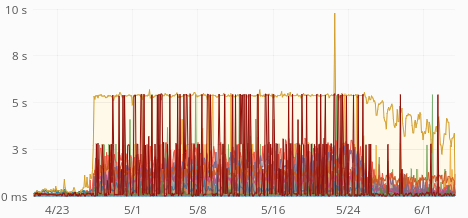
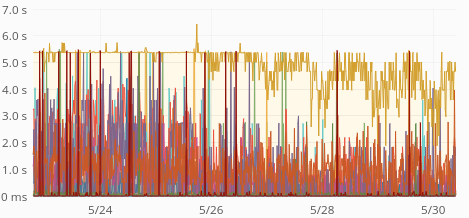
The time increase seems to be happening in increments of 500ms, with a ceiling of 5s:
| GET request times, p75 | GET request times, p95 |
 | 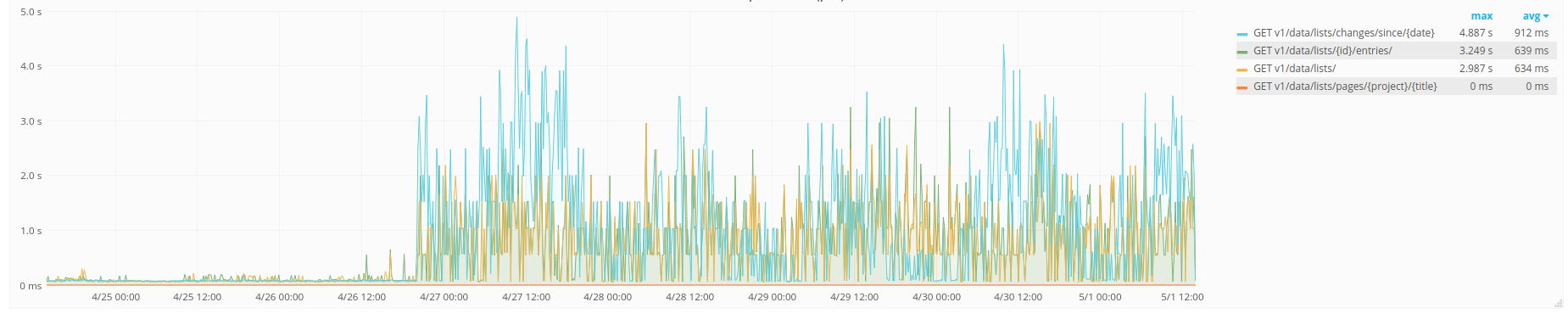 |
That suggest some operation times out and is retried 10 times. There are no timeout (or other) errors though and none of the requests seem to be failing.