There's a few jenkins slaves down at the moment, due to I believe one or two cloudvirt hosts being down. Among others integration-castor03 is down, which seems to be causing all jobs depending on castor-save-workspace-cache to be waiting indefinitely.
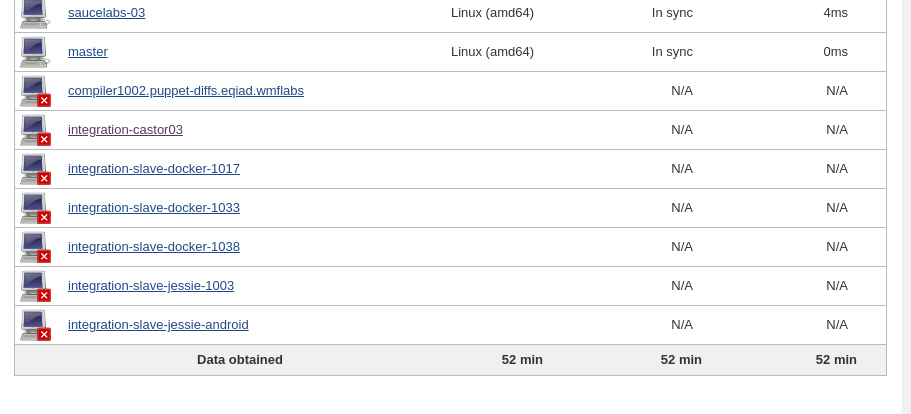
See also: https://integration.wikimedia.org/ci/job/castor-save-workspace-cache/ and https://integration.wikimedia.org/ci/computer/