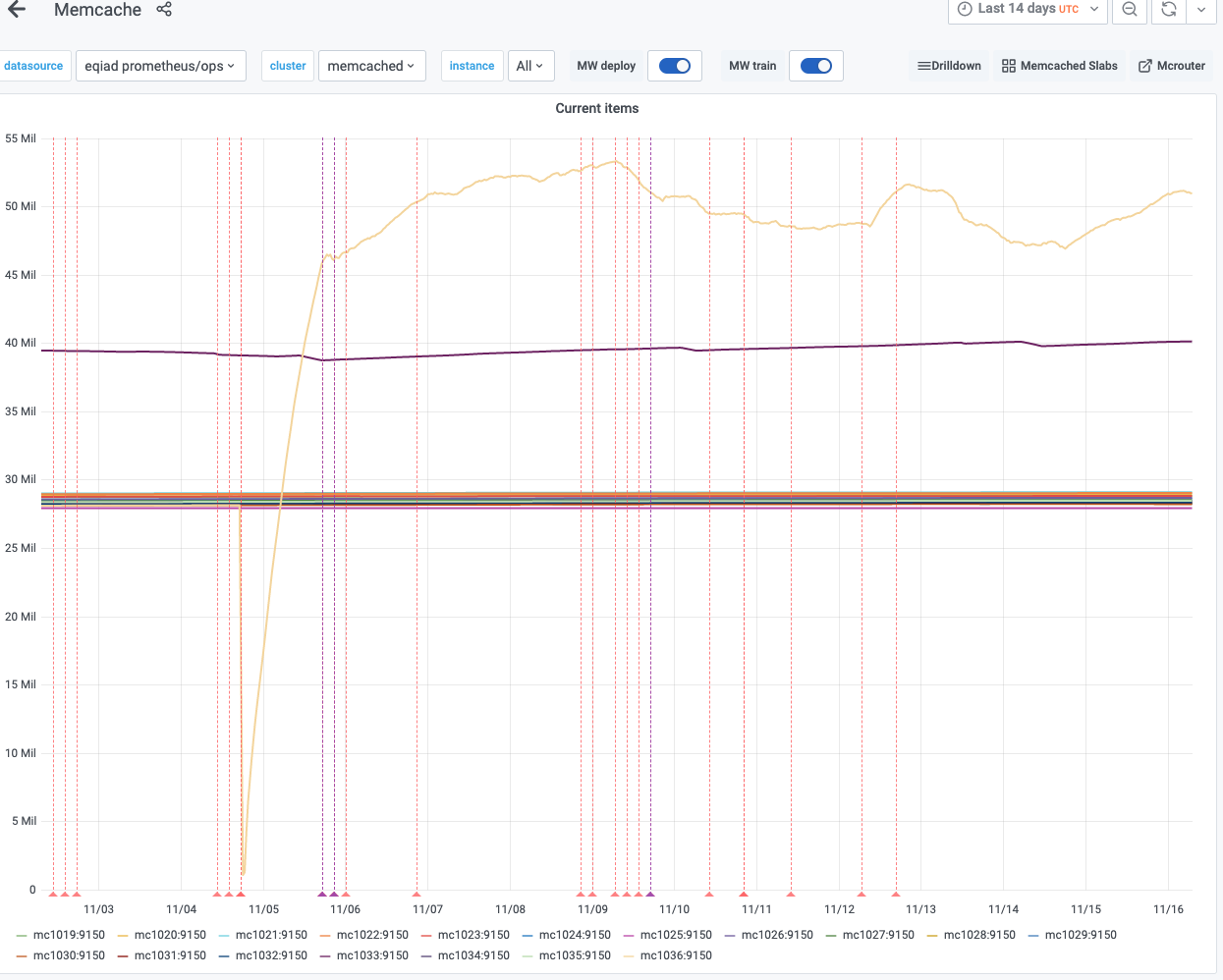
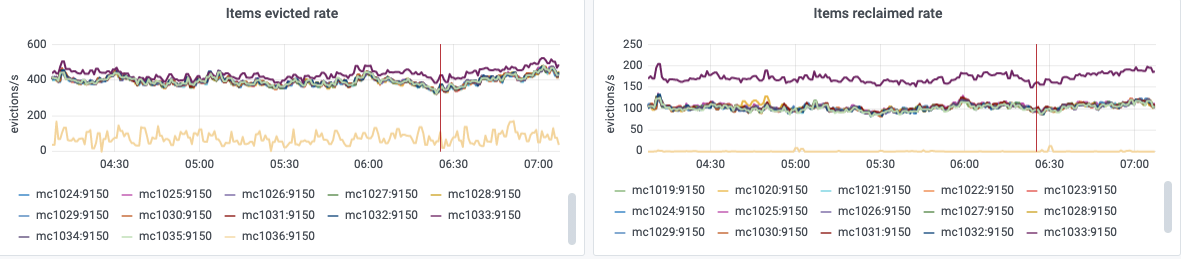
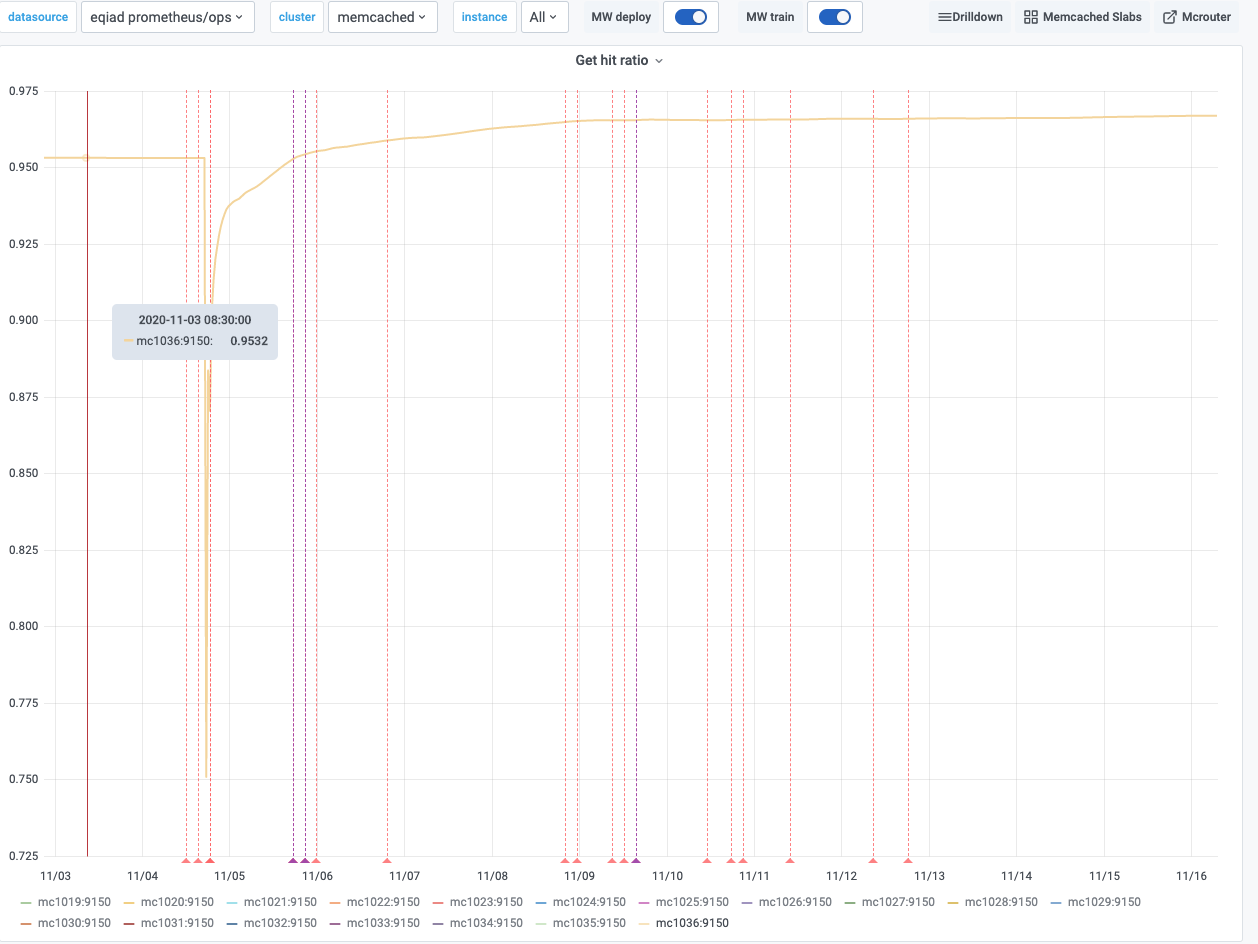
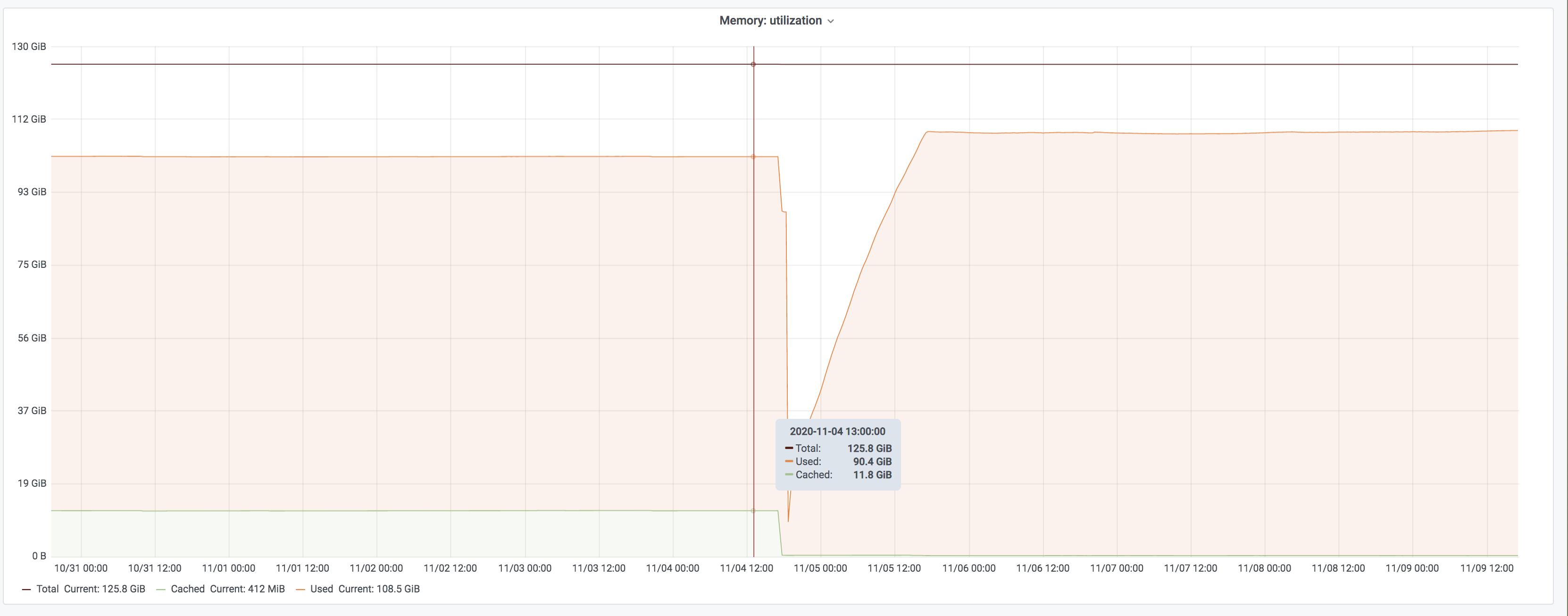
Given T251378 and T213089, I'd propose to move one memcached shard to Buster. The goal is to verify and test with production traffic that the configuration for Buster works as expected. There has been a lot of testing in the past, but I am pretty sure that some tuning will be needed for our production mc* hosts. The idea is to work on one shard for the moment, and then upgrade all the others when we'll be in a good state.
During the reimaging of the server, the mcrouter instances running on all mediawiki servers, will fall back to the gutter pull servers. The production impact will be basically the same as if we were simply restarting a memcached server.
Due to switchover on the 27th, we will reimage a server by the 30th Oct.
Redis
One of our concern is what we happen with the Redis server running on the newly reimaged buster host. Our options are:
- Remove a redis shard, and do not install Redis on those hosts <-- this is what we are going with now.
- mc1036
- mc2036
Remove this host from the pool -> requires restarting nucracker across all mediawiki hosts, which in turn will have some user impactInstall Redis 5.0 -> preferred solution as this is the default version in buster- Install Redis 2.8 -> we need to repackage this for buster, version we are currently running.
- mc1034
- mc2034
Memcached
- There will be loss of EditorJourney data if a memcached shard becomes unavailable