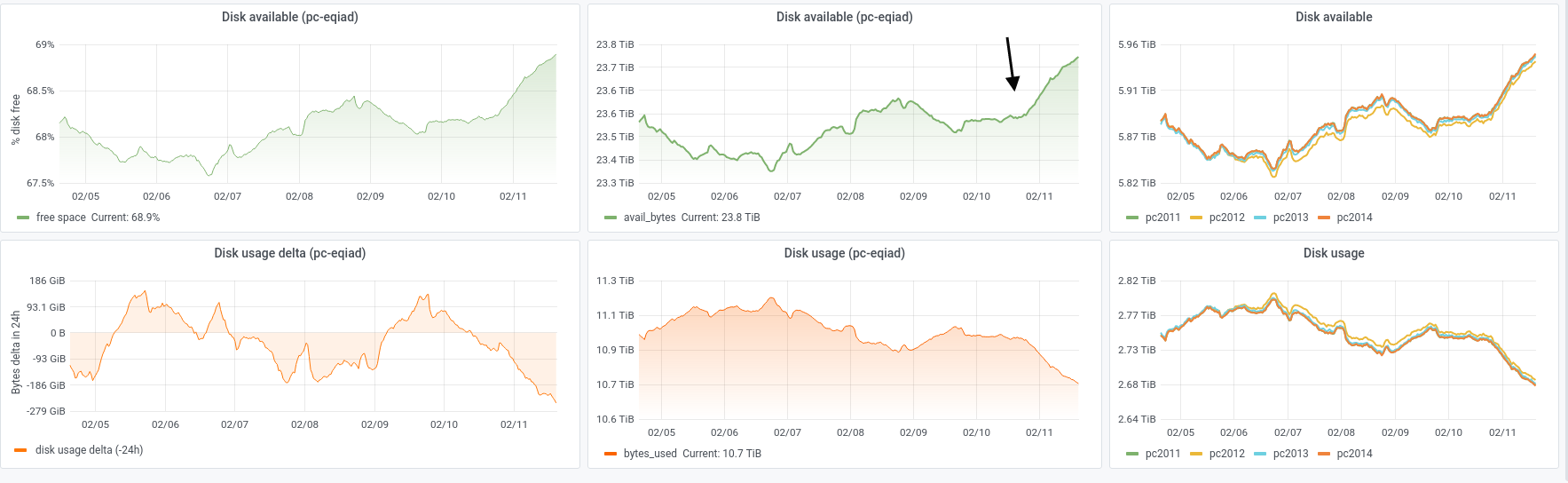
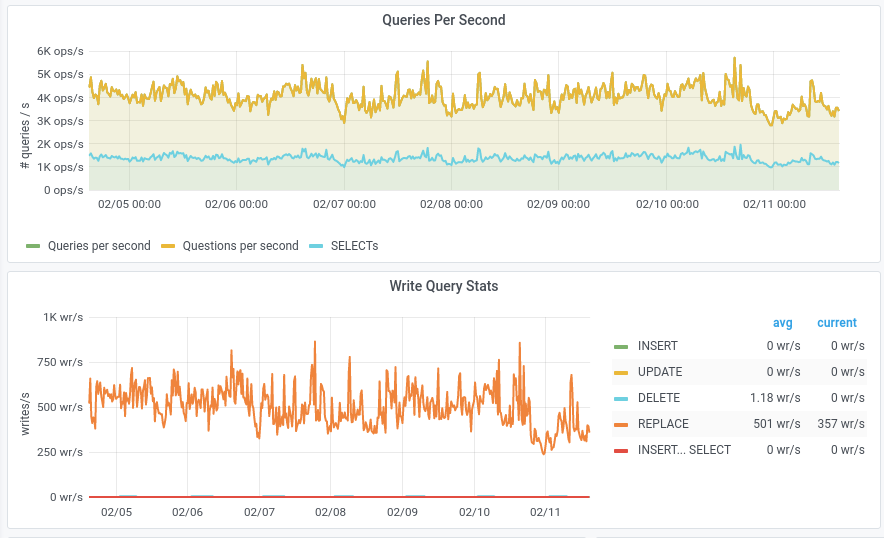
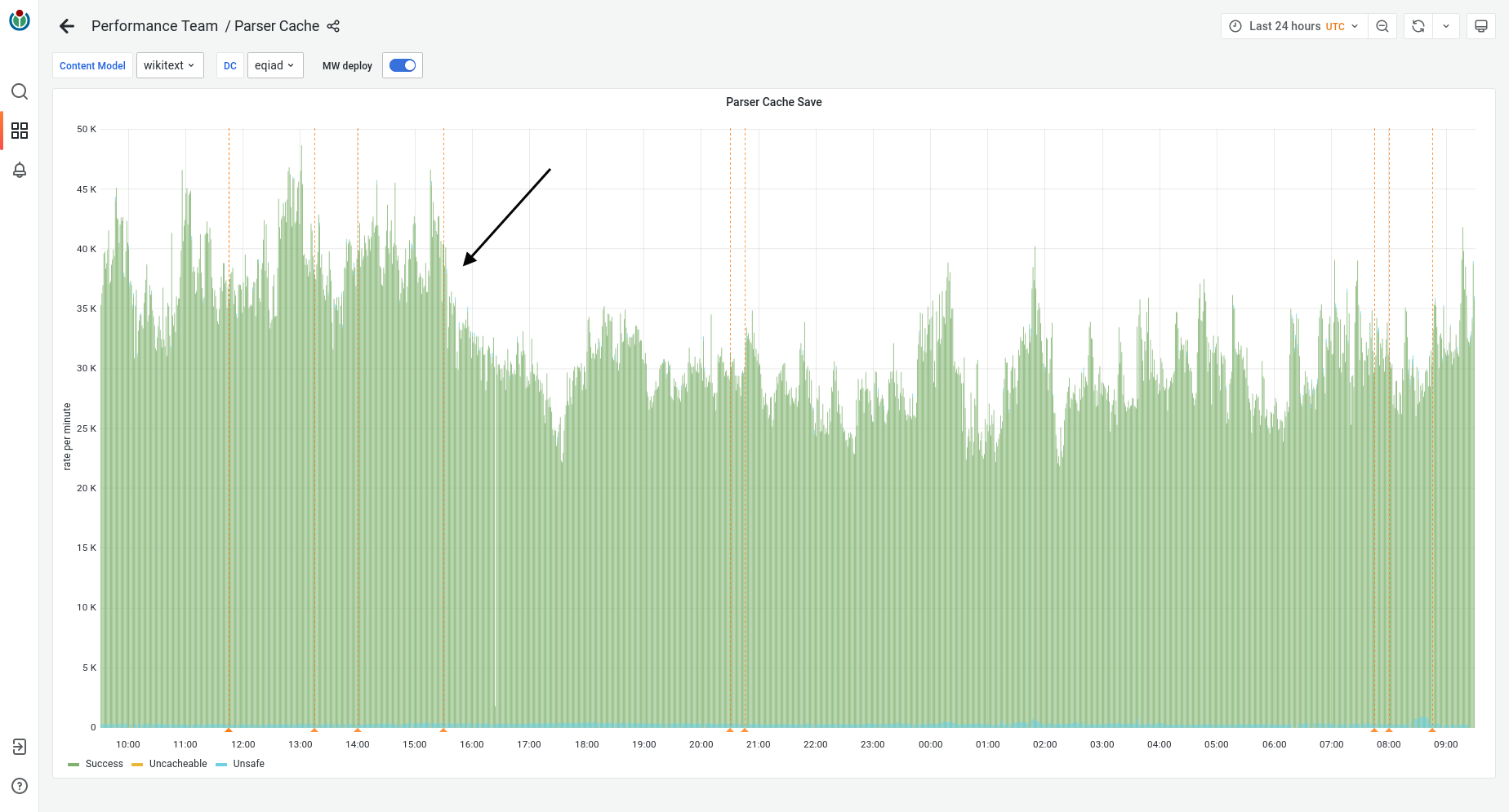
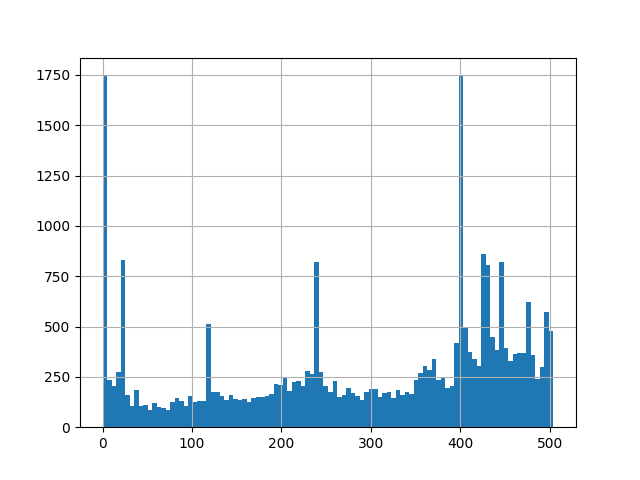
This task represents the work with estimating how the demand for Parser Cache storage could change over time.
The need for such an estimate emerged in the 1 July 2021 meeting between the Editing, Data Persistence, Performance, and Parsing Teams.
Open question(s)
- 1. How do we estimate the storage demand being placed on the parser cache will change over time? Note: the changes in said "storage demands" will be driven by parameters edit rate, data retention time, etc.
Done
- Answers to all ===Open question(s) are documented within this task's description