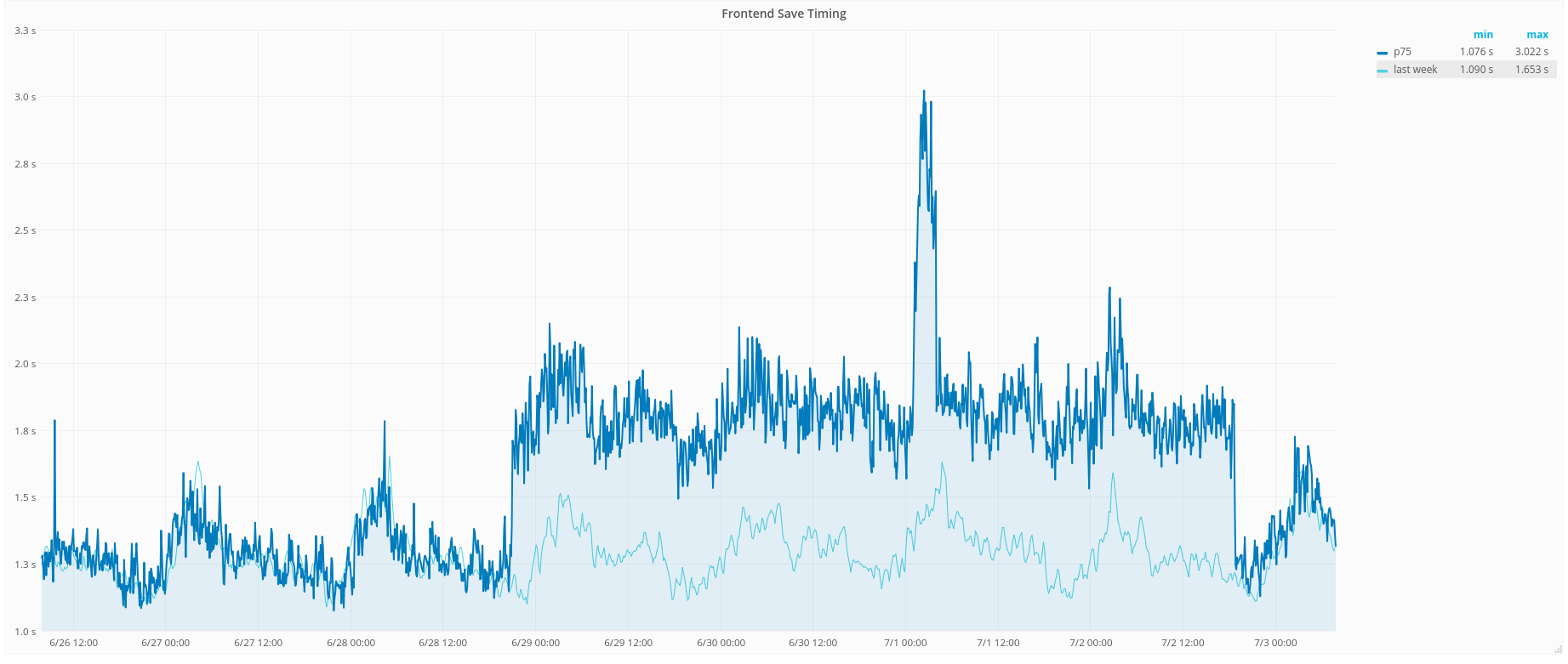
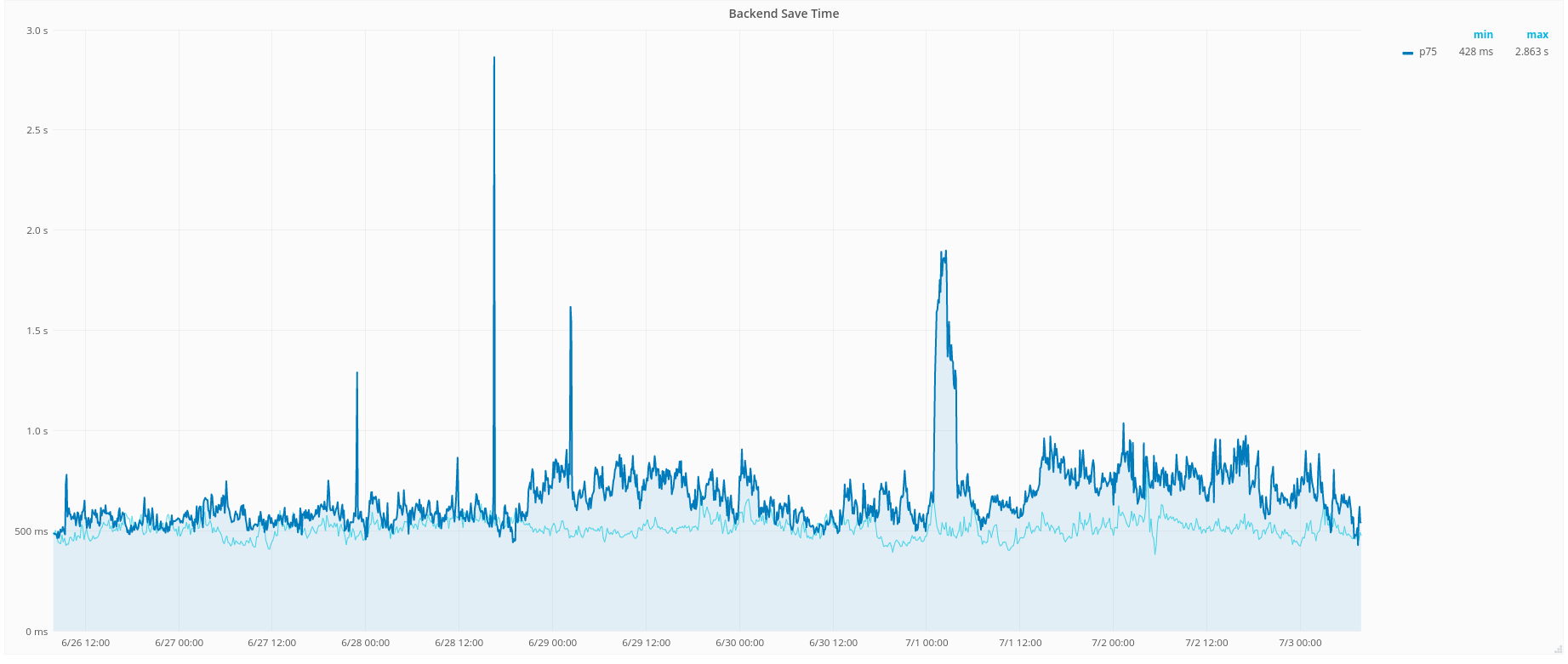
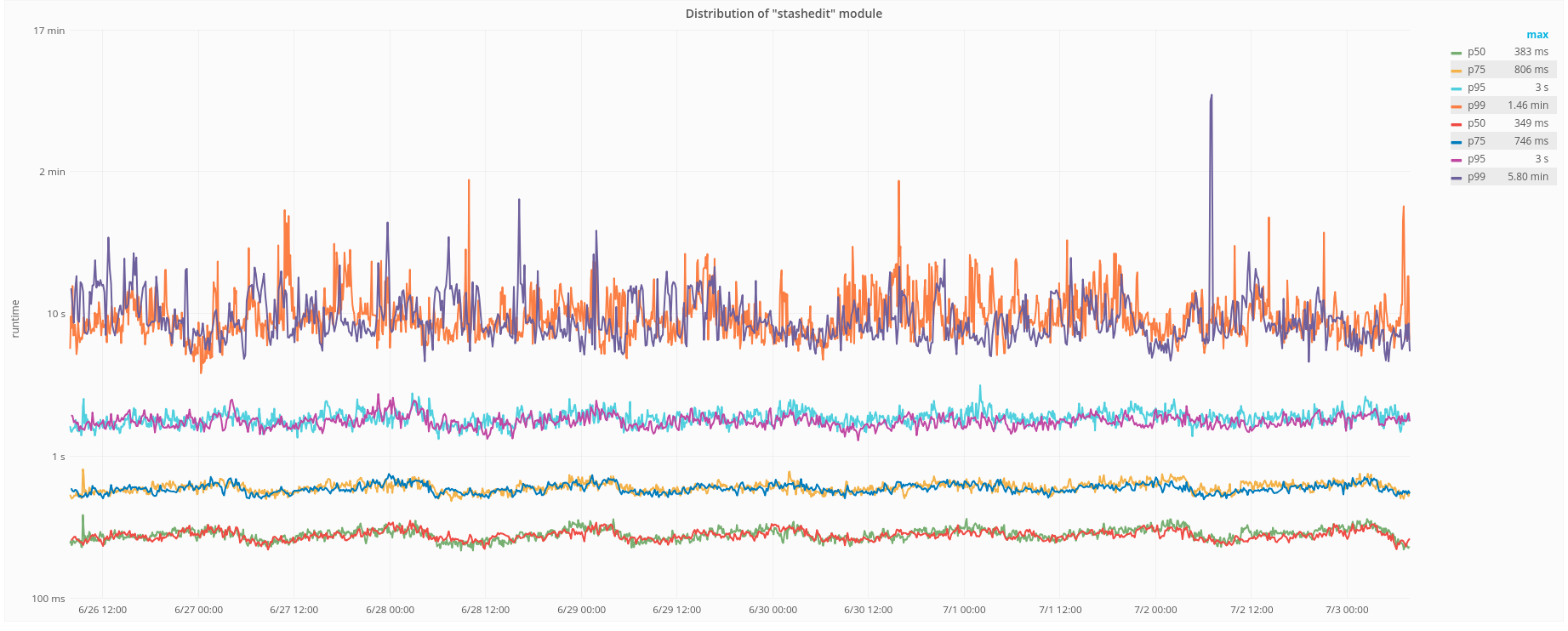
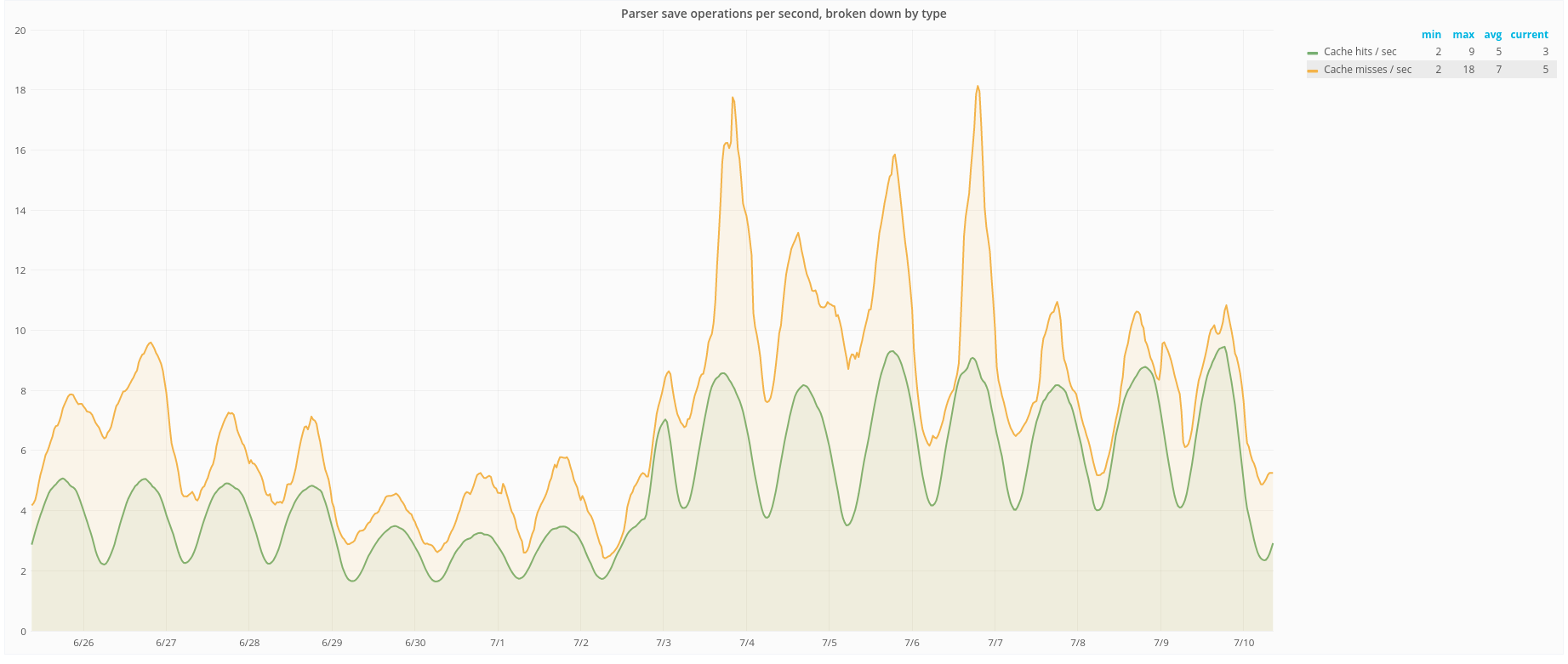
https://grafana.wikimedia.org/dashboard/db/save-timing?orgId=1&from=1530210478408&to=1530230285624
0d 11h 3m 12s 3/3 CRITICAL: https://grafana.wikimedia.org/dashboard/db/save-timing-alerts is alerting: Backend time p75 [ALERT] alert, Frontend save timings [ALERT] alert, Frontend save timings p75 [ALERT] alert.
This happens also to be the time of the train deployment.