Error
MediaWiki version: 1.35.0-wmf.26
message
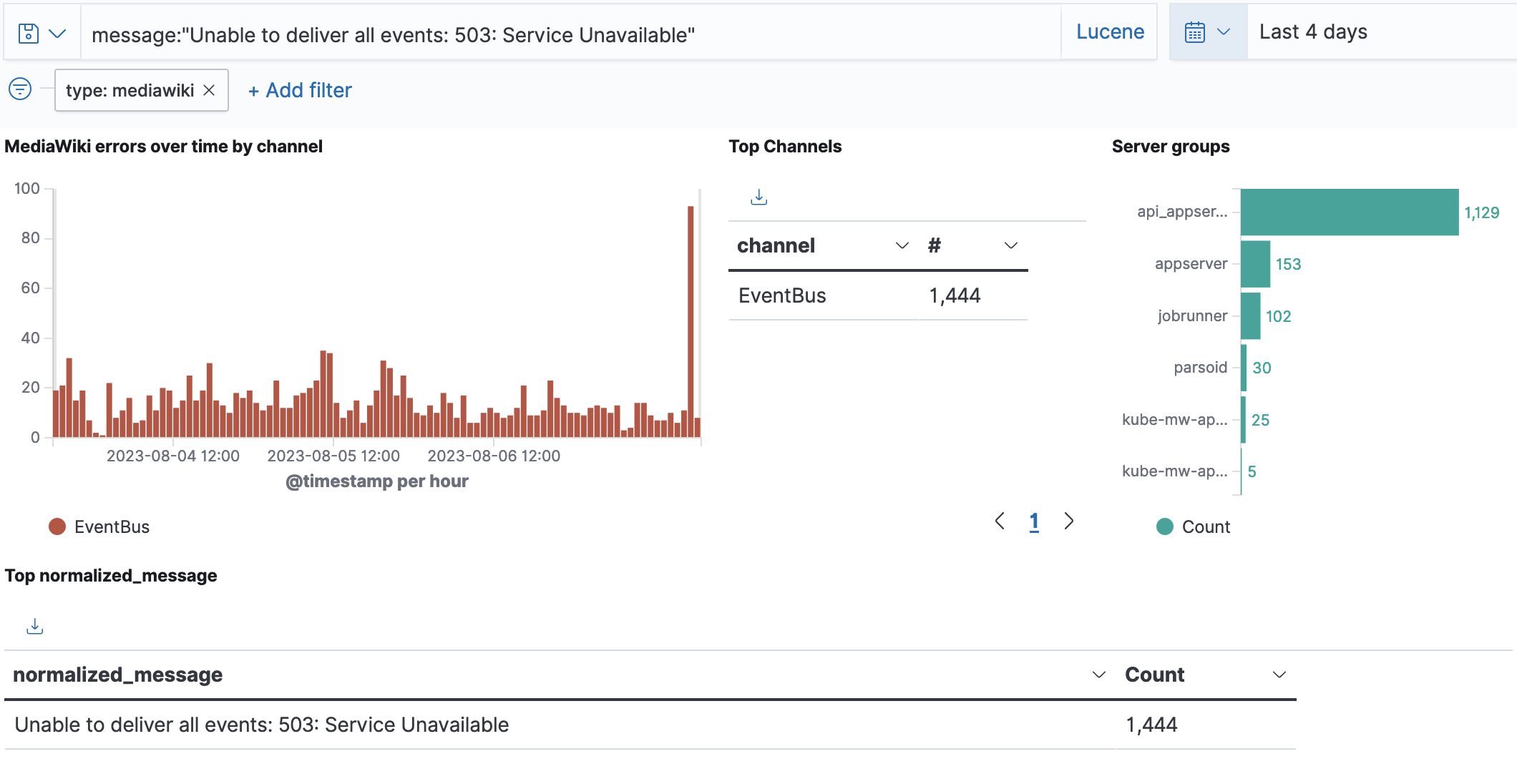
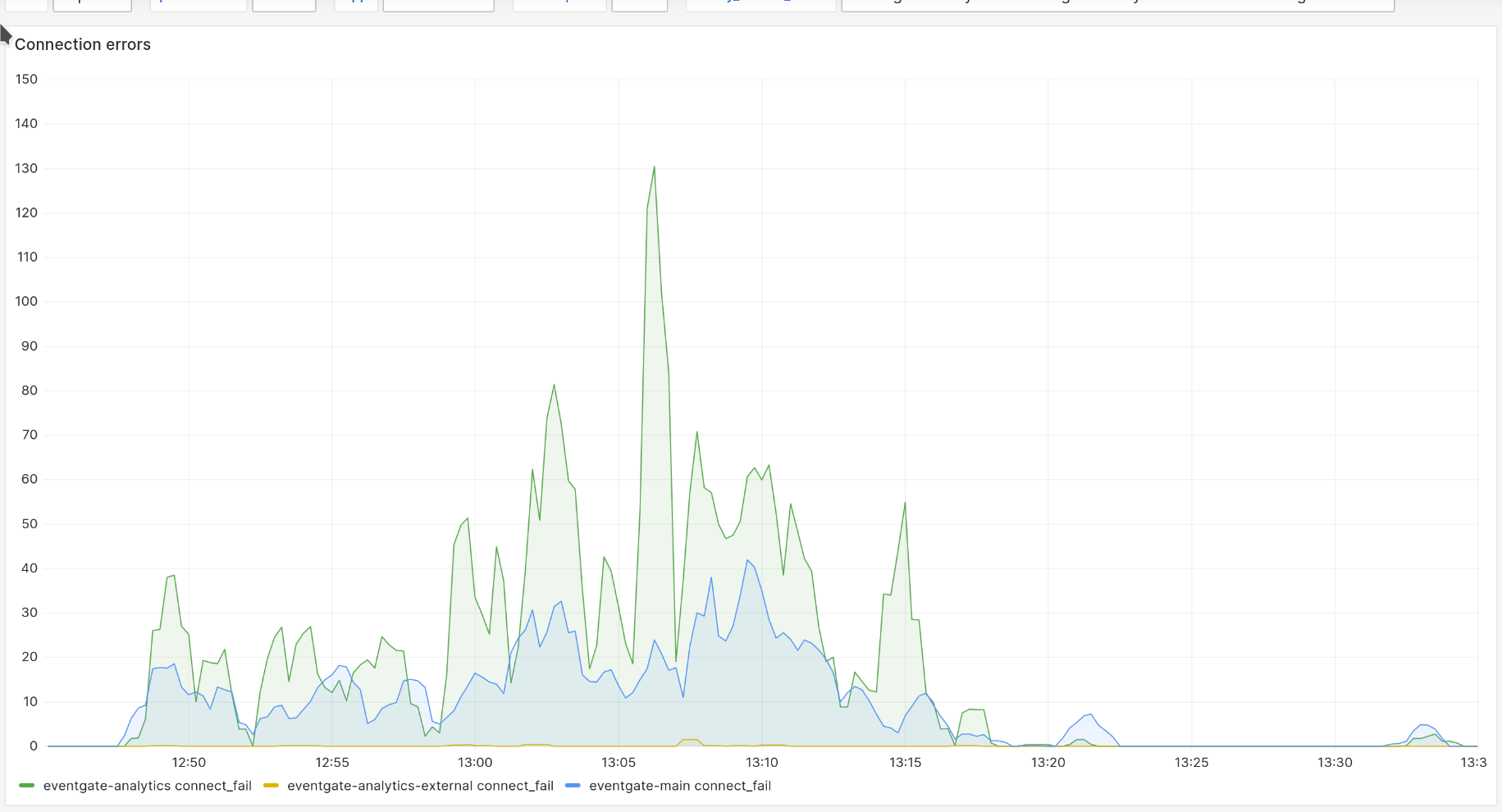
Could not enqueue jobs: Unable to deliver all events: 503: Service Unavailable
Impact
JobQueue updates lots could be from any core component or extensions. So far seen from the LInter extension, but does not appear to be specific to it in terms of backend error.
See also: