Proposed plan for discussion
Stage 0: X-Wikimedia-Debug
After the data store patches are deployed (811394, 809326), we can use an X-Wikimedia-Debug header to test basic operations for correctness. This does not use multi-dc.lua, so even POST requests will go to the secondary DC, but it should still work, with a latency penalty.
- CentralAuth explicit login
- CentralAuth auto login (Special:CentralAutoLogin)
- Edit token, page save
- AbuseFilter profile update
- Upload stash
Stage 1: testwiki
Configure multi-dc.lua to use the local mode for test.wikipedia.org. This is the first test of multi-dc.lua in production.
- Method-dependent (GET/POST) routing including page save
- UseDC=master cookie including MW integration (hasOrMadeRecentPrimaryChanges)
- Rollback
- API action=centralauthtoken
- Echo user talk bell icon, page view dismiss
- Echo user talk email
- API edit (e.g. HotCat), high latency
Stage 1.5: test2wiki
- Page view performance
- Parser cache miss performance
- API edit worst case test rig
- pywikibot
Stage 2: mediawikiwiki
- Beta test period
Stage 3: traffic percentage
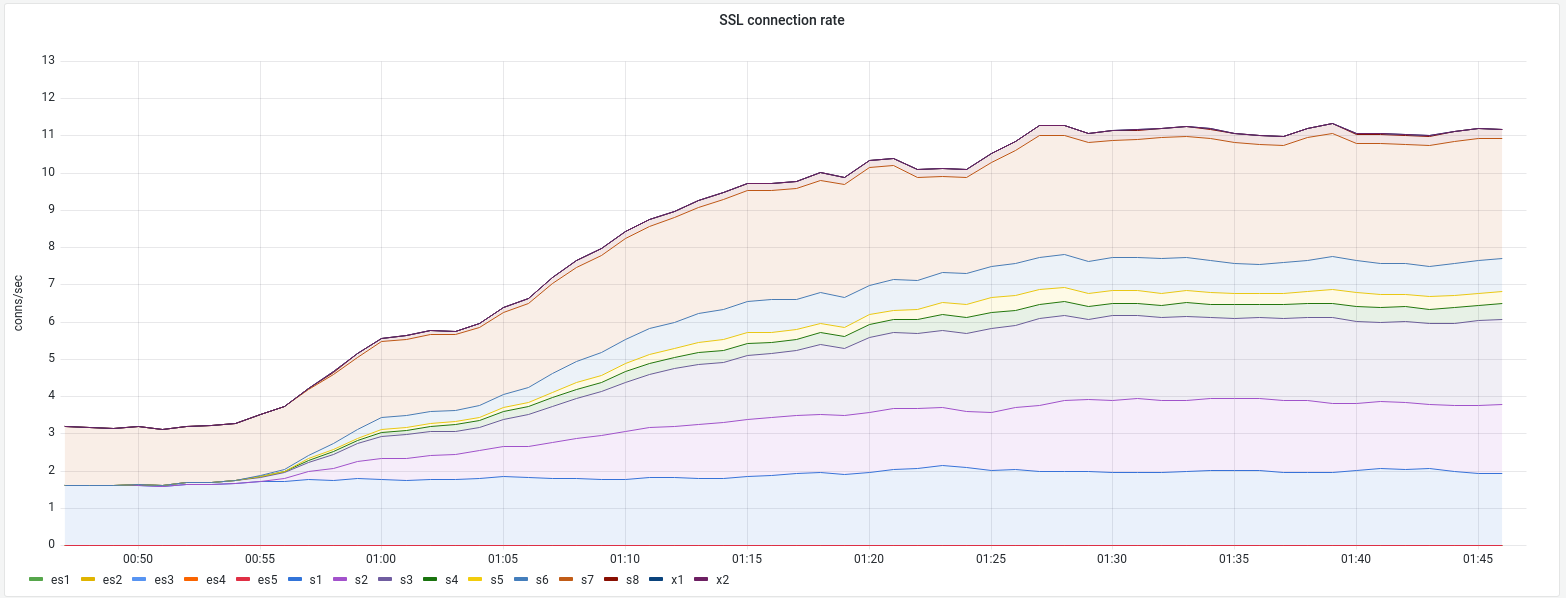
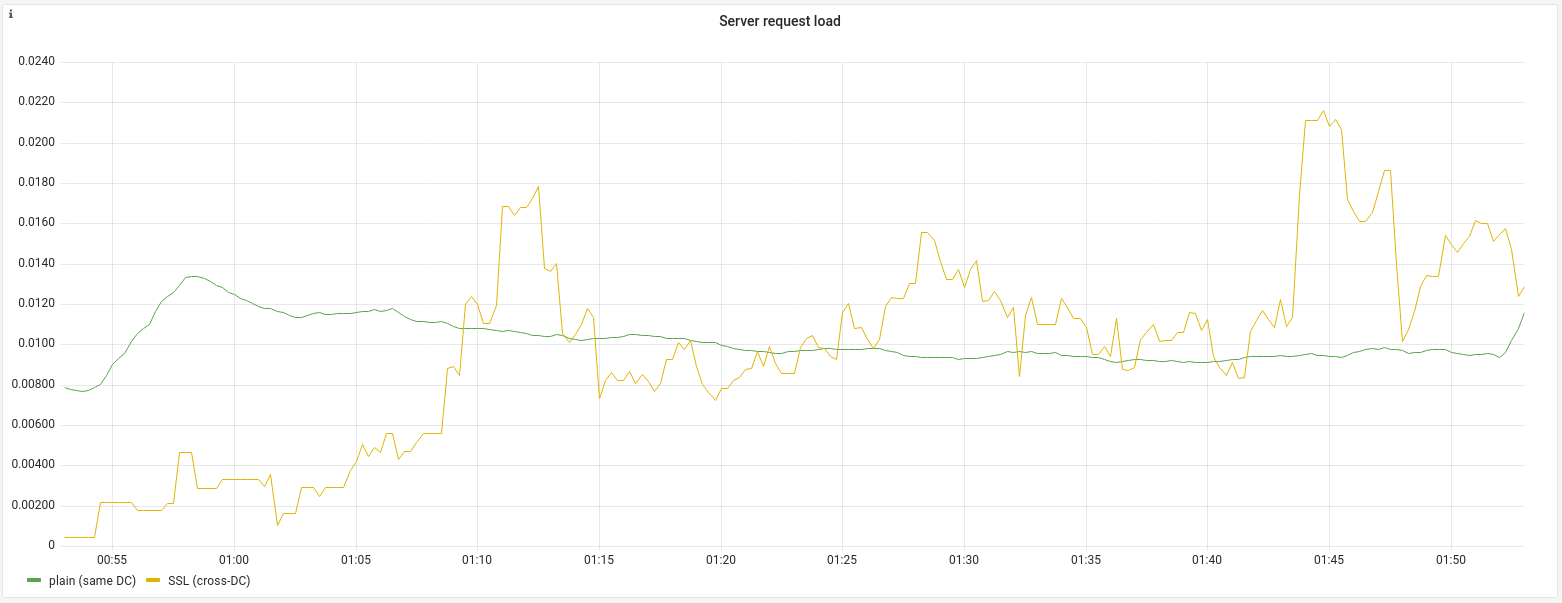
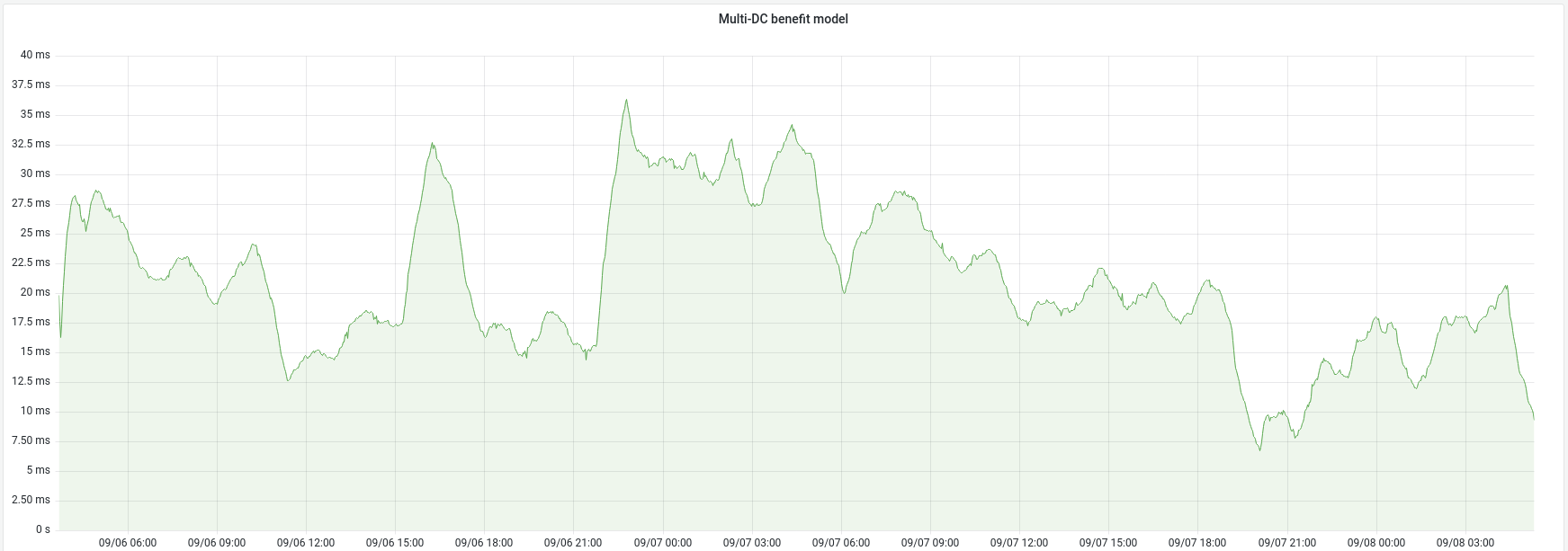
Sending 2% of eligible traffic to the local DC allows capacity modelling.
- Observe cross-DC database connection rate, analyse sources
- Observe cross-DC mcrouter queries
- Observe load on local services (DB replicas, mcrouter, etc.)
Stage 4: full deployment
This is the first stage that gives us reproducible testing of loginwiki routing. So the CentralAuth tests should be repeated at this stage.
- CentralAuth explicit login
- CentralAuth auto login
- CentralAuth account creation, cpPosIndex query parameter (appendShutdownCPIndexAsQuery)
Considerations
Some things to think about:
- By edge DC (e.g. esams, ulsfo, eqsin).
- By type of traffic (e.g. no-session logged-outs first, then sessioned users who use a Beta Feature cookie, then all sessioned/logged-ins).
- By wiki (e.g. test wikis, then internal wikis, then select early adopter wikis).
- By wiki project (e.g. Wiktionary, then Wikidata, then Commons, then Wikipedia).
- By percentage of traffic.
Of course these can be combined as well. For example:
- testwikis logged-outs (100% of logged-outs from any DC).
- Wiktionary logged-outs (one DC at a time, slowly ramp up percentage one after the other).
- etc.
Note that WikimediaDebug already allows early testing of this today (both logged-out and logged-in) for the applayer (though this ignores traffic routing of course, so e.g. this ignores user flows like POST going to primary, sticky DC cookie, then going back to secondary etc.)
Especially no-session users before sessioned/logged-ins, I think, will help in getting early learnings and progress while other parts are still being worked on since that involves fewer moving parts (no session storage, no significant DB writes), and alllows teams to work more in parallel rather than being blocked until everything is "done" at once.