I can't find a bug report but there is discussion of the Hebrew case here:
http://en.wikipedia.org/wiki/Wikipedia:Niqqud
The Hebrew case seems to have been known for some time.
Now we are noticing a similar problem with Arabic on Wiktionary. There is some
discussion here: http://en.wiktionary.org/wiki/Talk:%D8%AC%D8%AF%D8%A7
Version: unspecified
Severity: major
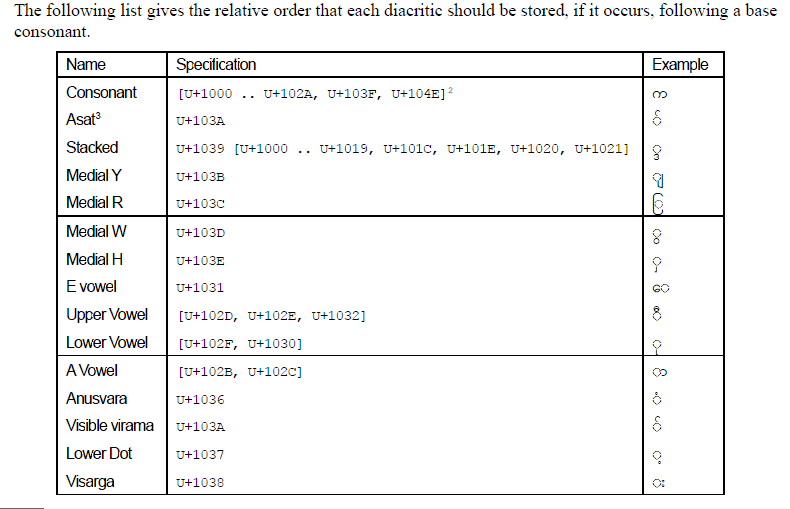
URL: http://www.mediawiki.org/wiki/Unicode_normalization_considerations


{kind=link}
{kind=link}