Thank you!
Feed Advanced Search
Jun 27 2019
Jun 27 2019
• Marostegui added a comment to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
Jun 27 2019, 1:31 PM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui added a comment to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
Jun 27 2019, 12:41 PM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui updated the task description for T220170: Address Database hardware infrastructure blockers on datacenter switchover & multi-dc deployment.
• Marostegui updated the task description for T217396: Decommission db1061-db1073.
This host is ready for DCOPs to take over.
• Marostegui updated the task description for T226689: decommission db1068.
• Marostegui updated the task description for T217396: Decommission db1061-db1073.
• Marostegui created T226689: decommission db1068.
• Marostegui added a comment to T226685: HTTP 503 on zh.wikipedia.org.
We are having general connectivity issues
• Marostegui updated subscribers of T226685: HTTP 503 on zh.wikipedia.org.
@BBlack restarted varnish on that host. It should be ok now.
• Marostegui added a comment to T226685: HTTP 503 on zh.wikipedia.org.
We are looking into general connectivity issues at the moment
• Marostegui updated the task description for T222978: Compress and defragment tables on labsdb hosts.
Jun 26 2019
Jun 26 2019
• Marostegui added a comment to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
Jun 26 2019, 4:02 PM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui added a comment to T71222: list=logevents slow for users with last log action long time ago.
I wanted to test this issue with 10.3 on db1114.
I copied logging page and user tables from dewiki from one of the hosts that have the weird plans and placed in this 10.3 server.
root@db1114.eqiad.wmnet[(none)]> select @@version; +---------------------+ | @@version | +---------------------+ | 10.3.16-MariaDB-log | +---------------------+ 1 row in set (0.00 sec)
• Marostegui added a comment to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
@Ladsgroup I believe that last time it wasn't necessary, but I am not 100% sure
Jun 26 2019, 1:15 PM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui awarded T206203: Implement database binary backups into the production infrastructure a Party Time token.
• Elitre awarded T224516: Database primary master failover on s4 (commonswiki) a Like token.
• Marostegui edited projects for T196020: Consider adding ContentTranslation (CX) tables to wiki replicas, added: User-Marostegui; removed DBA.
• Marostegui updated subscribers of T220170: Address Database hardware infrastructure blockers on datacenter switchover & multi-dc deployment.
I had a chat with @mark and we are considering this Q4 goal done:
- The 13 eqiad hosts were racked installed and provisioned T211613: rack/setup/install db11[26-38].eqiad.wmnet T211613: rack/setup/install db11[26-38].eqiad.wmnet
- codfw hosts were bought, racked, installed and provisioned {T220431} T221532: rack/setup/install db2[103-120].codfw.wmnet (18 hosts) T222772: Productionize db2[103-120]
- We have also started the failovers, s4 was already done T224852: Failover s4 primary master: db1068 to db1081 and x1 is scheduled for next week T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC
• Marostegui added a comment to T193224: Evaluate and decide the future of relational datastore at WMF after the upgrade of MariaDB 10.1 is finished.
• Marostegui added a comment to T193224: Evaluate and decide the future of relational datastore at WMF after the upgrade of MariaDB 10.1 is finished.
@jcrespo you ok if I copy dewiki.logging into db1114? I would like to see the behaviour of 10.3 optimizer in regards to the query planner bug observed at T71222: list=logevents slow for users with last log action long time ago
• Marostegui removed a project from T226546: babel database doesn't support language codes longer than 10 characters (e.g. de-x-formal): DBA.
• Marostegui closed T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table as Resolved.
All done
• Marostegui updated the task description for T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
• Marostegui added a comment to T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
Deletion process for s8 (wikidata). The table is 6GB there.
Not written since 29th March:
-rw-rw---- 1 mysql mysql 6.3G Mar 29 05:58 wikimedia_editor_tasks_entity_description_exists.ibd
• Marostegui updated the task description for T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
• Marostegui updated the task description for T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
• Marostegui updated the task description for T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
• Marostegui added a comment to T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
I have dropped this table from s3 (testwikidatawiki) which wasn't written since 27th March:
-rw-rw---- 1 mysql mysql 384K Mar 27 22:36 wikimedia_editor_tasks_entity_description_exists.ibd
• Marostegui added a parent task for T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC: T220170: Address Database hardware infrastructure blockers on datacenter switchover & multi-dc deployment.
Jun 26 2019, 5:38 AM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
All these hosts are now provisioned
• Marostegui closed T222682: Productionize db11[26-38], a subtask of T211613: rack/setup/install db11[26-38].eqiad.wmnet, as Resolved.
• Marostegui updated the task description for T222682: Productionize db11[26-38].
• Marostegui added a comment to T214362: RFC: Store WikibaseQualityConstraint check data in persistent storage.
Just a quick question: "this would fit a generalized parser cache mechanism" meaning it would fit into the existing parsercache mechanism (and infrastructure) or is that still to be defined?
Thanks!
Jun 25 2019
Jun 25 2019
Can we get this disk replaced - this is m3 master.
Thanks!
• Marostegui added a comment to T193224: Evaluate and decide the future of relational datastore at WMF after the upgrade of MariaDB 10.1 is finished.
This is not the RAID, this is the BBU which is broken - T225391#5261662 but the host is out of warranty
• Marostegui updated the task description for T222682: Productionize db11[26-38].
Restricted Application added a project to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC: Product-Infrastructure-Team-Backlog-Deprecated.
Thanks a lot @Tgr I will tag those (better to tag them and they can remove themselves if it no longer applies) and update documentation accordingly.
Thanks again, very useful!
Jun 25 2019, 10:07 AM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
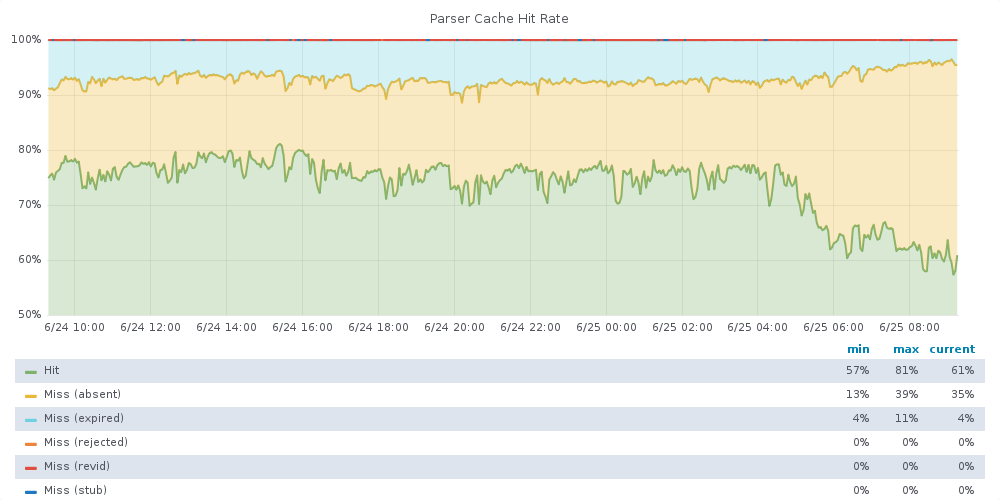
• Marostegui added a comment to T210725: Replace parsercache keys to something more meaningful on db-XXXX.php.
I have finished deploying the last key change. I did it in small batches during a few hours: https://grafana.wikimedia.org/render/d-solo/000000106/parser-cache?panelId=1&orgId=1&from=1561367808736&to=1561454208737&refresh=10s&var-contentModel=wikitext&width=1000&height=500&tz=Europe%2FMadrid
• Marostegui added a comment to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
Thank you! :)
Jun 25 2019, 8:45 AM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui added a comment to T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
Thanks @Ladsgroup!
We have always talked about documenting who and which teams to tag when planning x1 switchovers, so I have created this https://wikitech.wikimedia.org/wiki/MariaDB#Special_section:_x1_master_switchover (based on this task and the previous ones).
Jun 25 2019, 8:07 AM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui closed T211613: rack/setup/install db11[26-38].eqiad.wmnet, a subtask of T217396: Decommission db1061-db1073, as Resolved.
• Marostegui changed the status of T211613: rack/setup/install db11[26-38].eqiad.wmnet from Stalled to Open.
Finally db1133 has been installed correctly!
Thanks @Cmjohnson for getting it fixed!
root@db1133:~# megacli -LdPdInfo -a0 ; megacli -LdPdInfo -a0 | grep state ; megacli -LdPdInfo -a0 | grep -i Raw ; megacli -LdPdInfo -a0 | grep state | wc -l ; free -g
• Marostegui changed the status of T211613: rack/setup/install db11[26-38].eqiad.wmnet, a subtask of T217396: Decommission db1061-db1073, from Stalled to Open.
• Marostegui changed the status of T211613: rack/setup/install db11[26-38].eqiad.wmnet, a subtask of T220170: Address Database hardware infrastructure blockers on datacenter switchover & multi-dc deployment, from Stalled to Open.
I have re-imaged the host after Chris did it yesterday and everything looks good: RAID, memory, CPUS...
root@db1133:~# megacli -LdPdInfo -a0
• Marostegui closed T222731: Storage problems with new host db1133, a subtask of T211613: rack/setup/install db11[26-38].eqiad.wmnet, as Resolved.
• Marostegui updated the task description for T222682: Productionize db11[26-38].
Jun 24 2019
Jun 24 2019
• Marostegui updated the task description for T208323: Predictive failures on disk S.M.A.R.T. status.
The RAID finished correctly, although the disk came with predictive failure.
I am going to close this task as resolved as the ops-monitoring will open a new once once it has failed again:
physicaldrive 1I:1:1 (port 1I:box 1:bay 1, SAS, 600 GB, OK) physicaldrive 1I:1:2 (port 1I:box 1:bay 2, SAS, 600 GB, OK) physicaldrive 1I:1:3 (port 1I:box 1:bay 3, SAS, 600 GB, Predictive Failure) physicaldrive 1I:1:4 (port 1I:box 1:bay 4, SAS, 600 GB, OK) physicaldrive 1I:1:5 (port 1I:box 1:bay 5, SAS, 600 GB, OK) physicaldrive 1I:1:6 (port 1I:box 1:bay 6, SAS, 600 GB, OK) physicaldrive 1I:1:7 (port 1I:box 1:bay 7, SAS, 600 GB, OK) physicaldrive 1I:1:8 (port 1I:box 1:bay 8, SAS, 600 GB, OK) physicaldrive 1I:1:9 (port 1I:box 1:bay 9, SAS, 600 GB, OK) physicaldrive 1I:1:10 (port 1I:box 1:bay 10, SAS, 600 GB, OK) physicaldrive 1I:1:11 (port 1I:box 1:bay 11, SAS, 600 GB, OK) physicaldrive 1I:1:12 (port 1I:box 1:bay 12, SAS, 600 GB, OK)
• Marostegui added a comment to T206203: Implement database binary backups into the production infrastructure.
\o/
It failed already :(
physicaldrive 1I:1:3 (port 1I:box 1:bay 3, SAS, 600 GB, Failed)
• Marostegui updated the task description for T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC.
Jun 24 2019, 2:06 PM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui moved T225988: decommission db2039 from Backlog to Ready for Decommission on the decommission-hardware board.
• Marostegui updated the task description for T208323: Predictive failures on disk S.M.A.R.T. status.
• Marostegui added a comment to T222050: db1107 (eventlogging db master) possibly memory issues.
@Cmjohnson as per the error @jcrespo pasted above is that enough to get Dell to send a new DIMM you think?
• Marostegui triaged T226358: Failover x1 master: db1069 to db1120 3rd July at 06:00 UTC as Medium priority.
Jun 24 2019, 7:59 AM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
Jun 24 2019, 7:59 AM · Wikidata, User-notice-archive, Product-Infrastructure-Team-Backlog-Deprecated, WikimediaEditorTasks, Reading List Service, ContentTranslation, MediaWiki-extensions-BounceHandler, StructuredDiscussions, MediaWiki-extensions-UrlShortener, Cognate, Language-Team, Growth-Team, SRE, DBA
• Marostegui updated the task description for T222682: Productionize db11[26-38].
• Marostegui updated the task description for T222682: Productionize db11[26-38].
• Marostegui updated the task description for T222682: Productionize db11[26-38].
• Marostegui added a comment to T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
Same has been done on testwikidatawiki on s3:
root@db1123.eqiad.wmnet[testwikidatawiki]> rename table wikimedia_editor_tasks_entity_description_exists to T226326_wikimedia_editor_tasks_entity_description_exists; Query OK, 0 rows affected (0.01 sec)
So for now I have renamed the table on db1092 and will leave it like that for a couple of days before dropping it for good, just to see if there are some unexpected issues:
root@db1092.eqiad.wmnet[wikidatawiki]> rename table wikimedia_editor_tasks_entity_description_exists to T226326_wikimedia_editor_tasks_entity_description_exists; Query OK, 0 rows affected (0.01 sec)
• Marostegui added a comment to T226337: SpecialConfirmEmail causes "MWException: CAS update failed on user_touched" from User.php.
Some more details:
Jun 23 2019
Jun 23 2019
• Marostegui added a comment to T226337: SpecialConfirmEmail causes "MWException: CAS update failed on user_touched" from User.php.
Thanks for creating the task :)
• Marostegui added a comment to T226297: ERROR 2013 (HY000): Lost connection to MySQL server during query on replicas.
Yeah, essentially we have 3 hosts. Usually only one of them is dedicated to the long queries (analytics) and 2 of the to the web service (fast queries), but due to the maintenance (T222978) we have now 1 host serving analytics which also serves a portion of web, and hence it is more loaded than normal.
This is the change: https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/518029/
• Marostegui updated the task description for T208323: Predictive failures on disk S.M.A.R.T. status.
• Marostegui added a comment to T226326: Drop the `wikimedia_editor_tasks_entity_description_exists` table.
Can this go anytime then?
Jun 22 2019
Jun 22 2019
• Marostegui added a comment to T226297: ERROR 2013 (HY000): Lost connection to MySQL server during query on replicas.
It is because labsdb1010 is serving (temporarily while we do some maintenance on 1011) analytics but still has the query killer set to 300 seconds instead of 14400 (14400 is the one we use for the long query hosts). I have changed it and it is now set to 14400 so it should not be killing those small queries anymore.
Jun 21 2019
Jun 21 2019
• Marostegui updated the task description for T202367: Productionize dbproxy101[2-7].eqiad.wmnet and dbproxy200[1-4].
All hosts installed
• Marostegui closed T225704: eqiad: rack/setup/install (4) dbproxy systems., a subtask of T202367: Productionize dbproxy101[2-7].eqiad.wmnet and dbproxy200[1-4], as Resolved.
• Marostegui updated the task description for T225704: eqiad: rack/setup/install (4) dbproxy systems..
• Marostegui updated the task description for T202367: Productionize dbproxy101[2-7].eqiad.wmnet and dbproxy200[1-4].
• Marostegui updated the task description for T202367: Productionize dbproxy101[2-7].eqiad.wmnet and dbproxy200[1-4].
• Marostegui updated the task description for T225704: eqiad: rack/setup/install (4) dbproxy systems..
• Marostegui moved T225169: [4 hours] Investigate whether it's efficient to order by tag value (DBA input requested) from Triage to Done on the DBA board.
I have been checking this query on enwiki and it doesn't seem to be too bad:
root@db1089.eqiad.wmnet[enwiki]> FLUSH STATUS; pager cat > /dev/null; SELECT page_namespace, page_title, ptrpt_value FROM pagetriage_page_tags JOIN page ON ptrpt_page_id = page_id WHERE ptrpt_tag_id = 2 ORDER BY CAST(ptrpt_value AS SIGNED) DESC LIMIT 10; ; nopager; SHOW STATUS like 'Hand%'; Query OK, 0 rows affected (0.00 sec)
While debugging we Arzhel we have noticed that the DNS entries for dbproxy1018 and dbproxy1019 didn't belong to the cloud network, I have changed them and I will to install again.
• Marostegui updated the task description for T202367: Productionize dbproxy101[2-7].eqiad.wmnet and dbproxy200[1-4].
• Marostegui reassigned T225704: eqiad: rack/setup/install (4) dbproxy systems. from • Marostegui to • Cmjohnson.
@Cmjohnson @ayounsi is there anything special with dbproxy1018 and dbproxy1019 VLAN's and PXE? None of the seems to be booting up from PXE, despite that the MACs I added on tftpboot are the same ones that the IDRAC show it is trying to boot up from:
dbproxy1018 4C:D9:8F:6C:A5:9E https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/518197/1/modules/install_server/files/dhcpd/linux-host-entries.ttyS1-115200
dbproxy1019 4C:D9:8F:6C:9F:2F https://gerrit.wikimedia.org/r/#/c/operations/puppet/+/518203/2/modules/install_server/files/dhcpd/linux-host-entries.ttyS1-115200
• Marostegui updated the task description for T225704: eqiad: rack/setup/install (4) dbproxy systems..
• Marostegui updated the task description for T225704: eqiad: rack/setup/install (4) dbproxy systems..
And it finally cleared up
23:38:30 <+icinga-wm> RECOVERY - EDAC syslog messages on db2084 is OK: All metrics within thresholds. https://grafana.wikimedia.org/dashboard/db/host-overview?orgId=1&var-server=db2084&var-datasource=codfw+prometheus/ops
Jun 20 2019
Jun 20 2019
• Marostegui added a comment to T225889: Degraded RAID on db2043.
And the disk failed again
Duplicate of T225889
• Marostegui added a comment to T225704: eqiad: rack/setup/install (4) dbproxy systems..
@RobH if you add the production DNS entries, I can take care of the installations myself