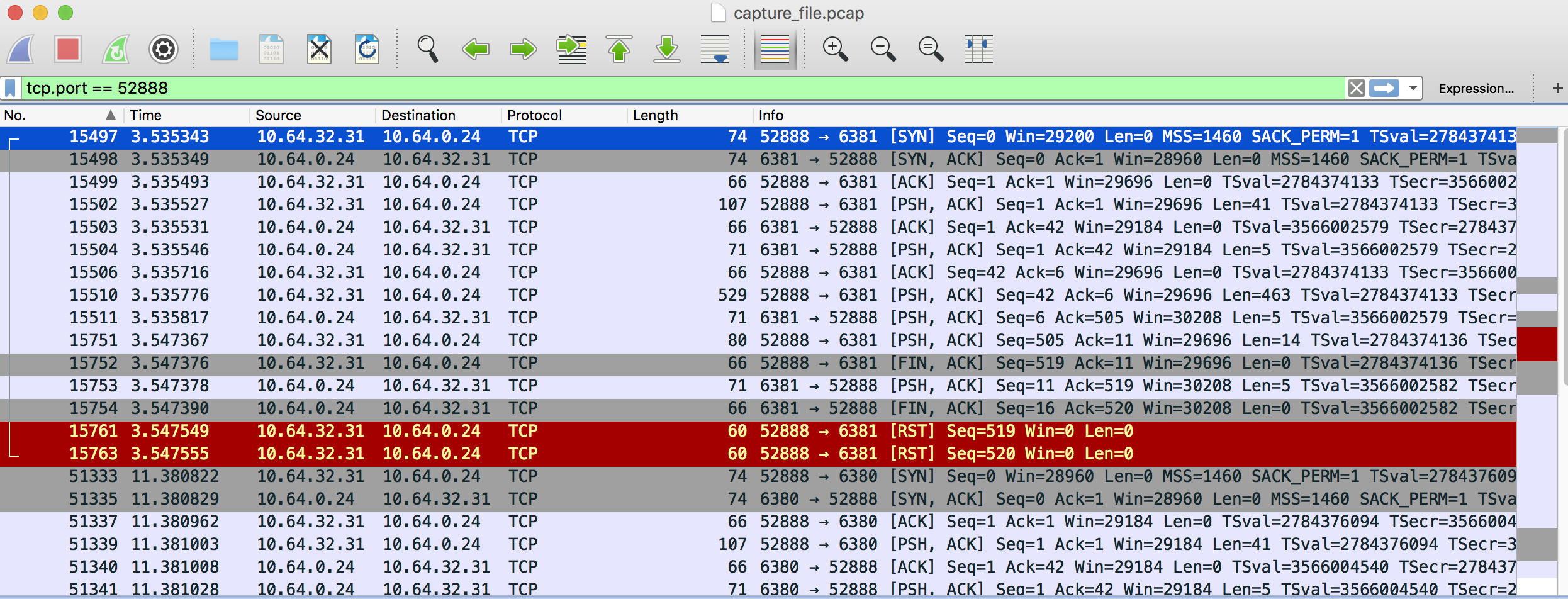
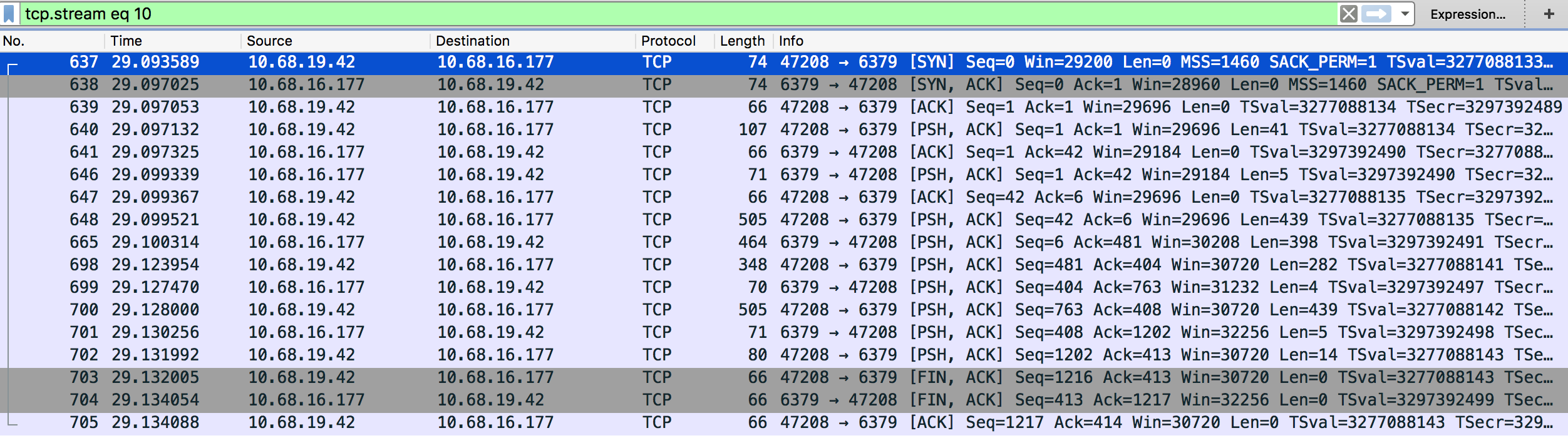
Paired errors connecting to the job queue redis instances:
Feb 3 07:51:10 mw1226: #012Warning: timed out after 0.2 seconds when connecting to rdb1001.eqiad.wmnet [110]: Connection timed out Feb 3 07:51:10 mw1226: #012Warning: Failed connecting to redis server at rdb1001.eqiad.wmnet: Connection timed out
Can be found by search redis on https://logstash.wikimedia.org/
Seems to be load related and/or mostly from job runners. Example:
Unable to connect to redis server rdb1003.eqiad.wmnet:6380.
#0 /srv/mediawiki/php-1.28.0-wmf.18/includes/jobqueue/JobQueueRedis.php(310): JobQueueRedis->getConnection()
#1 /srv/mediawiki/php-1.28.0-wmf.18/includes/jobqueue/JobQueue.php(372): JobQueueRedis->doPop()
#2 /srv/mediawiki/php-1.28.0-wmf.18/includes/jobqueue/JobQueueFederated.php(290): JobQueue->pop()
#3 /srv/mediawiki/php-1.28.0-wmf.18/includes/jobqueue/JobQueue.php(372): JobQueueFederated->doPop()
#4 /srv/mediawiki/php-1.28.0-wmf.18/includes/jobqueue/JobQueueGroup.php(204): JobQueue->pop()
#5 /srv/mediawiki/php-1.28.0-wmf.18/includes/jobqueue/JobRunner.php(160): JobQueueGroup->pop()
#6 /srv/mediawiki/rpc/RunJobs.php(47): JobRunner->run()
#7 {main}4000 messages over an hour :( Seems redis servers are saturated.
From dupe task T130078
Logstash shows up a good spam of messages "Unable to connect to redis server" on https://logstash.wikimedia.org/app/kibana#/dashboard/Redis
The top offenders:
| server:port | 24 hours hits |
|---|---|
| rdb1001.eqiad.wmnet:6380 | 166685 |
| rdb1001.eqiad.wmnet:6379 | 165655 |
| rdb1001.eqiad.wmnet:6381 | 159330 |
| rdb1005.eqiad.wmnet:6380 | 73329 |
| rdb1005.eqiad.wmnet:6381 | 68856 |
| rdb1005.eqiad.wmnet:6379 | 65288 |
| rdb1003.eqiad.wmnet:6379 | 13038 |
| rdb1007.eqiad.wmnet:6379 | 13015 |
| rdb1007.eqiad.wmnet:6380 | 12778 |
| rdb1007.eqiad.wmnet:6381 | 12351 |
Maybe it is due to the currently abnormal of refreshLink jobs being processed. Maybe the Nutcracker proxy is not used or redis instance is being overloaded / has not enough connections.
Also it seems load-related as there is a daily pattern for "unable to connect to redis server"

Debugging
One can run a jobrunner process in foreground mode with debug log send to stdout (example spam P5240 ):
sudo -H -u www-data /usr/bin/php /srv/deployment/jobrunner/jobrunner/redisJobRunnerService --config-file=/tmp/jobrunner-debug.conf --verbose