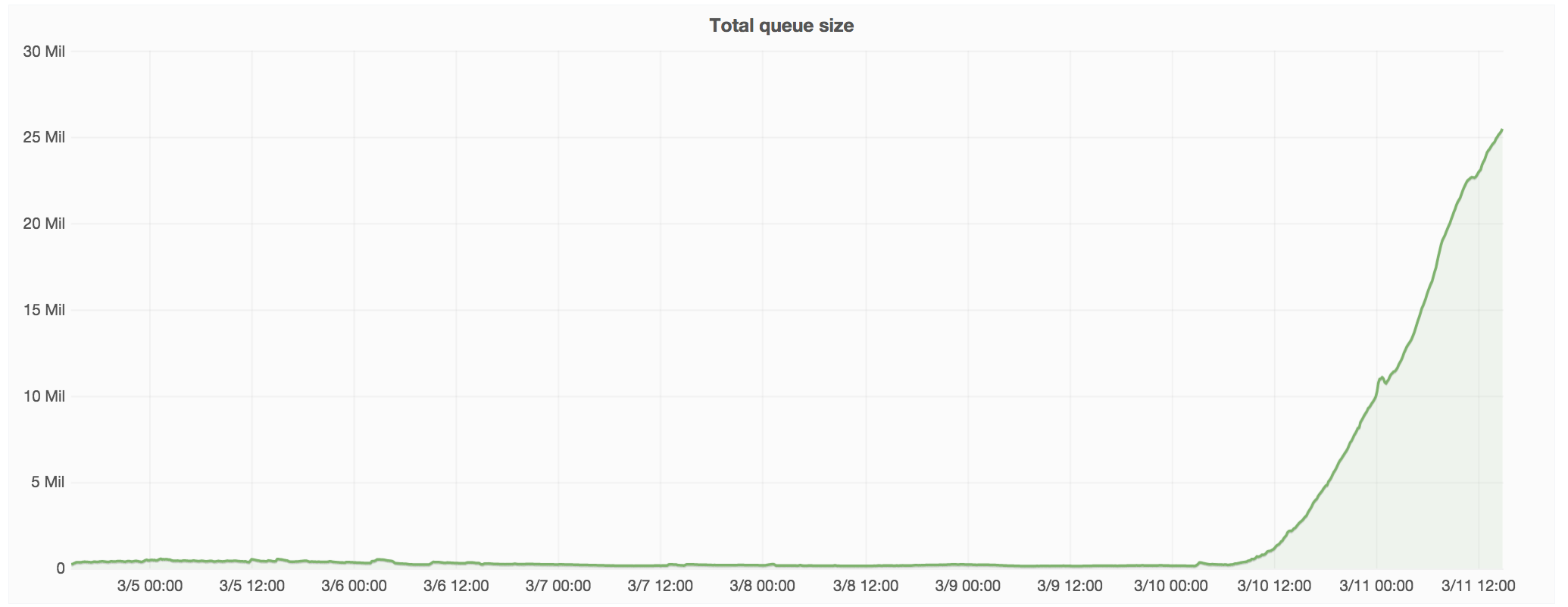
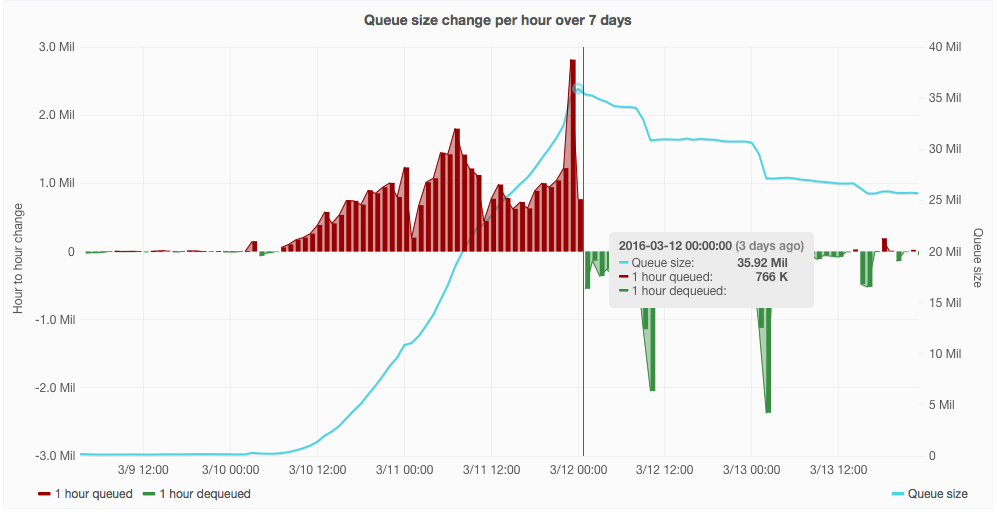
Since first reported, the jobqueue grew up to 32 million jobs and is now steadily reducing and currently under 26 millions thanks to a series of tweaks we performed, but the real worrying fact is that the number of inserted jobs has grown by almost 1000% compared to last week.
Last time we had this, this was T124194, but that was a job queue performance issue; at the moment our job queues are operating at throughputs we've never seen before.
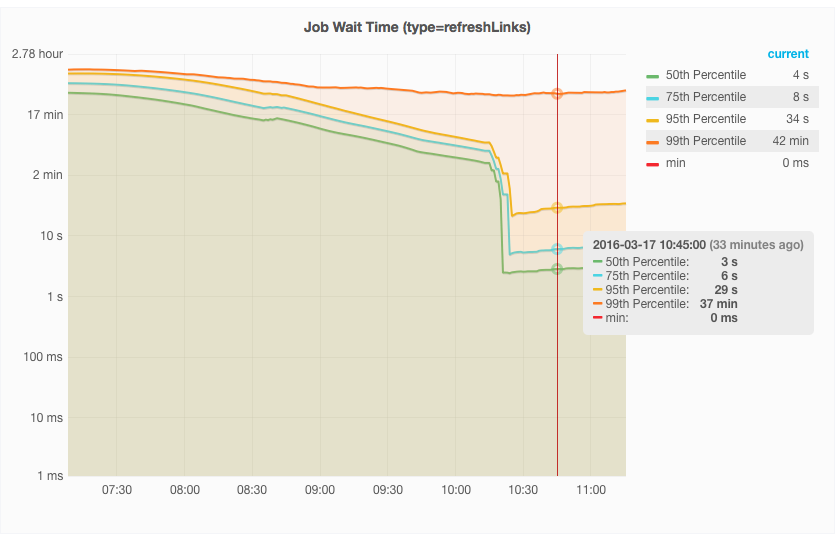
This has consequences on the databases (see T129830) and in general puts a strain on our infrastructure, and should be treated as a serious production issue
Grafana view: https://grafana.wikimedia.org/dashboard/db/job-queue-health?panelId=15&fullscreen