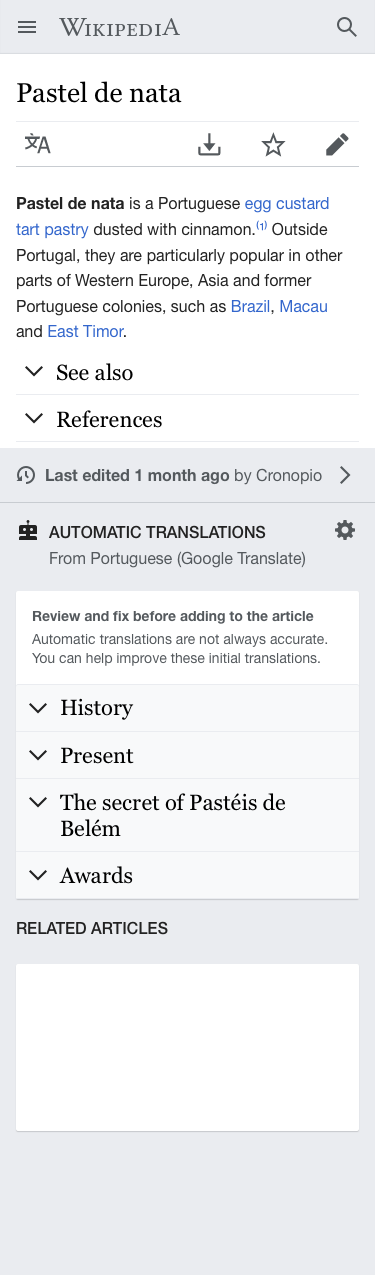
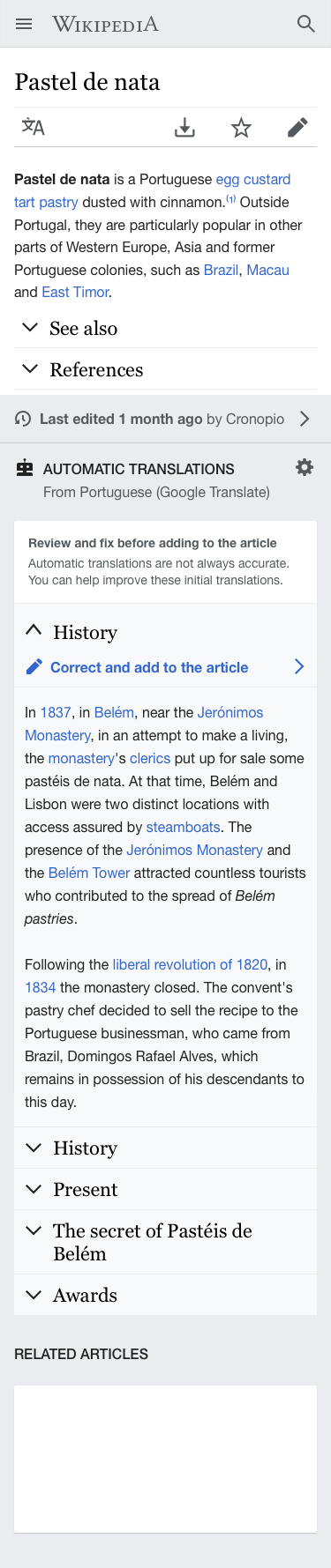
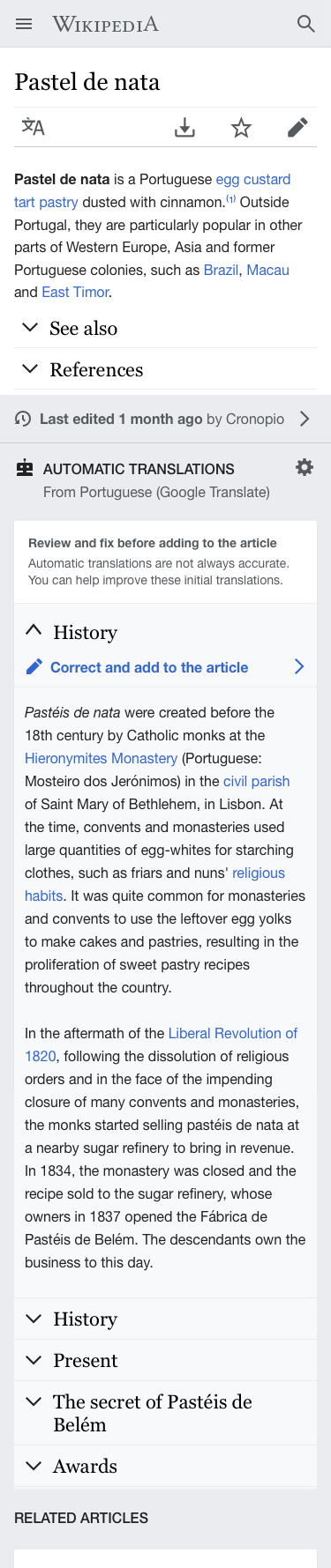
Surfacing sections that are available in other languages can motivate editors to expand an article in their current language. This ticket proposes to surface missing sections by using Machine translation to enable users to (a) learn more about the topic and (b) discover opportunities to expand the existing article. Check the prototype illustrating the concept.
Goals:
- Provide readers access to knowledge that they could not access otherwise.
- Make it clear that the translation is automatic and not part of the community-created content
- Encourage users to expand the article by reviewing and contributing a section.
- Provide adequate guidance considering that most readers may have no previous experience contributing.
- Respect user preferences. Allow to opt-out, indicate which language to translate from and which translation service to use.
Design details
| The Guitar article is short in Bengali, and a list of sections is listed in the footer area with translations from English. | Readers can read more about the history ("ইতিহাস") with a specific invite to use section translation to incorporate it to the article. |
|---|---|
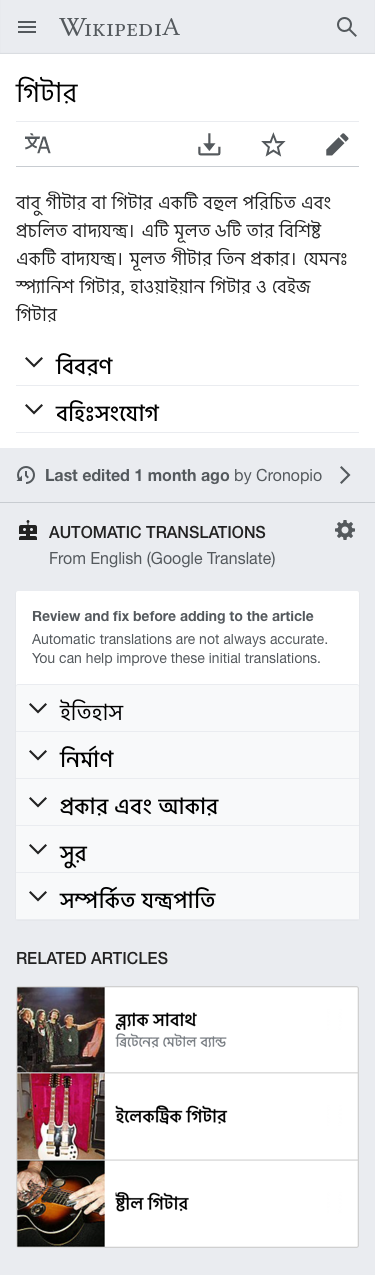 | 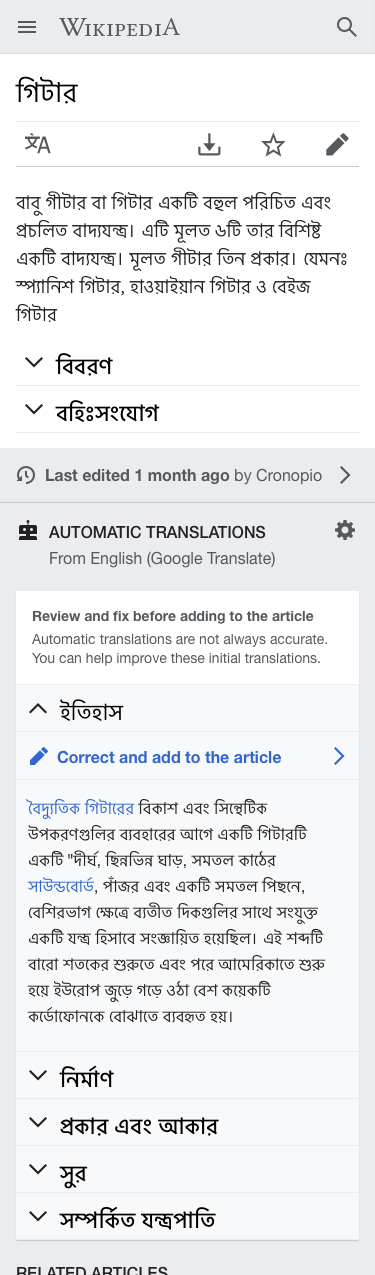 |
An "Automatic translations" block is shown at the footer area after the article, in a similar way to the "Related articles". The new block will be placed after the "Last edited" indicator (more directly connected to community-created sections), and the "Related articles" block (less directly connected to the current article).
The header of this block contains the following information:
- Title: "AUTOMATIC TRANSLATIONS". Stylized in capital letters to match the . Obviously this applies only to languages using a script where capital letters are available (don't use them in scripts where these do not exist).
- MT service and source indicators: A "From <source-language> (<mt-service>)" message is shown. This communicates the language from which the sections are translated and the translation service that will be used. The default source language can be the most commonly used as a source when translating to the current language (which in most cases is English based on CX data).
- Settings option. A cog icon is shown at the top-right corner of the block to provide access to the settings. This will allow to change the MT provider and the source language used for the translation.
A card contains the translated section titles:
- Introduction message. Communicates the purpose of the sections below and emphasizes the need to review MT:
Review and fix before adding to the article
Automatic translations are not always accurate. You can help improve these initial translations.
- Sections are rendered in the same way as in the article but using a light grey background (Base90: #f8f9fa).
- Sections can be expanded showing it's contents. The standard loading indicator will be shown while loading.
- Action to translate. On expanded sections, below their title, a call to action to translate is shown: "Correct and add to the article" with an "edit" icon before it and a "next" icon after it.
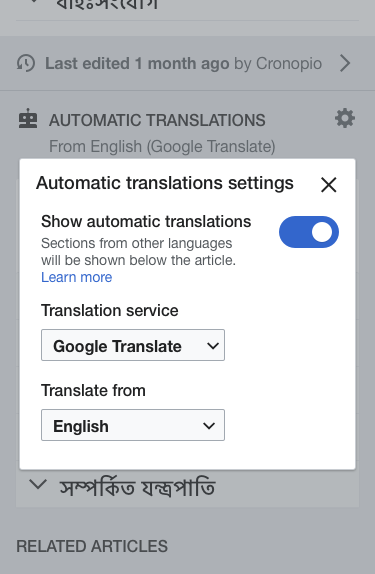
Settings
TBD
Details on logic
For the initial iteration we may want to expose this entry point only when meeting all the below conditions:
- User is logged-in.
- The article in the local wiki has no content sections (i.e., not counting "references", "see also", and similar).
- The section mapping API returns "content" sections available for translation. That is, the article can be expanded with sections other than "references", "see also", and similar.
Technical details
Obtaining machine translations for content has a cost (performance, data, etc.), some ideas we may want to consider:
- The list of missing sections can be obtained from the section title database used for the section mapping API. As proposed in T276214, MT can be used only for titles as a fallback where these are not in the database.
- Request MT only when the user expands a given section. This requires the user to wait until the request is completed, but avoids unnecessary requests.