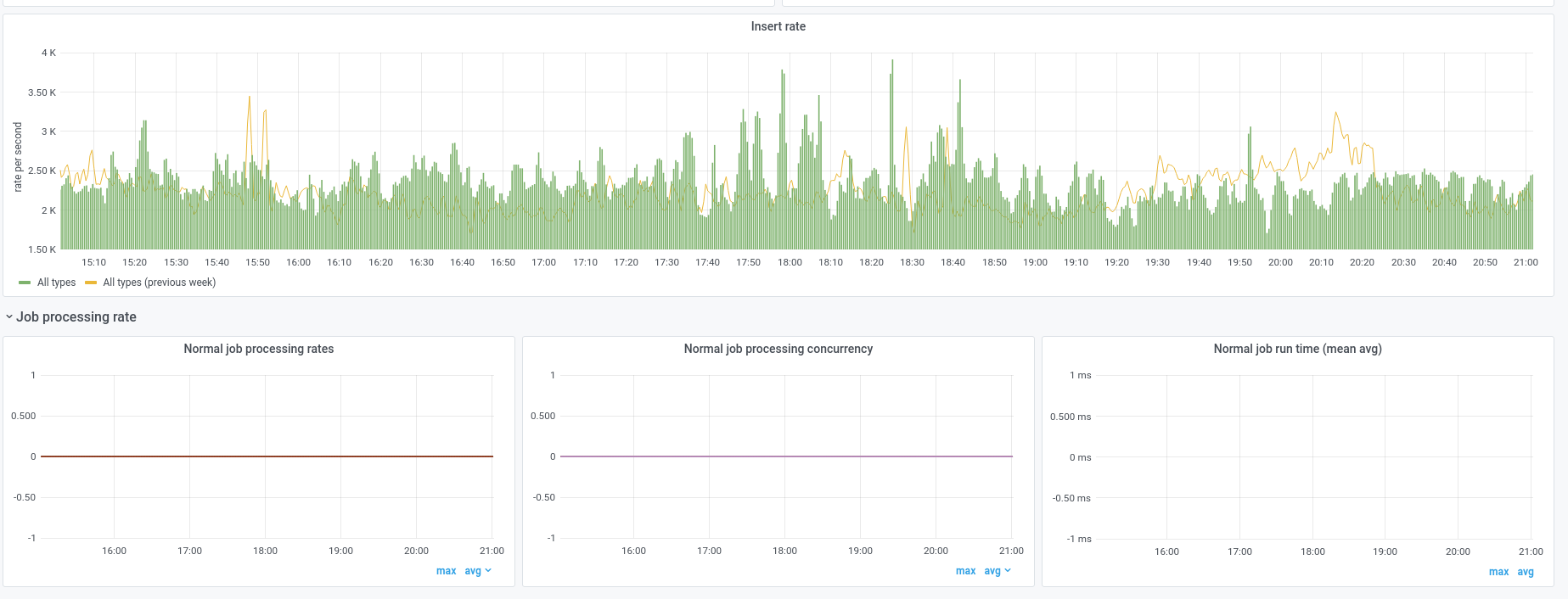
Judging by the recent bug reports (see subtasks), various jobs are either not being executed or executed slowly
https://grafana-rw.wikimedia.org/d/000000400/jobqueue-eventbus?orgId=1 does not seem to have any meaningful metrics.
This is a catch-all task to track all the various issues relevant to poorly performing job queue.
Also the message processing backlog graph does not look good.