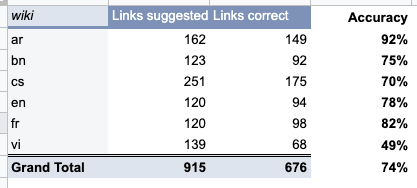
Now that the link recommendation algorithm has been productized into an API, we want to re-evaluate its results to ensure that it is still performing at a high level and that no regressions occurred as it was productized. We are expecting around 75% of link recommendations to be accurate.
Here's the procedure:
- Make sure that you have this browser extension installed in Chrome, which will allow you to easily read the results from the API.
- @Urbanecm_WMF will list 60 random articles from fr, en, vi, ar, cs, and bn in this spreadsheet. They will be articles that have at least one link recommendation.
- For each article, open the article up and open up its API link to receive its recommendations. List how many recommendations there are in the "links suggested" column. @Urbanecm_WMF will prepopulate the API links in the spreadsheet, but this is the link to the API for your reference.
- Look at each recommendation and decide whether you would choose "Yes" or "No". This judgment should be based both on whether that word or phrase should be a link and whether the link target is the right article to which it should be linked.
- In the spreadsheet, enter how many recommendations were given for the article and how many you would choose "Yes".
- Also enter whether the article is "short", "medium", or "long", according to your judgment.
- Add any notes or issues that you saw. Example of things to note are: clear reasons why the algorithm was wrong (e.g. "Suggests a link in the middle of a longer song title"), or if the algorithm recommends a link after that word's first occurrence in the article, or if it suggests linking to a disambiguation page.
Other notes:
- If the article in the list is a disambiguation page, just cross it out and leave a note. Do not evaluate these, because we won't be recommending disambiguation pages to users.
- Take a brief look at the "context before" and "context after" fields from the API. These are meant to be the characters occurring immediately before and after the link text, which are to help the feature highlight the text in production. Check that these strings are not broken. This seems especially possible in non-Latin languages, like Arabic and Bengali.
- If you see any general patterns, e.g. the "context before" and "context after" fields are always broken, please explain that with examples in a comment on this task.