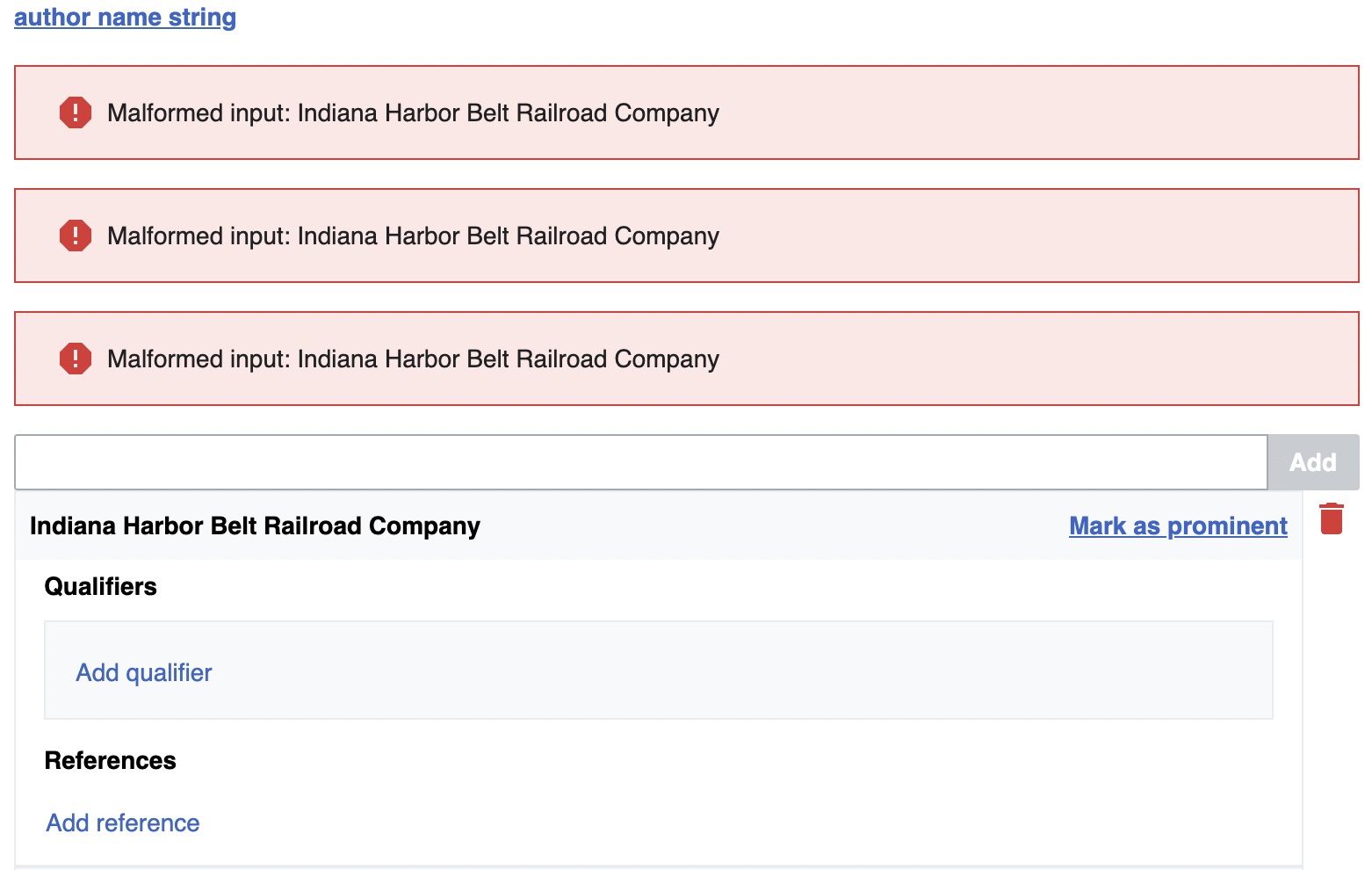
I suggest to trim leading/trailing spaces around statements of string type, and apply unicode normalization.
Due to a c&p error I added some trainling spaces at a VIAF statement and had to remove them with an extra edit, see URL.
Example URL: https://www.wikidata.org/w/index.php?title=Q6486700&diff=10051134&oldid=10051107
Other issues:
- CR
- unprintable characters (if not included in unicode normalization)