Fundraising tech are working on a patch.
| Pcoombe | |
| Dec 4 2014, 6:42 PM |
| F18508: Screenshot_2014-12-04_10.39.12.png | |
| Dec 4 2014, 6:42 PM |
Fundraising tech are working on a patch.
Update: all the changes have been pushed from fr-tech, and we're waiting to get re-indexed by google.
Mainly, AFAIK:
https://gerrit.wikimedia.org/r/177587 was replaced by a core change and then reverted
Excerpt from #wikimedia-operations
ori> AndyRussG, awight: https://support.google.com/webmasters/answer/66355?hl=en
ori> "Cloaking refers to the practice of presenting different content or URLs to human users and search engines. Cloaking is considered a violation of Google’s Webmaster Guidelines because it provides our users with different results than they expected."
ori> be sure to coordinate, because it sounds like we have multiple fronts here
+K4-713> ori: Definitely many conversations happening at the same time right now. As we're still waiting to hear back from their people, I don't think we want to roll anything back before we actually talk to them.
Copying some comments by @matmarex and @Umherirrender.
Umherirrender said:
See also T36593
I did not like this, because there are so many crawler on the web, which may not using the same comment to ignore content. But maybe for the moment this is a way to go.
Bartosz Dziewoński said:
Same here, I do not like this either. I understand the reasoning (although having a corresponding bug report would be nice…), but I still don't like it. We haven't had to do this before, why do we have to now?
Awight said:
Sorry, I should have commented here that we reverted this change in Ia522064df15b959e22e81abe2c607687ec2a29cb -- the new implementation is Id6bf279e590409b3464c363ee16442f4eb0dc186
Rumor is that Google deployed a new Javascript engine in the past week, apparently it is capable of rendering our banners.
Another theory is that we changed the way we serve banners, and the new endpoint was not disallowed in metawiki/robots.txt.
What's the status here, @atgo?
For the record, this is what Adam (FR-Tech) pushed out yesterday:
Stop banners showing up in search results
* {{gerrit|177598}} Make spiders ignore BannerLoader and RecordImpression
* {{gerrit|177589}} Prevent Google indexing of the SiteNotice div
* <s>{{gerrit|177669}}</s> (deployed and reverted)
* {{gerrit|177672}}
641cda3e9a8cbe7eefed75f0679057a32e1db0a8 Don't use UNIX timestamp for wgNoticeOldCookieApocalypse config
37473be4b4ca309c1f465e60b95c6f5c51199109 Deprecate old GeoIP HEAD thing
329443f9b3562bc776c6382a09e4552125d21152 No need to quantize throttling any more.
87a5f77199e5b1101a8b5f9de6ad615ef4eaafc2 Move subselects into the main pager query
33ed46b89bd2c1735ff26a85fa004f0c2d2dd79b Simplify Campaign editor banner list
5b4a0802f1cd7046df19cd3d018a86599c7da3de Small fixups
a12c95e830cc8998f0d1aba2339f6611efb36697 Revert "Don't insert banner for bots"and separately
* 177702 revert admin optimization
tl;dr fr-tech pushed the necessary changes yesterday and we are waiting for google to tell us if there's something else we need to do. From there, they'll still need to re-index the effected pages.
Longer:
[1] - http://webcache.googleusercontent.com/search?q=cache:Uf5lKyfNmTAJ:en.wikipedia.org/robots.txt+&cd=1&hl=en&ct=clnk&gl=us
[2] - http://en.wikipedia.org/robots.txt
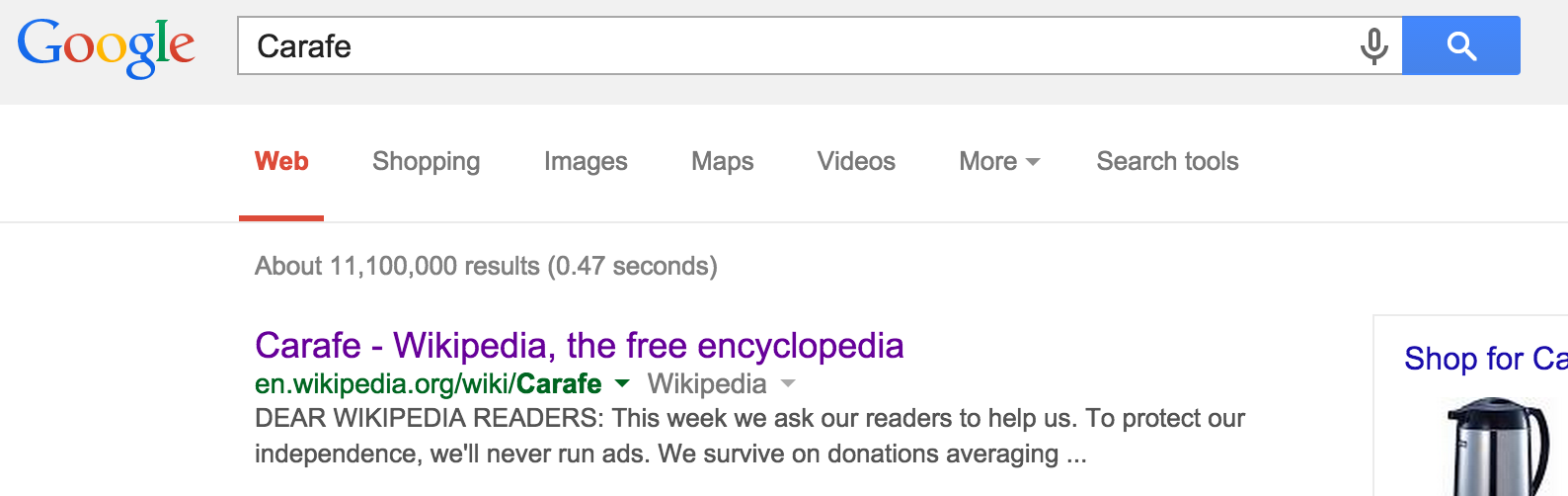
It's now returning 8,710,000 results for the "DEAR WIKIPEDIA READERS: You're probably busy, so we'll get right to it. This week we ask our readers to help us. This week we ask our readers to protect our site:en.wikipedia.org" search.
The search results are a little strange, taking the pages that are returned for the above search, and attempting to find them using Google and the page title, returns a mix of results. Results for some pages return the "DEAR WIKIPEDIA READERS..." excerpt but other pages return a sensible, expected excerpt, so it's not just a specific search for the fundraising banner text that returns results featuring the banner text.
Is that an indication that Google is gradually updating our results, or is the increasing page count something to be concerned about ?
We have been able to confirm that our fixes (deployed Thursday) solved the issue on our end and that Google picked up the updated robots.txt file on Dec 4. Google is now re-crawling, but this takes time. We've asked contacts at Google to see if there's any way to accelerate.
Searching for 'site:wikipedia.org "Dear Wikipedia readers"' now returns 663,000 results, down from 936,000 yesterday and 1,190,000 on Friday. Woo!
Also, from @Eloquence on wikimedia-l: "Please note that Google uses a distributed index, and depending where you are geographically, and where Google sends you based on server load, you will get inconsistent results from query to query. See this paper for a bit more detail on how these index inconsistencies manifest:
Just another update - we're down to 318,000 results from the search 'site:wikipedia.org "Dear Wikipedia readers"'. It's been steadily declining since the fix went out a week ago as Google re-indexes.
I'll close this task once the number has gone to 0, hopefully early next week.
Still edging down, now at 88,100.
https://www.google.com/search?q=%22DEAR+WIKIPEDIA+READERS%22+site:en.wikipedia.org
It looks like this is taken care of and our fix was effective.
It's still possible to get some results as the changes propagate to all of the google servers, but we're confident this will die off shortly.