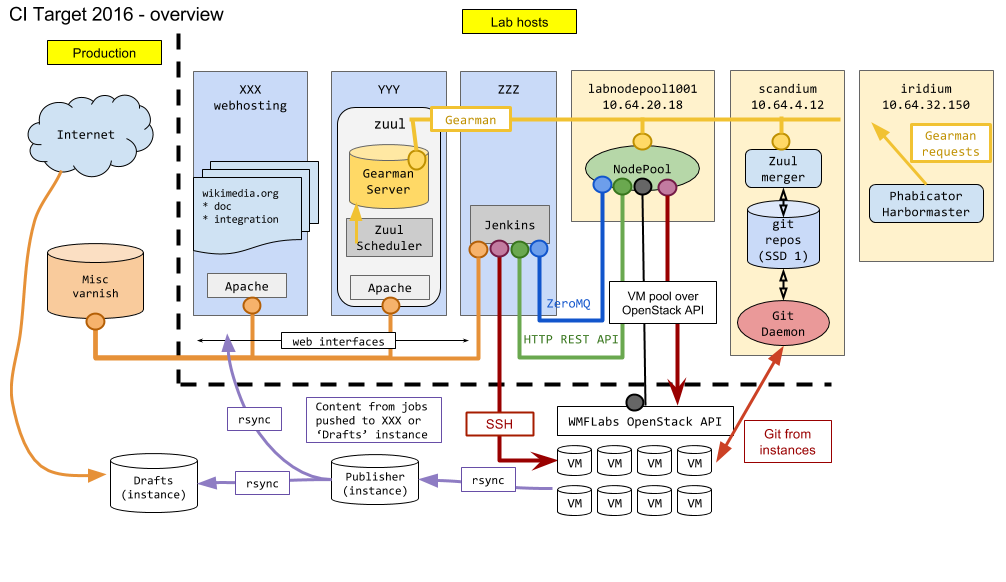
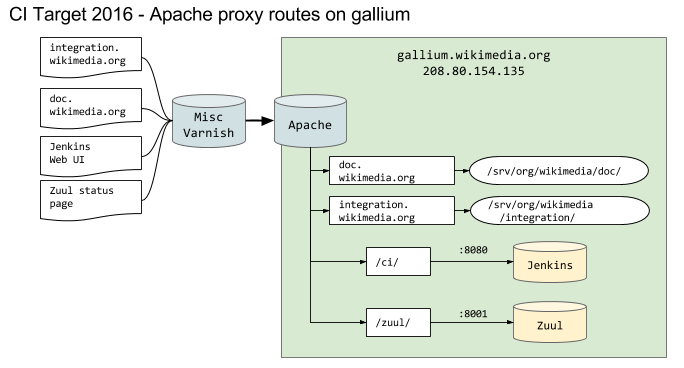
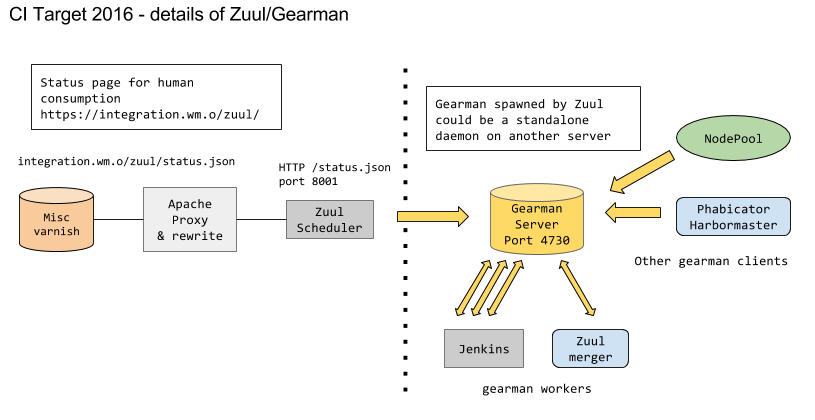
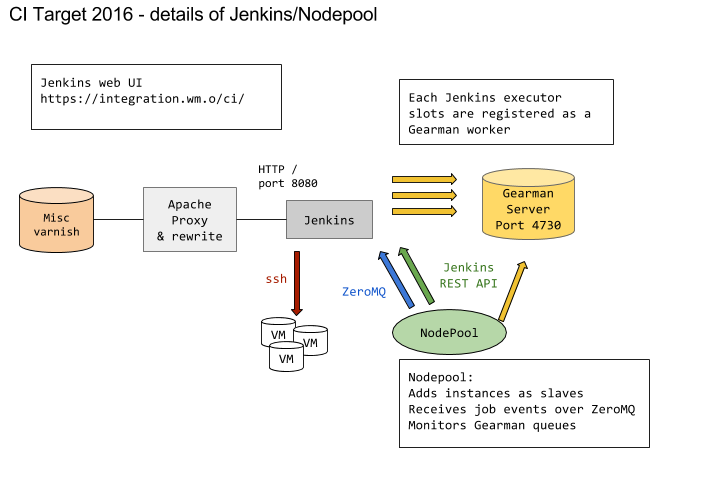
gallium.wikimedia.org has to be phased out. We need a document covering the target architecture that would be the foundation to let us do the migration and complete the host decommissioning.
Steps:
- Diagrams of all components
| Google drawings |
|---|
| Apache routing |
| Jenkins flows |
| Zuul / Gearman |
| Doc / coverage publishing |
- Architecture document on wiki
- CI Target 2016 - architecture (Google drawing)
- Team review / approval
- netops approval