We track clicks from our emails through donate.wiki. Clicks are recorded using eventlogging and logged on pgehres, and can be viewed using this query (this is sample data from the last 24 hours):
select d.utm_source, sum(d.count) from donatewiki_counts d where utm_source like 'sp5505%' group by utm_source;
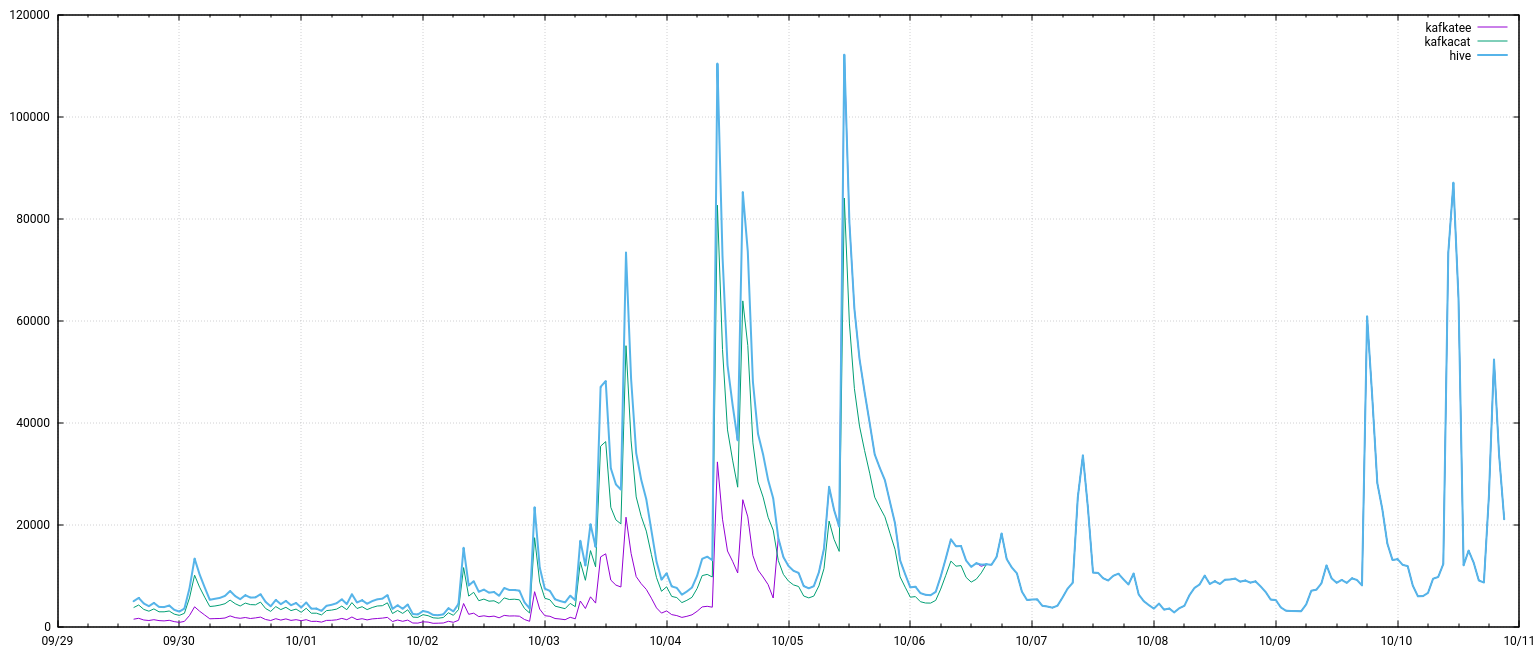
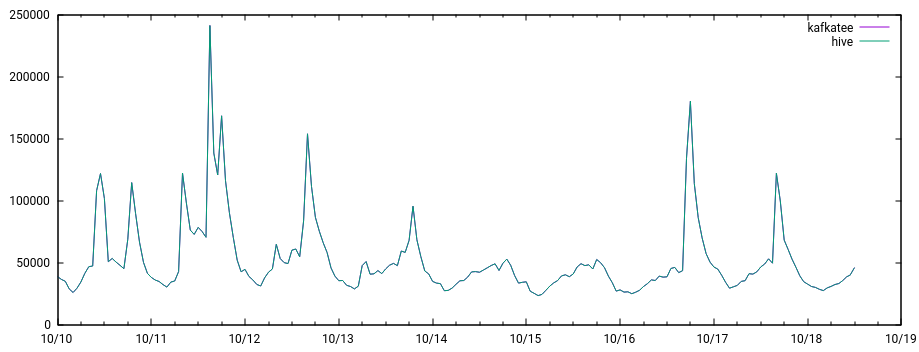
Since 9/28, the number of clicks counted has been less than the total number of donations, sometimes by a significant amount. See rows 35 and down, columns S and V:
https://docs.google.com/spreadsheets/d/196TfsBiSTHoWz56u6IuI4MZCnWleq6hsbHhGSrzkSQs/edit#gid=1050206810
This has applied broadly to all email stats since 9/28, using different languages and email templates, so I think there must be something broken on the landing page. Our Big English campaign just launched, and we really need all our data at our disposal. Can someone take a look at this?
Here is a sample email URL. The last 2 parameters were added for clicktracking:
https://donate.wikimedia.org/w/index.php?title=Special:LandingPage&country=US&uselang=&utm_medium=email&utm_source=sp55053343&utm_campaign=C1718_Email1&appeal=Appeal-JimmyQuote&hpc=%%highest_usd_amount%%&contact_id=%%CONTACTID%%&link_id=3