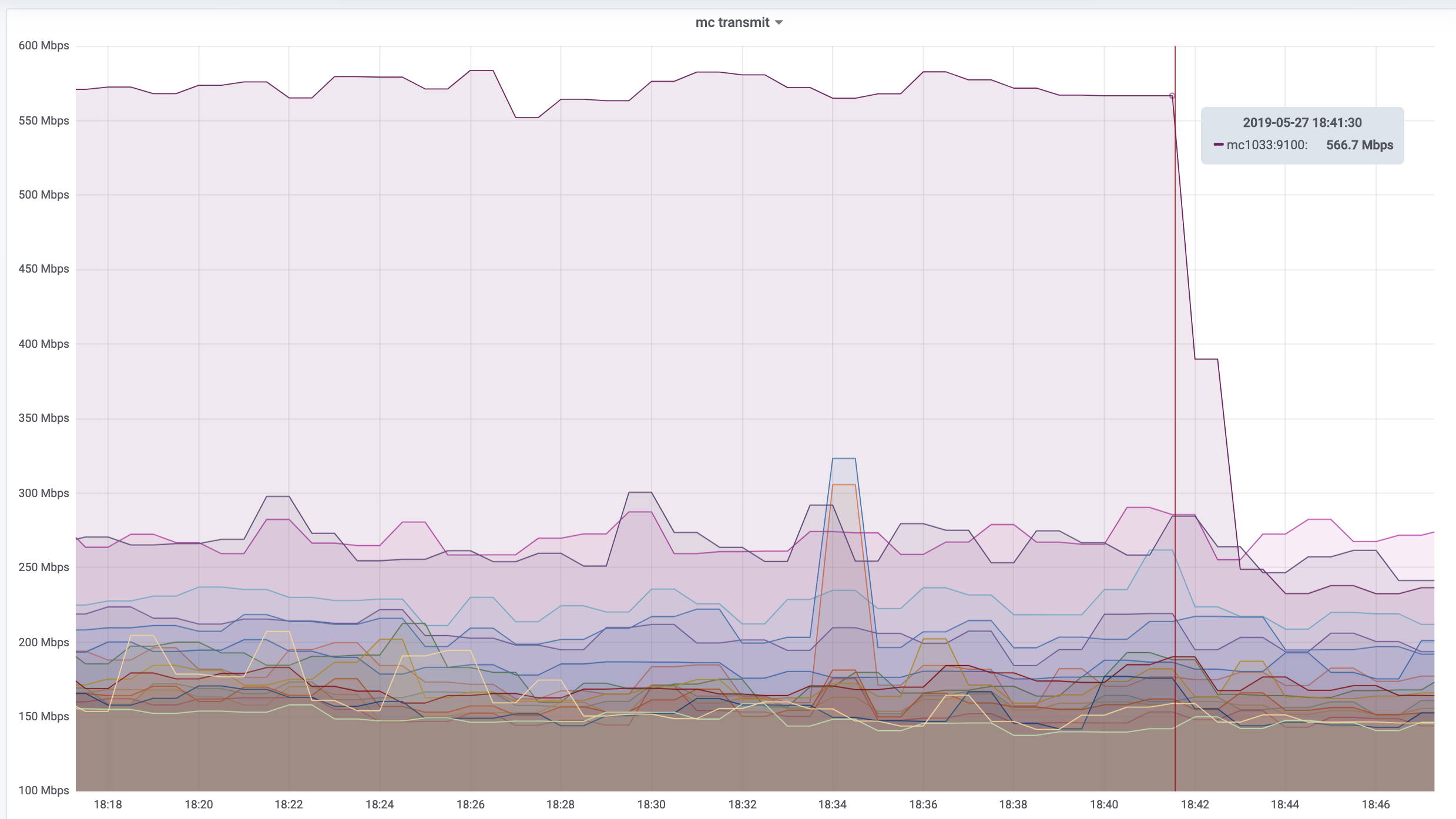
@Addshore alerted us that from his dashboard it seems that tx bandwidth usage for mc1033 spiked on 2019-05-02 19:26 UTC.
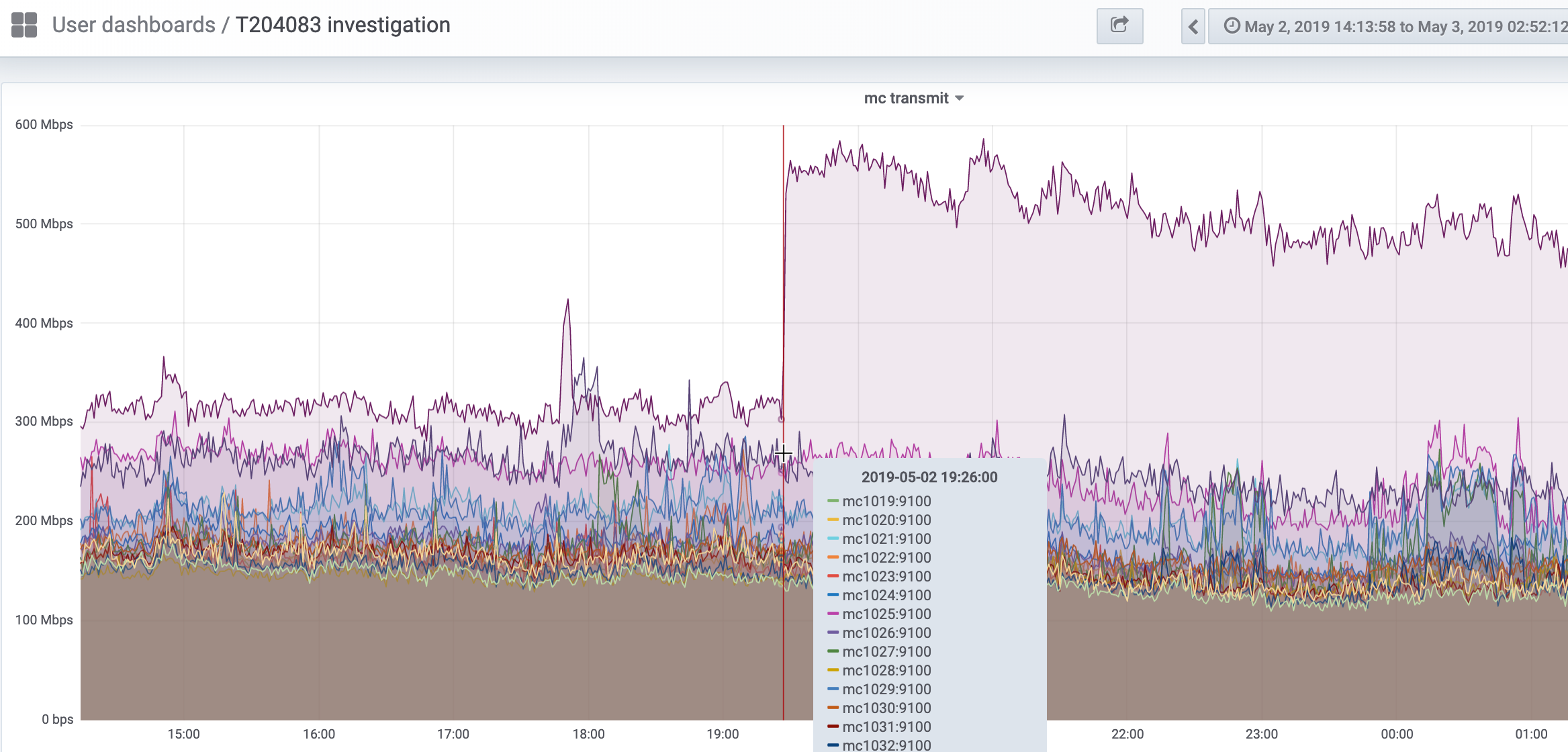
In T97368 a similar pattern was observed and investigated, but it might not be related.
From SAL, we see 1.34.0-wmf.3 was deployed at that time, so new keys might be involved.