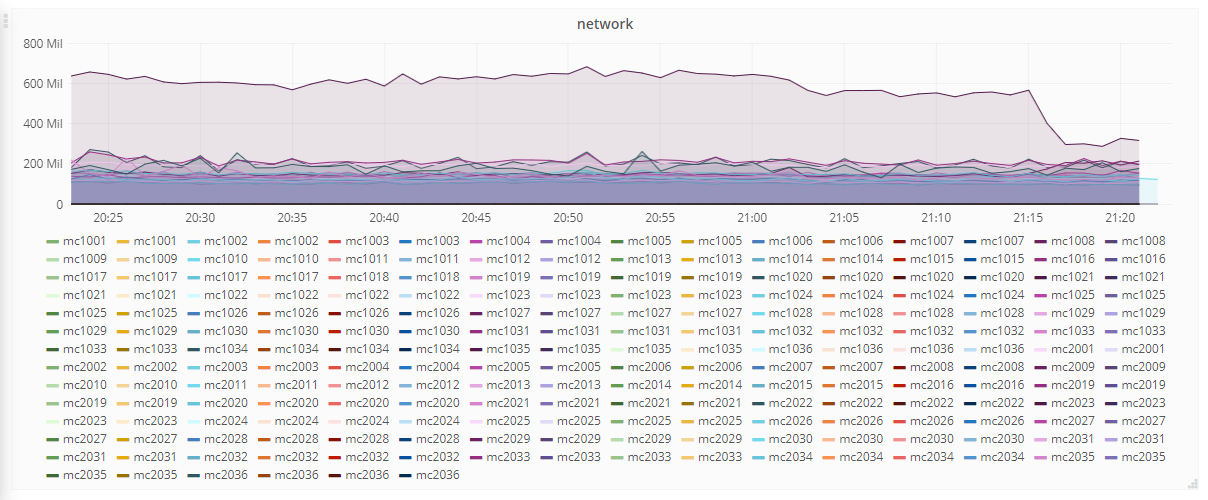
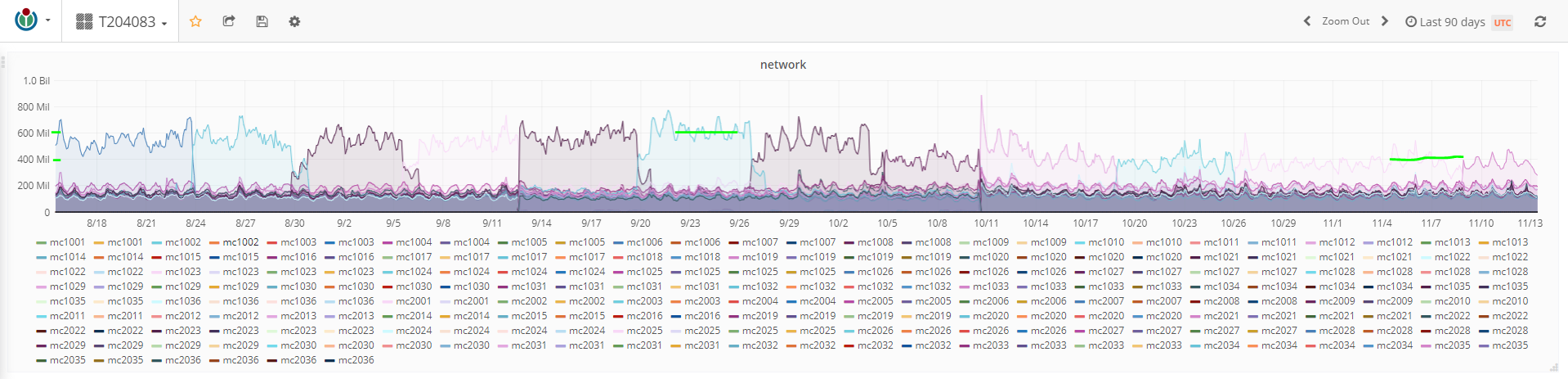
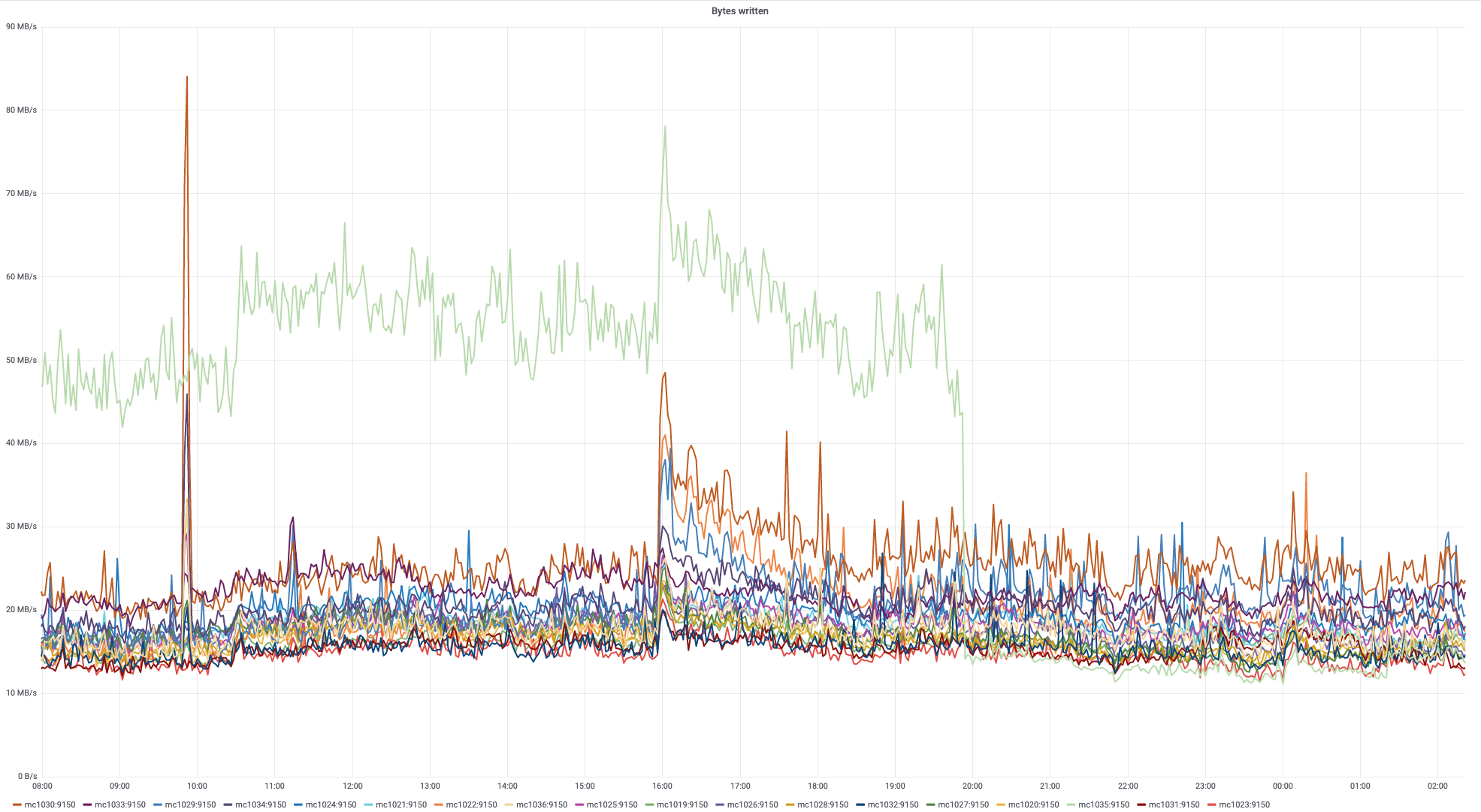
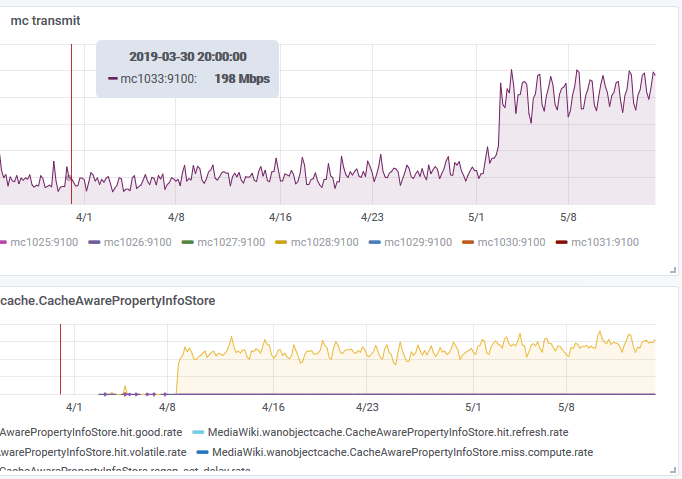
While this is not a problem now, I see PropertyInfoStore becoming a performance problem rather sooner than later, especially if we implement identifier linking on top of it and P553 finally gets split up (which it really really should).
We should have an implementation that doesn't require loading all infos from memcached (CachingPropertyInfoStore) but also doesn't end up making to many round trips to some form of storage.
This will probably be a problem very similar to the one we had with SiteList, but having a static file cache isn't a possible solution here.
https://grafana.wikimedia.org/d/000000574/t204083-investigation shows the excessive traffic moving around the various memcached hosts for the last 1 year.
Final acceptance criteria
- TBA other points
- Write an ADR for what was done in Wikibase - 4 hours spike