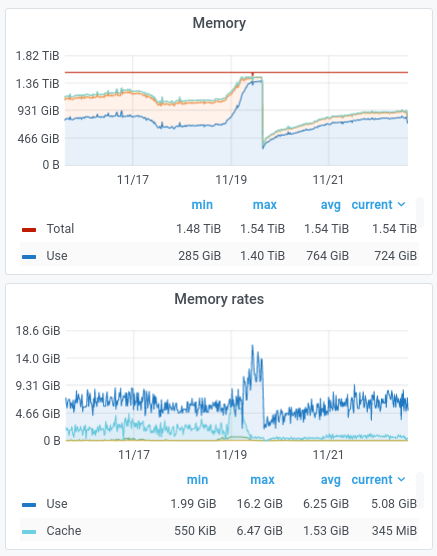
Impact
1.38.0-wmf.9 was deployed on all wikis on 2021-11-18 20:43 UTC. From that point on the following things have been noticed:
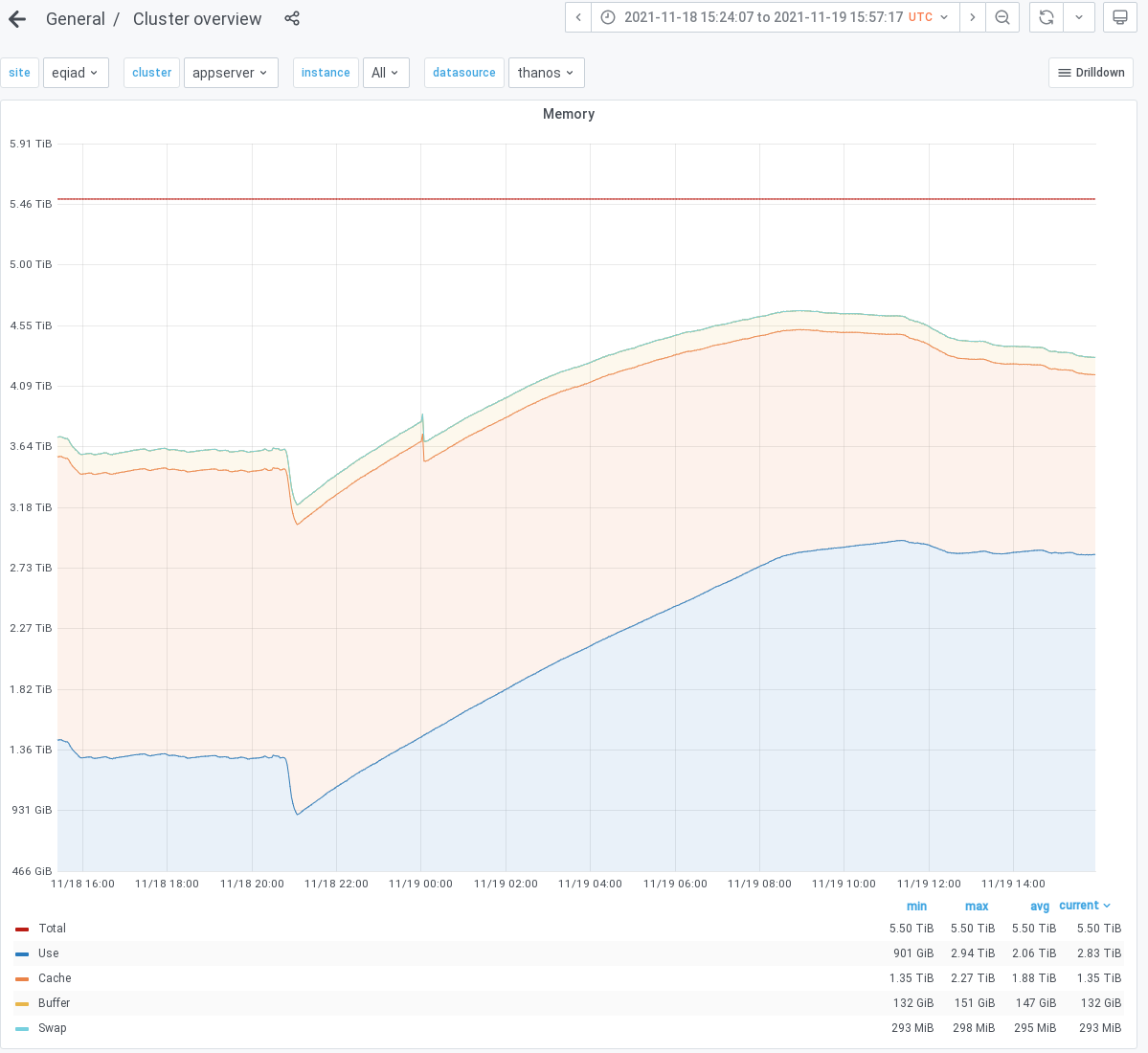
- Memory usage on the appserver cluster has spiked in ~12[1] hours to the highest it has ever been in the last 60 days. [2]. For now the memory usage across the cluster seems to have stabilized to ~2 times the usual amount (2.8TB vs 1.37TB). That behavior may or may not last. It can not be ruled out that we jump to even higher levels of memory usage.
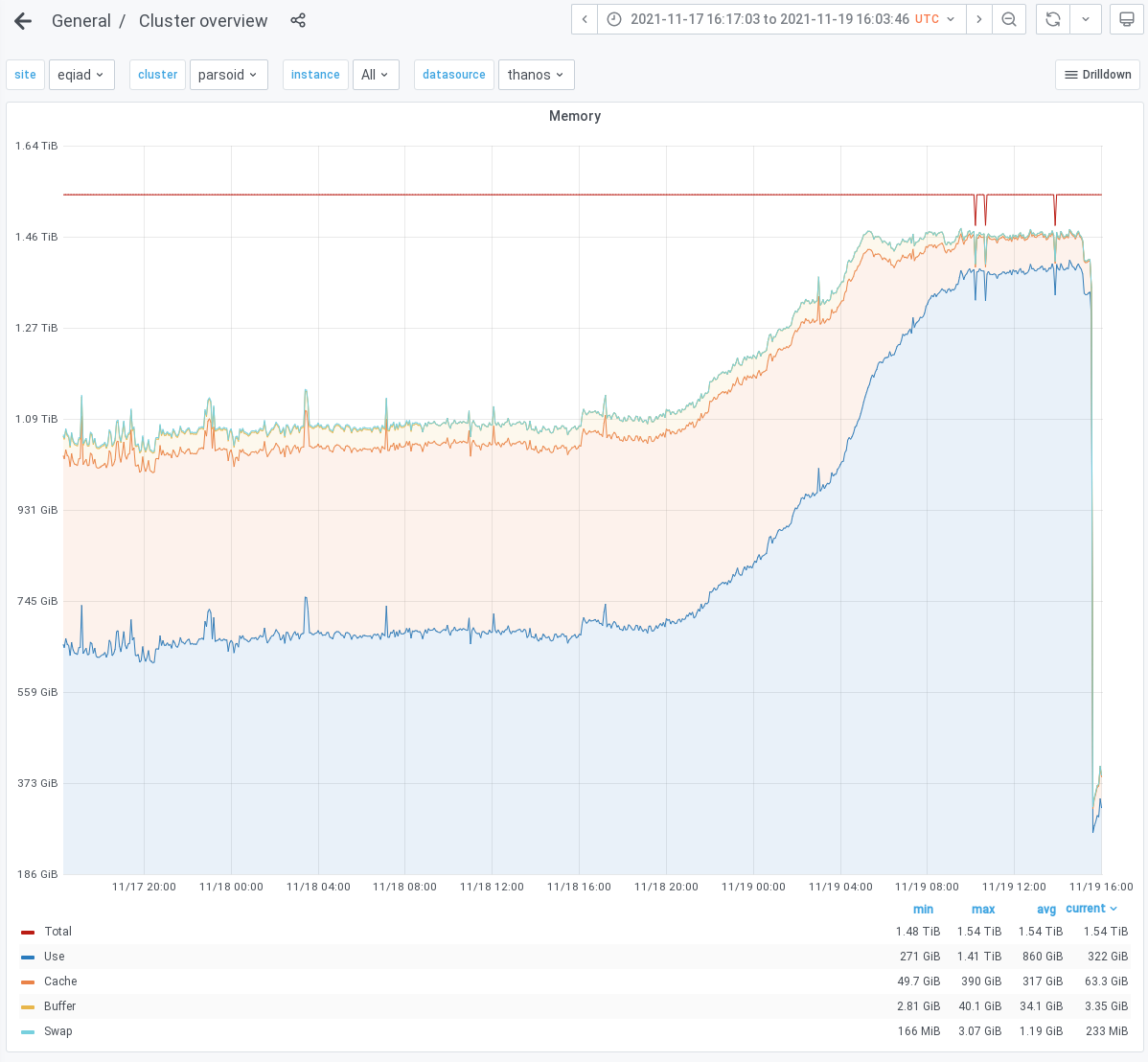
- The parsoid cluster experienced a similar memory increase[3], [4], but potentially coupled with an increased requested rate that is still being investigated ended up in triggering Out-Of-Memory events leading to failed requests, monitoring issues and the need for SREs to intervene, performing a rolling restart of php fpm on most of the cluster. The window from which the memory increase started to memory pressure and errors is again ~12h.
My 2 cents says revert in order to have a weekend without outages and pages, unless it's possible to find out the cause.
Notes
[1] https://grafana.wikimedia.org/d/000000607/cluster-overview?viewPanel=86&orgId=1&from=1637249047069&to=1637337437853&var-site=eqiad&var-cluster=appserver&var-instance=All&var-datasource=thanos
[2] https://grafana.wikimedia.org/d/000000607/cluster-overview?viewPanel=86&orgId=1&from=now-60d&to=now&var-site=eqiad&var-cluster=appserver&var-instance=All&var-datasource=thanos
[3] https://grafana.wikimedia.org/d/000000607/cluster-overview?viewPanel=86&orgId=1&from=1637165823022&to=1637337826709&var-site=eqiad&var-cluster=parsoid&var-instance=All&var-datasource=thanos