Error
- mwversion: 1.38.0-wmf.12
- reqId: 879eb71a-4a68-4ab7-8939-d257ec7e5f99
- Find reqId in Logstash
normalized_message
Out of memory (allocated 39845888) (tried to allocate 131072 bytes) in OutputHandler.php
exception.trace
#0 [internal function]: unknown() #1 /srv/mediawiki/php-1.38.0-wmf.12/includes/OutputHandler.php(163): gzencode() #2 /srv/mediawiki/php-1.38.0-wmf.12/includes/OutputHandler.php(78): MediaWiki\OutputHandler::handleGzip() #3 [internal function]: MediaWiki\OutputHandler::handle()
Notes
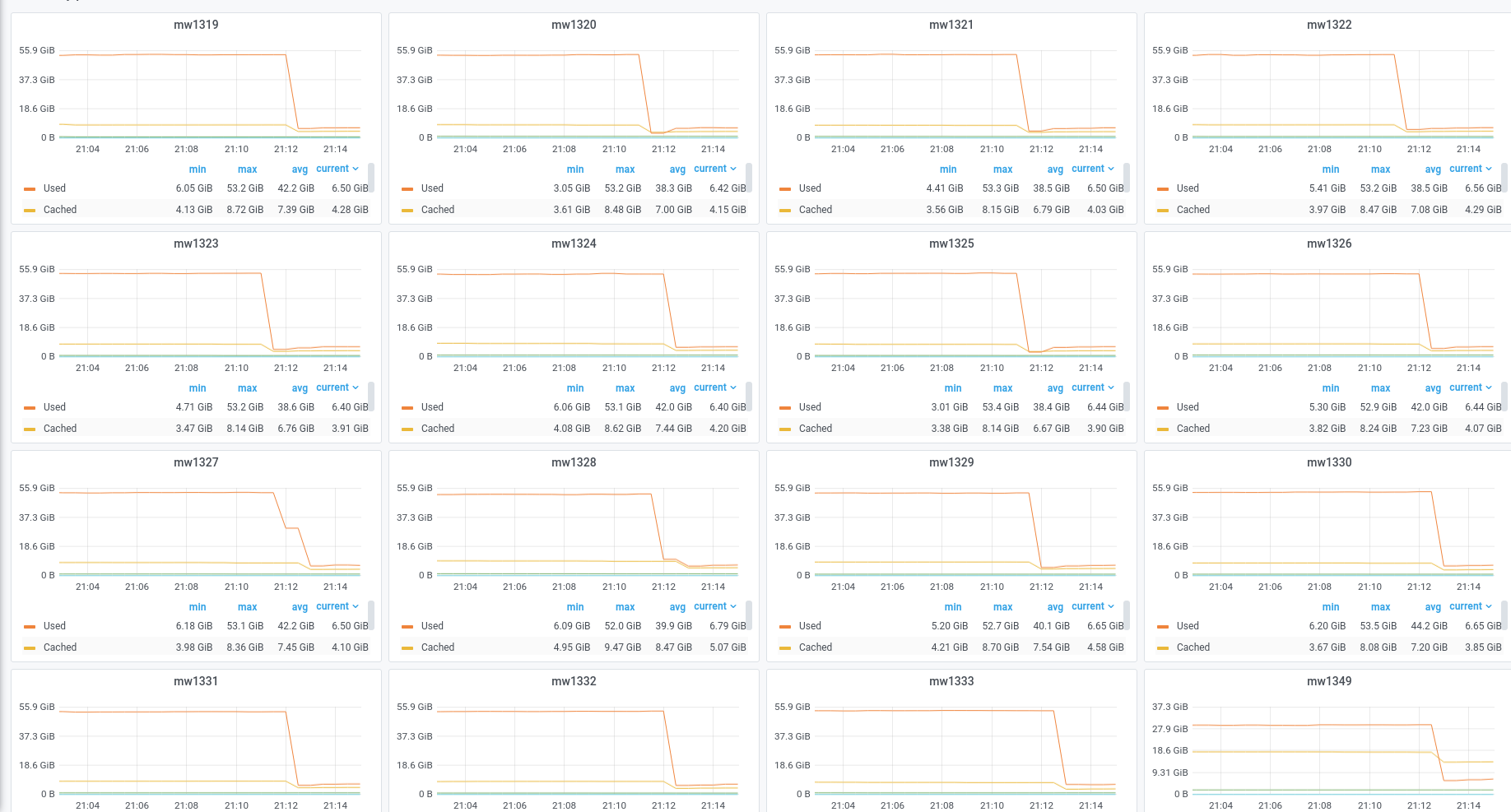
333 of errors like this one in the last hour.
https://logstash.wikimedia.org/goto/92bd66749f1813b1e88d89fc7b80fa42