We need to update the documentation of our high-level data model to reflect reality again.
Description
Description
Details
Details
- Reference
- bz73603
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T241215 Improve Wikibase lower and mid level documentation | |||
| Open | None | T75604 [Story] create documentation of php data model | |||
| Resolved | None | T75606 update documentation of js data model | |||
| Invalid | daniel | T75603 [Story] update documentation of high-level data model | |||
| Invalid | None | T96587 [Task] The data model specification should cover the notion of alias IDs (redirects) | |||
| Invalid | None | T98598 [Story] Overhaul documentation of data values | |||
| Invalid | None | T96679 [Task] Put sources of datamodel diagrams into the respective code repositories | |||
| Invalid | None | T96681 [Task] Review and polish new version of data model primer |
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
Comment Actions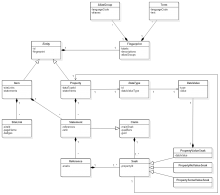
(The low-level view can be found on T75604.)
Trying to capture a high-level, conceptual view on the data model; I would like to use that for documentation. Please comment:
(The low-level view can be found on T75604.)
Comment Actions
We currently have 2 documents for this (the full one and the primer). We should consolidate and not have 2 anymore after this.
Comment Actions
- There is no change yet that strives to get rid of the primer.
- There needs to be proper visualization (see https://phabricator.wikimedia.org/T75603#1052472)
- Spelling needs to be standardized (see also T89350)
- Documentation needs to interact with a glossary (T72763)
- DataTypes documentation should be extracted
- DataValues documentation should be extracted
- As of now, "Fingerprint" was made an integral part of the data model as explained in T87237. Unless there is a decision to ditch the concept of Fingerprint, it should be part of the data model documentation.
- Some documentation is wrong or should be updated: For example, ReferenceRecord should be renamed to Reference; 'ItemDescription(' Item [MultilingualTextValue] [MultilingualTextValue] [MultilingualMultiTextValue] {Statement} ')' -- appears to be misleading if not wrong as no actual MultilingualTextValue DataValue is used just to begin with.
These are just things I noticed during a quick scan. There is a lot that can be improved. In any way, it would be good to at least have the referenced tasks off the table first.
Comment Actions
As I am not sure whether I should just go ahead an edit as to my perceptions, see also: T92365
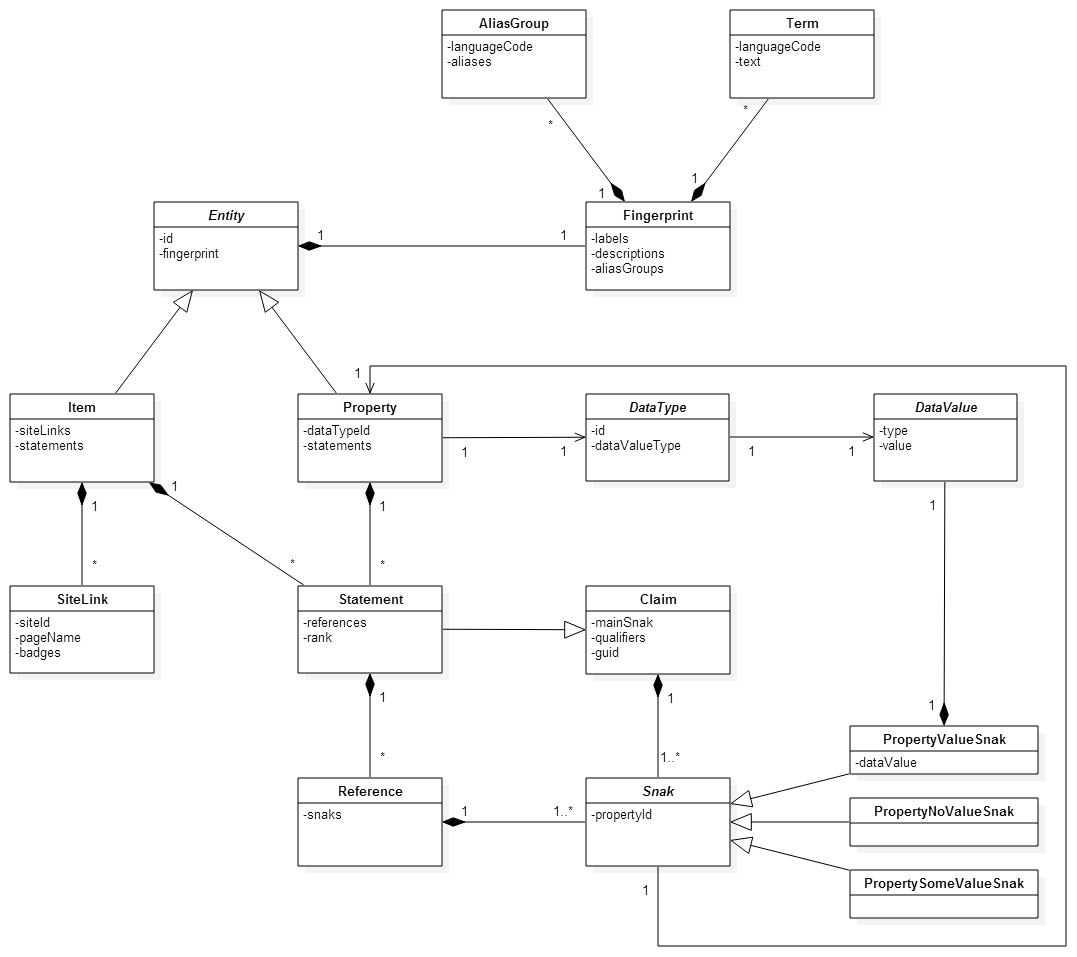
Comment Actions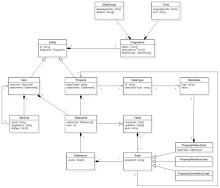
Fisch and me reassesed the diagramm.
The boulder that struck us / me is -- just speaking for myself (focus all the hate on me!): I think T87388 is wrong. Finally getting that insight at this very moment is pretty stupid as I totally was convinced of removing that useless Claim is the way to go. The argument is that Claim is just some kind of useless container. Technically, it is, but logically, it fulfills an important role. However, as to Jeroen has been driving into that direction already: Claim should, of course, be aggregated by Statement. I never got the argument for that until now, although it is quite obvious (I guess) when explained like that: The Qualifiers relate to the Main Snak. This relationship is expressed intrinsically by aggregating Main Snak and Qualifiers in a dedicated class that, as an alternative, could also be named "Main Snak". By moving Main Snak and Qualifiers to Statement this logical relationship gets lost. Qualifiers become an attribute of the Statement, hence the aggregation of Main Snak, References and Rank alike. OK, I know, that does not belong here and probably no one wants to consider that just now... but, well, that's something diagrams can be quite an enlightment for...
Comment Actions
I don't see the semantic difference between qualifying the Main Snak or the Statement. Qualifying the Main Snak still does not leave any part of the Statement that retains full meaning without the qualifiers. I.e. the structural container argument is symmetric to the semantic argument, removing claim can be done as it is not structurally needed nor changes the semantics.
Comment Actions
I updated the globe coordinates section, and looked through the rest, which overall generally looks ok to me.
Obviously, the time section is still unclear, in some aspects. I also think coordinate precision could be defined more clearly and perhaps an example would help.
Comment Actions
I would like to see https://www.mediawiki.org/wiki/Wikibase/DataModel/Primer updated as well.
the data model page is dense with text in some places, so for those who want an overview, the summary (primer) is also important!
Comment Actions
@Snaterlicious It's great you're working on this. Is this diagram and the one in T75604: [Story] create documentation of php data model going to appear or be linked from https://www.mediawiki.org/wiki/Wikibase/DataModel ?
FWIW Krinkle recently updated the MediaWiki DB schema diagram. T91859: Update diagram of core database tables to MediaWiki 1.24 describes how he did it with MySQL Workbench, maybe that has some useful ideas. Make sure whatever tools and techniques you're using to build these diagrams are clearly associated with them, the way he documented how to rebuild the MW table diagram.
Comment Actions
@Snaterlicious in the diagram, we should probably use EntityDescription, ItemDescription, and PropertyDescription, instead of Entity, Item, and Property. In the abstract data model, Entity, Item, and Property refer to the real-world concepts, not our data. An Item doesn't have Statements, and ItemDescription does.
Comment Actions
I reviewed the diff https://www.mediawiki.org/w/index.php?title=Wikibase%2FDataModel&diff=1510505&oldid=1422051:
- Looks ok overall.
- The word "auxiliary" is still in the document. I don't know what it means in our Wikibase/Wikidata world.
- Still a lot of open questions, most of them are already tracked in other tickets. For example: Does the time precision describe the precision of the time field or only the precision of the before and after fields? Can I have a timestamp that's, for example, precise to the second with a precision field that's set to a year, and what does this mean? I started a Google doc with all time related questions.
Comment Actions
It was used to mean qualifier. I replaced it: https://www.mediawiki.org/w/index.php?title=Wikibase/DataModel&diff=1519481&oldid=1519471
Comment Actions
Please see https://www.mediawiki.org/wiki/User:Henning_(WMDE)/Wikibase/Data_Model. Removed a lot of unnecessary complexity and integrated the primer. DataType as well as DataValue documentation would be extracted to separate pages.
I was indeed confused by the terminology of *Description which @daniel clarified above. Anyway, I think we can avoid that terminology by addressing T89350 which has been done in the page just referenced. For improving an maintaining documentation quality, addressing T92365 would be an important factor as well.
Comment Actions
@Snaterlicious Oh nice! I haven't read the document in detail yet, but from a first browsing, it seems to give a good overview.
There are a few issues, though:
- The documentation of the different bindings (JSON, PHP, JS, RDF, etc) should be prominently linked, and the relationship between them and the "abstract" model should be clear.
- "Fingerprint" should not be in the abstract model. I consider it a detail of the PHP binding, it's not present in JSON or RDF at all. We are also seriously considering getting rid of it.
- I miss the example screenshot from the old primer. It went a long way to clarify the idea behind the model, and how it is represented in the UI.
An then there's the question whether documentation describing the structure of the data model is sufficient. Markus' spec is an ontological document, describing the data model's relationship with the real world in formal terms. That kind of "philosophical binding" is not very useful in day to day programming work, but extremely important when trying to resolve conflicts and misunderstandings, map to other vocabularies, or extend the model. I think we still need that. So the new document would mostly be a replacement for the old primer. The more formal ontological embedding could be moved to a different title, like Wikibase\Data model\formal or some such.
Comment Actions
Discussed this with @Snaterlicious today. He said he'll work on his proposal a bit more. I think we can use that to replace the old primer. The formal model should probably be kept around. Some key points from the discussion:
- remove the notion of "Fingerprint" from the model. Instead, represent sets of labels, descriptions, and aliases separately, to accommodate future types of entities.
- Mention the notion of "unique features" in the model. Unique features for properties are (language + label) and (language + alias), unique features for items are (language + label + description) and (siteid + page). See also T74430
- Clarify the relationship between the logical data model (which is an abstract description of a data structure) and the conceptual schema (which is a semi-formal ontology of real world concepts).
Comment Actions
Very cool to see progress on this. Such a diagram is very helpful to people not familiar with the model yet.
Comment Actions
remove the notion of "Fingerprint" from the model. Instead, represent sets of labels, descriptions, and aliases separately, to accommodate future types of entities.
What is meant by this? Re-introducing LabelList and AliasList classes? Adding getLabelsList() and getDescriptionsList() to Item and Property? Or both? I'm certainly fine with the later. For the former I'd like to know what made people change their minds.
Note how that does not imply removing Fingerprint, which still retains its usefulness. It however does allow one to create a sensible diagram without including it.
Comment Actions
@JeroenDeDauw Removing Fingerprint from the abstract model does not imply removing it from the PHP model. I'm ambivalent about its usefulness as a structural component in the PHP implementation (and perhaps other implementations), but I'm convinced that it has no place in the abstract model. The abstract model should only contain things that are absolutely needed to describe the data we want to model. I don't see how we need Fingerprint, especially since it's somewhat misleading and inflexible in it's current form.
Comment Actions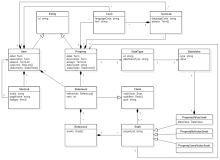
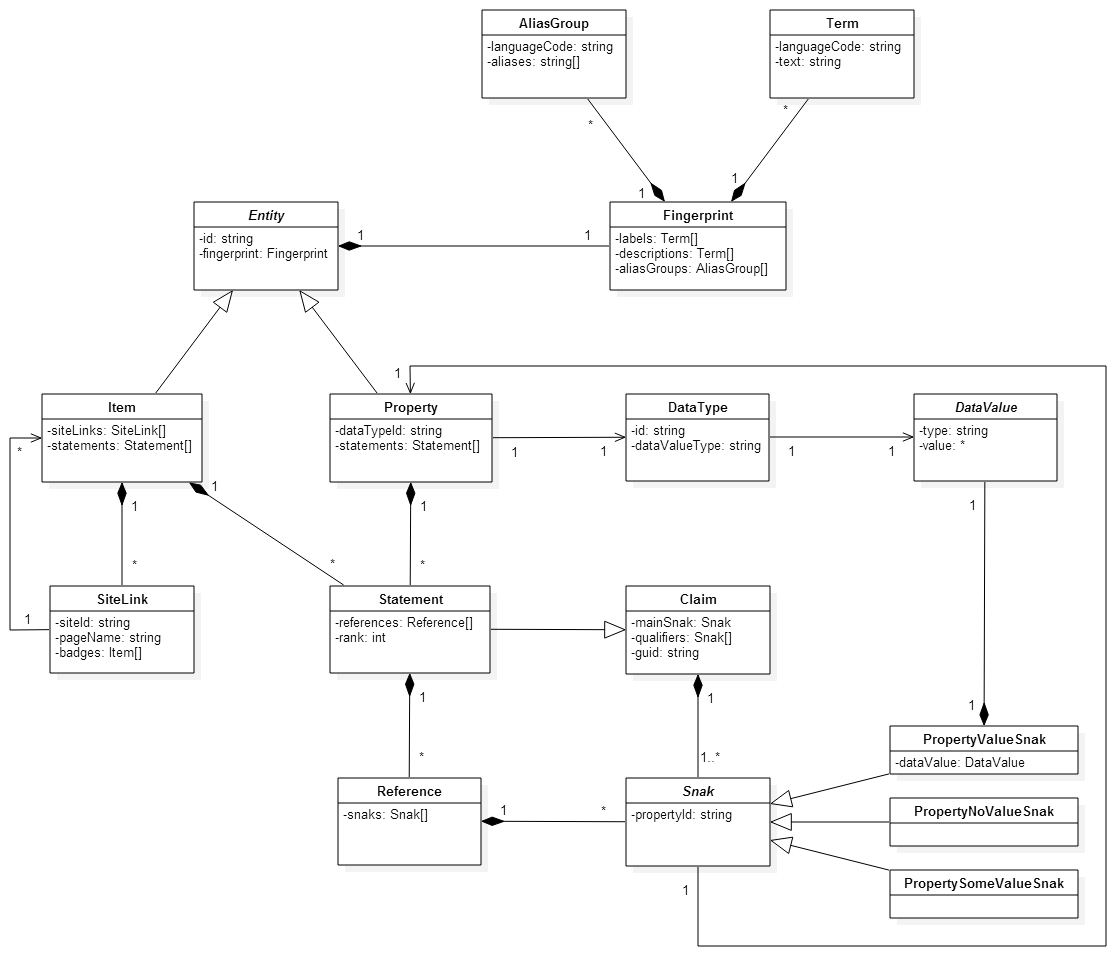
Updated high-level data model diagram:
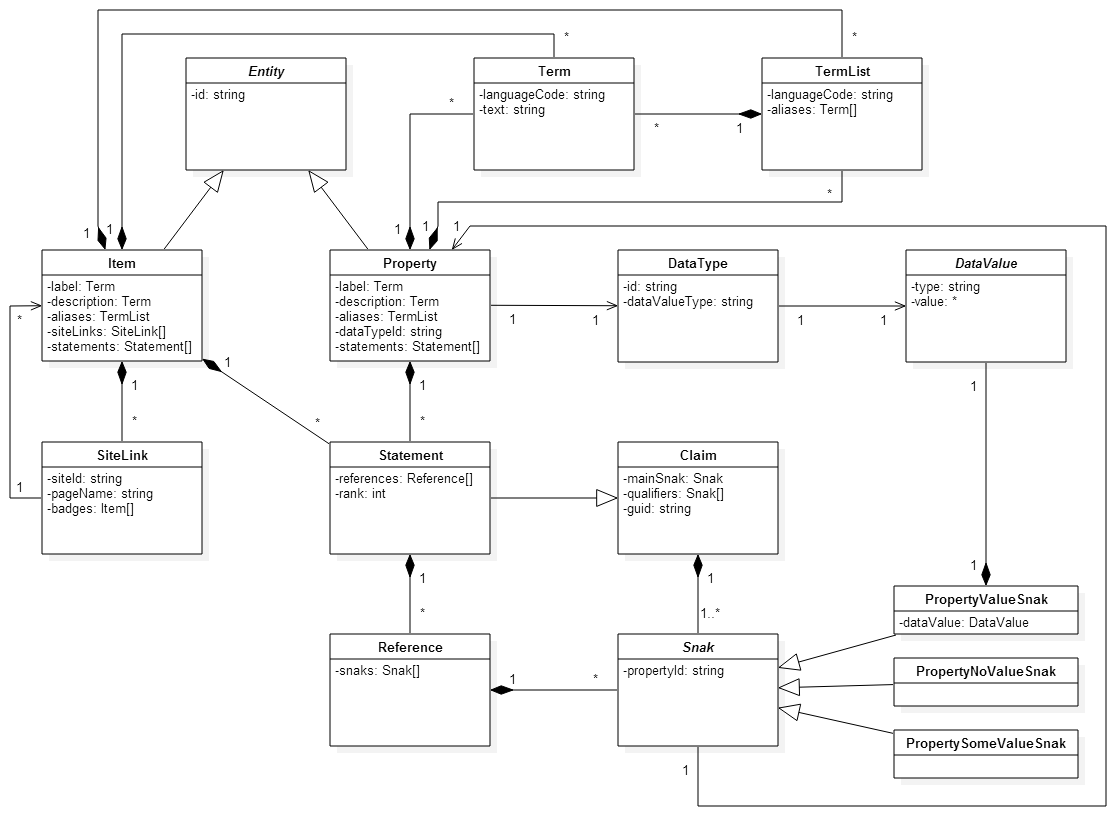
Can somebody formulate the reason(s) for the uniqueness contraints as I would not like to mention functionality without providing reasons? I guess all constraints except ( site id + page name ) are supposed to ensure identification. Why is ( site id + page name ) supposed to act as identifier?
Comment Actions
Can somebody formulate the reason(s) for the uniqueness contraints
I will try. Here is what I understand.
For properties:
- ( language + label ): Labels act as identifiers, because properties are usually shown with their label and nothing else (no id, no description) in property-value pairs.
- ( language + alias ):
I wonder where this comes from. Aliases are unique per entity, but different properties can have the same aliases. This is still useful in search results and suggesters, given they show perfect matches first.
For items:
- ( language + label + description ): This reflects what we learned from Wikipedia. Concepts with the same label exist (e.g. http://en.wikipedia.org/wiki/Albert_Einstein_(album) ) and must be allowed. The description is the tool to make these otherwise indistinguishable concepts distinguishable in search results and suggesters.
- ( siteid + page ): Each item should describe one (and only one) concept. So should each linked page. We know this is not true for all pages, but we decided that not having this constraint would be much more painful than having it. This reflects what was done with on-page sitelinks before: syncing sitelinks (e.g. via bot) got screwed if two enwiki pages pointed to the same dewiki page. The dewiki page can not point back to the two enwiki pages.
Comment Actions
Comments on the diagram:
- TermList does have an aliases field. Shouldn't that be named terms?
- For a second I wondered if dataTypeId: string should be dataType: DataType, but the string is fine.
- I think there is a second arrow from Snak to Claim missing.
Comment Actions
For a second I wondered if dataTypeId: string should be dataType: DataType, but the string is fine.
If I'm not mistaken we originally had it like that in the PHP DataModel, but then moved away from it due to binding that did not provide sufficient value.
Comment Actions
For properties:
- ( language + label ): Labels act as identifiers, because properties are usually shown with their label and nothing else (no id, no description) in property-value pairs.
- ( language + alias ): I wonder where this comes from. Aliases are unique per entity, but different properties can have the same aliases. This is still useful in search results and suggesters, given they show perfect matches first.
No, different properties should never have the same alias. In Wikitext (parser function, Lua), properties can be addressed by their alias, so the alias must act as an identifier, and be unique. I'm not sure we are actually enforcing this right now, but conceptually, this constraint exists. However, like most of the constraints we impose, this is not absolutely guaranteed. Violations could for instance be introduced through import of property definitions (which is one reason imports are disabled per default).
For items:
- ( language + label + description ): This reflects what we learned from Wikipedia. Concepts with the same label exist (e.g. http://en.wikipedia.org/wiki/Albert_Einstein_(album) ) and must be allowed. The description is the tool to make these otherwise indistinguishable concepts distinguishable in search results and suggesters.
- ( siteid + page ): Each item should describe one (and only one) concept. So should each linked page. We know this is not true for all pages, but we decided that not having this constraint would be much more painful than having it. This reflects what was done with on-page sitelinks before: syncing sitelinks (e.g. via bot) got screwed if two enwiki pages pointed to the same dewiki page. The dewiki page can not point back to the two enwiki pages.
Yes... Conceptually, every Wikipedia page in each language describes a concept. By Wikipedia rules, there cannot be two pages about the same concept in the same language; nor should a page describe two concepts (though this is a bit more loose). We assume that the same is true for other projects too (Commons, Wikivoyage, etc).
Practically, the one-to-one relationship allows us to manage language links semi-automatically, as Thiemo described.
For a second I wondered if dataTypeId: string should be dataType: DataType, but the string is fine.
If I'm not mistaken we originally had it like that in the PHP DataModel, but then moved away from it due to binding that did not provide sufficient value.
Conceptually, it refers to a DataType; for the abstract data model, it is not relevant whether this reference is using a string name, or an object reference. That distinction is only relevant for the documentation of the PHP binding.
Comment Actions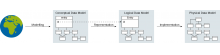
OK, thanks so far. Will add that information to the documentation draft.
As for conceptual data model <-> logical data model. Would something like the appended graphic, accompanied by some short explanation, be sufficient?

Comment Actions
I'm not sure we are actually enforcing this right now
We aren't: T89661: [Story] Enforce uniqueness of property aliases.
Conceptually, it refers to a DataType; for the abstract data model, it is not relevant whether this reference is using a string name, or an object reference. That distinction is only relevant for the documentation of the PHP binding.
It's not only relevant for PHP, it's relevant for everybody working with DataValue serializations. So I think this should be described as an object reference on the conceptual level, but it's already a string in the representation.
Would something like the appended graphic [...] be sufficient?
Love it.
Comment Actions
- ( siteid + page ): Each item should describe one (and only one) concept. So should each linked page. We know this is not true for all pages, but we decided that not having this constraint would be much more painful than having it. This reflects what was done with on-page sitelinks before: syncing sitelinks (e.g. via bot) got screwed if two enwiki pages pointed to the same dewiki page. The dewiki page can not point back to the two enwiki pages.
Yes... Conceptually, every Wikipedia page in each language describes a concept. By Wikipedia rules, there cannot be two pages about the same concept in the same language; nor should a page describe two concepts (though this is a bit more loose). We assume that the same is true for other projects too (Commons, Wikivoyage, etc).
Practically, the one-to-one relationship allows us to manage language links semi-automatically, as Thiemo described.
Follow-up on that for clarification: Does the uniqueness constraint ( site id + page ) have more to it than being a consequence of MediaWiki (in particular being used as Wikibase Client) not being able (and/or not intended per Wikipedia rules) to link to multiple pages of a single site?
I just wonder whether it is possible to explain the semi-automatic link management without explaining the concept of Repo/Client and mentioning the supposedly implicit assumption in Wikibase that Clients are MediaWiki instances.
Comment Actions
Would something like the appended graphic [...] be sufficient?
Very helpful, yes!
Follow-up on that for clarification: Does the uniqueness constraint ( site id + page ) have more to it than being a consequence of MediaWiki (in particular being used as Wikibase Client) not being able (and/or not intended per Wikipedia rules) to link to multiple pages of a single site?
Yes: the idea is that sitelinks represent descriptions of the same concept on other sites. If we had multiple items referencing the same page on another site, or multiple pages of a site per item, then the target page would not be describing the same concept. Wikipedia should be used as an example here, and the automatic language links can be mentioned, but do not need to be fully explained.
Comment Actions
I think this can be explained without mentioning MediaWiki:
- Items are meant to describe unique concepts.
- The sitelinks list is not just a weblinks section. Sitelinks are not meant to be a collection of all web links to pages that happen to describe the same concept.
- Sitelinks are meant to connect a Wikibase Repo to other sites that also describe one concept per page.
Does this help?
Comment Actions
OK, thanks. https://www.mediawiki.org/wiki/User:Henning_(WMDE)/Wikibase/Data_Model got updated.
Finally, I am just struggling about the relationship between this Data Model documentation draft and the glossary draft (T72763). So far, not all terms have been integrated into the DM documentation draft (i.e. Label, Description, Aliases, Site, page). Apart from the question whether or not those terms should be included in their full scope into the DM documentation, a glossary would, of course, allow terms not to be included in the DM documentation (i.e. terms of the physical data models like Fingerprint) to be explained in a central place. Apart from that, the conceptual difference between the DM documentation and a glossary would be that, in the DM documentation, terms may be explained within context whereas the glossary is supposed to explain terms in some isolated way. However, currently, the DM documentation draft is kind of written to explain the individual concepts in an isolated fashion. Hence, it would be just awesome to be able to automatically embed the respective DM documentation contents into a separate glossary but, technically, I do not think that is going to happen.
Any opinion on that?
Comment Actions
I think https://github.com/wmde/Wikiba.se/issues/33 is part of this task too. So I'm closing the issue there.