[13:06:03] <icinga-wm> PROBLEM - Host iridium is DOWN: PING CRITICAL - Packet loss = 100% [13:09:32] <icinga-wm> PROBLEM - PyBal backends health check on lvs1012 is CRITICAL: PYBAL CRITICAL - git-ssh4_22 - Could not depool server iridium-vcs.eqiad.wmnet because of too many down!: git-ssh6_22 - Could not depool server iridium-vcs.eqiad.wmnet because of too many down! [13:09:43] <icinga-wm> PROBLEM - PyBal backends health check on lvs1006 is CRITICAL: PYBAL CRITICAL - git-ssh4_22 - Could not depool server iridium-vcs.eqiad.wmnet because of too many down!: git-ssh6_22 - Could not depool server iridium-vcs.eqiad.wmnet because of too many down! [13:10:11] <icinga-wm> PROBLEM - PyBal backends health check on lvs1003 is CRITICAL: PYBAL CRITICAL - git-ssh4_22 - Could not depool server iridium-vcs.eqiad.wmnet because of too many down!: git-ssh6_22 - Could not depool server iridium-vcs.eqiad.wmnet because of too many down! [13:11:25] <matt_flaschen> YuviPanda, Phabricator is 503'ing for me. [13:15:08] <greg-g> matt_flaschen: 03:06 < icinga-wm> PROBLEM - Host iridium is DOWN: PING CRITICAL - Packet loss = 100% [13:15:12] <greg-g> so, yeah :/ [13:15:43] <greg-g> !log Phabricator is down [13:15:48] <morebots> Logged the message at https://wikitech.wikimedia.org/wiki/Server_Admin_Log, Master [13:18:09] * matt_flaschen has changed the topic to: Wikimedia Platform operations, serious stuff | Status: Phabricator DOWN | Log: http://bit.ly/wikisal | Channel logs: http://ur1.ca/edq22 | Ops Clinic Duty: yuvipanda [13:39:55] <Krenair> do ops get paged when hosts go down? I don't know how icinga is set up for this sort of thing [13:59:15] * Krinkle has changed the topic to: Wikimedia Platform operations, serious stuff | Status: Phabricator DOWN | Log: https://bit.ly/wikitech | Channel logs: http://ur1.ca/edq22 | Ops Clinic Duty: yuvipanda [14:02:07] <TimStarling> depends on the service [14:08:33] <TimStarling> it says it's powered off [14:11:39] <TimStarling> http://paste.tstarling.com/p/qbrBRb.html [14:12:37] <Krenair> the system powered itself off? [14:12:42] <TimStarling> apparently [14:12:47] <TimStarling> I guess I will try turning it on [14:13:40] <TimStarling> !log attempting to turn iridium back on via drac. "getraclog" says it powered itself off after resetting four times [14:13:44] <morebots> Logged the message at https://wikitech.wikimedia.org/wiki/Server_Admin_Log, Master [14:15:56] <TimStarling> I'm on the serial console now, it is booting [14:16:22] <icinga-wm> RECOVERY - Host iridium is UP: PING OK - Packet loss = 0%, RTA = 0.80 ms [14:16:45] <TimStarling> well, phab is back up [14:18:42] <TimStarling> !log iridium came back up, but mcelog reports high CPU temperature prior to the shutdown [14:18:46] <morebots> Logged the message at https://wikitech.wikimedia.org/wiki/Server_Admin_Log, Master [14:19:52] <icinga-wm> RECOVERY - PyBal backends health check on lvs1012 is OK: PYBAL OK - All pools are healthy [14:22:01] <icinga-wm> RECOVERY - PyBal backends health check on lvs1006 is OK: PYBAL OK - All pools are healthy [14:22:23] <icinga-wm> RECOVERY - PyBal backends health check on lvs1003 is OK: PYBAL OK - All pools are healthy
Description
Description
Related Objects
Related Objects
- Mentioned In
- T131775: codfw: (1) phabricator host (backup node)
Event Timeline
Comment Actions
There has been several severs with cpu heat issues over the last few months. Re-applying thermal paste has been an effective fix. Iridium is still under warranty however, I think first step is thermal paste.
Comment Actions
Some details from an email @tstarling sent out as a notice
...So I powered it up, and it came up, but /var/log/mcelog from prior to the shutdown showed it constantly coming in and out of CPU throttling due to high temperature:
http://paste.tstarling.com/p/TaLyCY.html
@greg, are you ok w/ @Cmjohnson taking this down for maint before the normal wednesday window? (spoiler is it may very well go down before then anyway...so it seems prudent)
Comment Actions
tossing your way because of the nature of the issue and need for immediate feedback for onsite
Comment Actions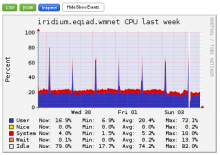
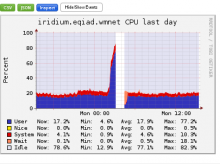
yeah, stab in the dark guess is it might happen again tonight after the dumps (I assume?) run.
When do you think it can happen, @Cmjohnson ? How long of a downtime?
See:
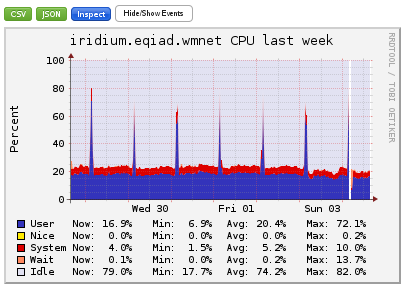
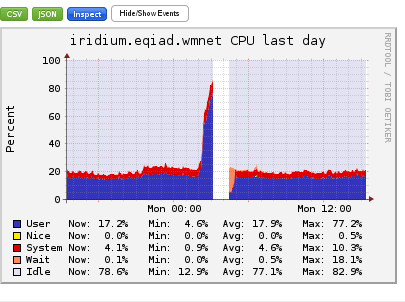
Comment Actions
Clean off the old thermal paste and reapplied. Let's monitor for the next few days. Leaving task open
Comment Actions
@Cmjohnson do we have a system to monitor temperature? lm_sensors comes to mind, also found out Diamond has a collector for IPMI data https://github.com/BrightcoveOS/Diamond/wiki/collectors-IPMISensorCollector