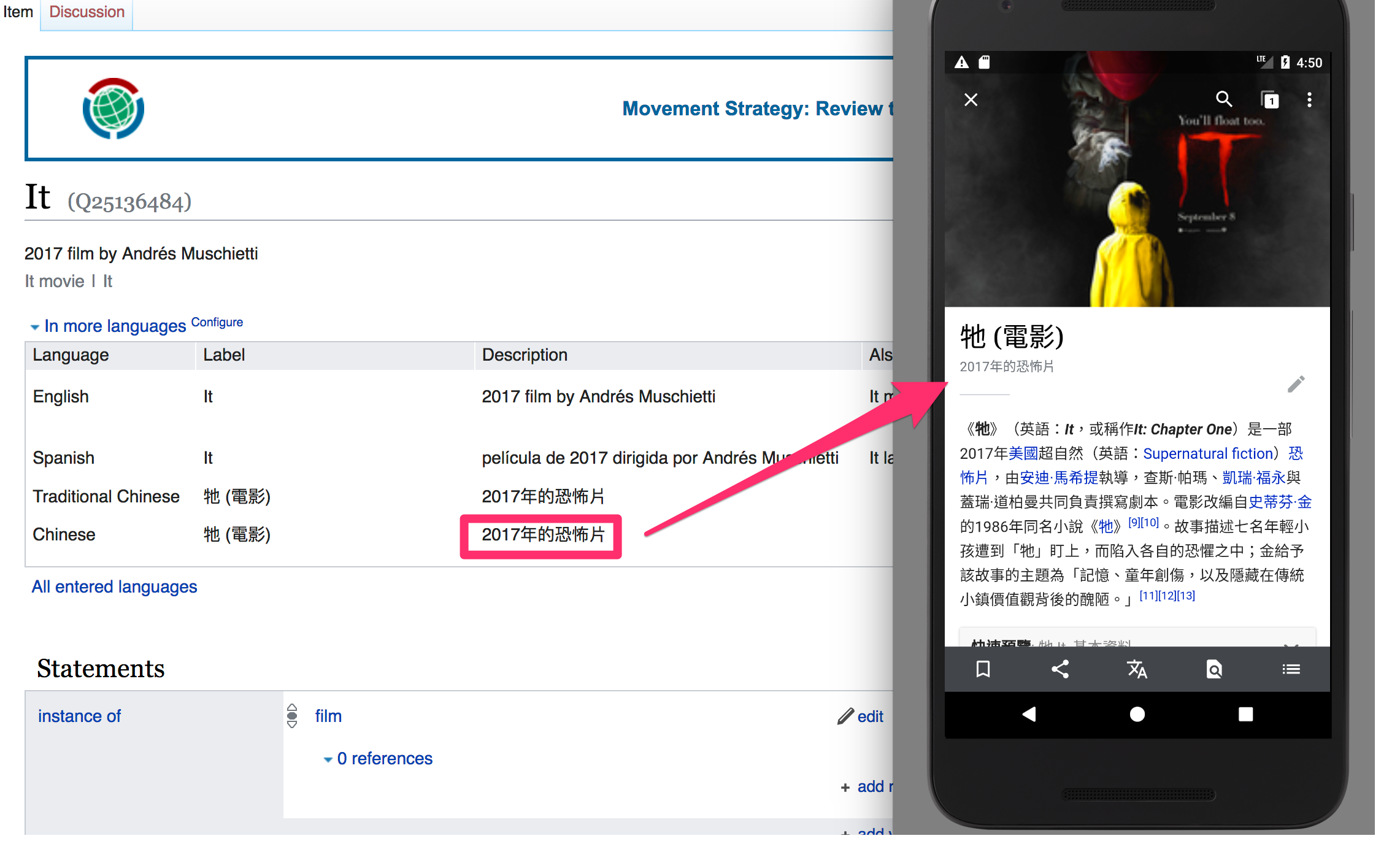
Steps to reproduce
- Go to the article on China using Simplified Chinese and note the Wikidata description.
- Change to view the article in Traditional Chinese and note the Wikidata description.
Expected
The description that should be shown when viewing in Traditional Chinese should be the description from the "Traditional Chinese" row in the Wikidata entry for China, and the same for Simplified Chinese.
Actual
The description shown is pulling from the "Chinese" row in Wikidata, so there are characters being used and displayed in one variant when the language is set to the other. (In the example of the "China" article, there are Simplified characters in the description "中华人民共和国" showing on the Traditional character variant of the article)