Error
Request ID: W6P5eArAIEsAAAYwlAIAAABI (https://commons.wikimedia.org/w/index.php?title=File:Kuindzhi_Sunflowers_Crimea_1880s.jpg&action=edit)
DBQuery error
Wikibase\Client\Usage\Sql\EntityUsageTable::addUsages 10.192.16.22 1213
Deadlock found when trying to get lock; try restarting transaction (10.192.16.22)
INSERT IGNORE INTO `wbc_entity_usage` (eu_page_id,eu_aspect,eu_entity_id) VALUES ('23650776','L.en','Q656'),('23650776','S','Q656'),('23650776','O','Q353628'),('23650776','L.en','Q353628'),('23650776','S','Q353628'),('23650776','S','Q54919'),('23650776','S','Q423048'),('23650776','S','Q2494649'),('23650776','S','Q13219454'),('23650776','S','Q131454'),('23650776','S','Q36578'),('23650776','S','Q47757534'),('23650776','S','Q2826570'),('23650776','S','Q188915'),('23650776','S','Q1201876'),('23650776','S','Q1526131'),('23650776','L.en','Q1028181'),('23650776','L.en','Q1622272'),('23650776','L.en','Q37133'),('23650776','S','Q37133'),('23650776','L.en','Q36524'),('23650776','S','Q36524'),('23650776','L.en','Q208826'),('23650776','O','Q174728'),('23650776','O','Q218593'),('23650776','L.en','Q35059'),('23650776','L.en','Q159'),('23650776','S','Q159'),('23650776','O','Q211043'),('23650776','L.en','Q211043'),('23650776','S','Q211043'),('23650776','S','Q19938912'),('23650776','S','Q193563'),('23650776','S','Q623578'),('23650776','S','Q13550863'),('23650776','S','Q1967876'),('23650776','S','Q50339681'),('23650776','L.en','Q36774')exception
Function: Wikibase\Client\Usage\Sql\EntityUsageTable::addUsages Error: 1213 Deadlock found when trying to get lock; try restarting transaction (10.192.16.22) #2 /srv/mediawiki/php-1.32.0-wmf.22/includes/libs/rdbms/database/Database.php(2030): Wikimedia\Rdbms\Database->query(string, string) #3 /srv/mediawiki/php-1.32.0-wmf.22/extensions/Wikibase/client/includes/Usage/Sql/EntityUsageTable.php(184): Wikimedia\Rdbms\Database->insert(string, array, string, string) #4 /srv/mediawiki/php-1.32.0-wmf.22/extensions/Wikibase/client/includes/Usage/Sql/SqlUsageTracker.php(212): Wikibase\Client\Usage\Sql\EntityUsageTable->addUsages(integer, array) #5 /srv/mediawiki/php-1.32.0-wmf.22/extensions/Wikibase/client/includes/Store/UsageUpdater.php(107): Wikibase\Client\Usage\Sql\SqlUsageTracker->replaceUsedEntities(integer, array) #6 /srv/mediawiki/php-1.32.0-wmf.22/extensions/Wikibase/client/includes/Hooks/DataUpdateHookHandlers.php(139): Wikibase\Client\Store\UsageUpdater->replaceUsagesForPage(integer, array) #7 /srv/mediawiki/php-1.32.0-wmf.22/extensions/Wikibase/client/includes/Hooks/DataUpdateHookHandlers.php(63): Wikibase\Client\Hooks\DataUpdateHookHandlers->doLinksUpdateComplete(LinksUpdate) #8 /srv/mediawiki/php-1.32.0-wmf.22/includes/Hooks.php(174): Wikibase\Client\Hooks\DataUpdateHookHandlers::onLinksUpdateComplete(LinksUpdate, integer) #9 /srv/mediawiki/php-1.32.0-wmf.22/includes/Hooks.php(202): Hooks::callHook(string, array, array, NULL) #10 /srv/mediawiki/php-1.32.0-wmf.22/includes/deferred/LinksUpdate.php(186): Hooks::run(string, array) #11 /srv/mediawiki/php-1.32.0-wmf.22/includes/deferred/AutoCommitUpdate.php(42): Closure$LinksUpdate::doUpdate(Wikimedia\Rdbms\DatabaseMysqli, string) #12 /srv/mediawiki/php-1.32.0-wmf.22/includes/deferred/DeferredUpdates.php(268): AutoCommitUpdate->doUpdate() #13 /srv/mediawiki/php-1.32.0-wmf.22/includes/deferred/DeferredUpdates.php(226): DeferredUpdates::runUpdate(AutoCommitUpdate, Wikimedia\Rdbms\LBFactoryMulti, string, integer) #14 /srv/mediawiki/php-1.32.0-wmf.22/includes/deferred/DeferredUpdates.php(134): DeferredUpdates::execute(array, string, integer) #15 /srv/mediawiki/php-1.32.0-wmf.22/includes/MediaWiki.php(914): DeferredUpdates::doUpdates(string) #16 /srv/mediawiki/php-1.32.0-wmf.22/includes/MediaWiki.php(734): MediaWiki->restInPeace(string, boolean) #17 [internal function]: Closure$MediaWiki::doPostOutputShutdown()
Notes
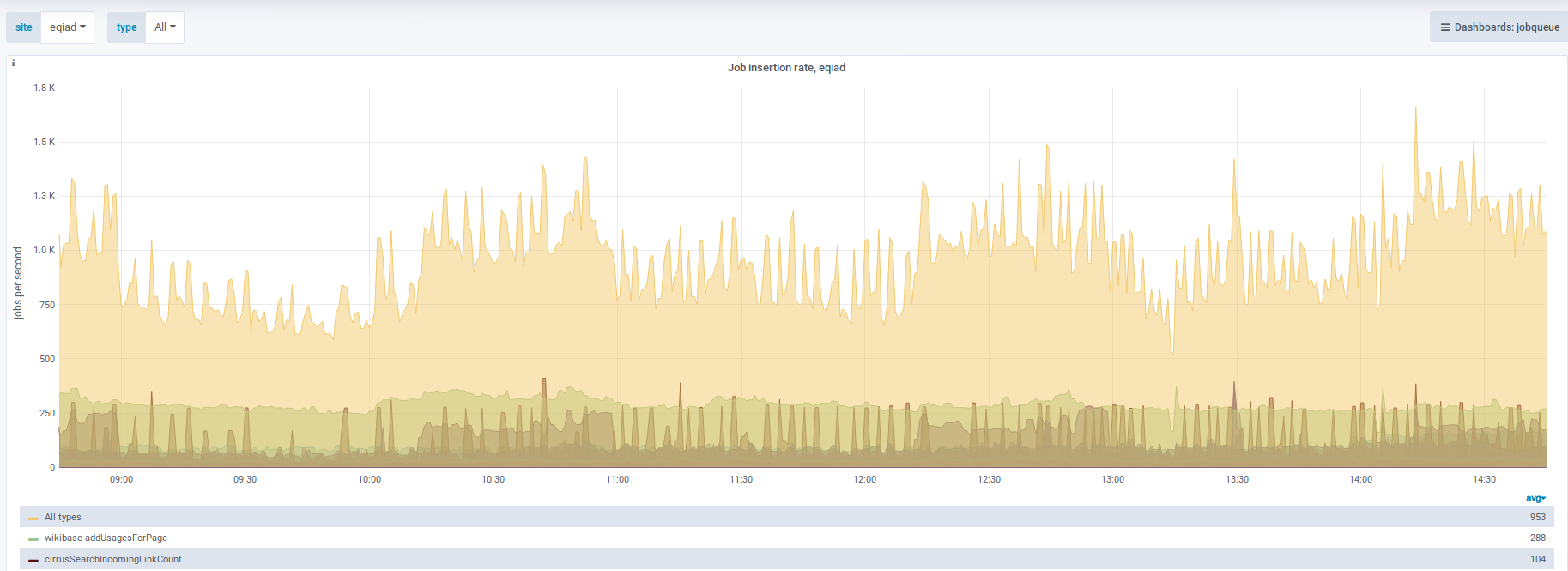
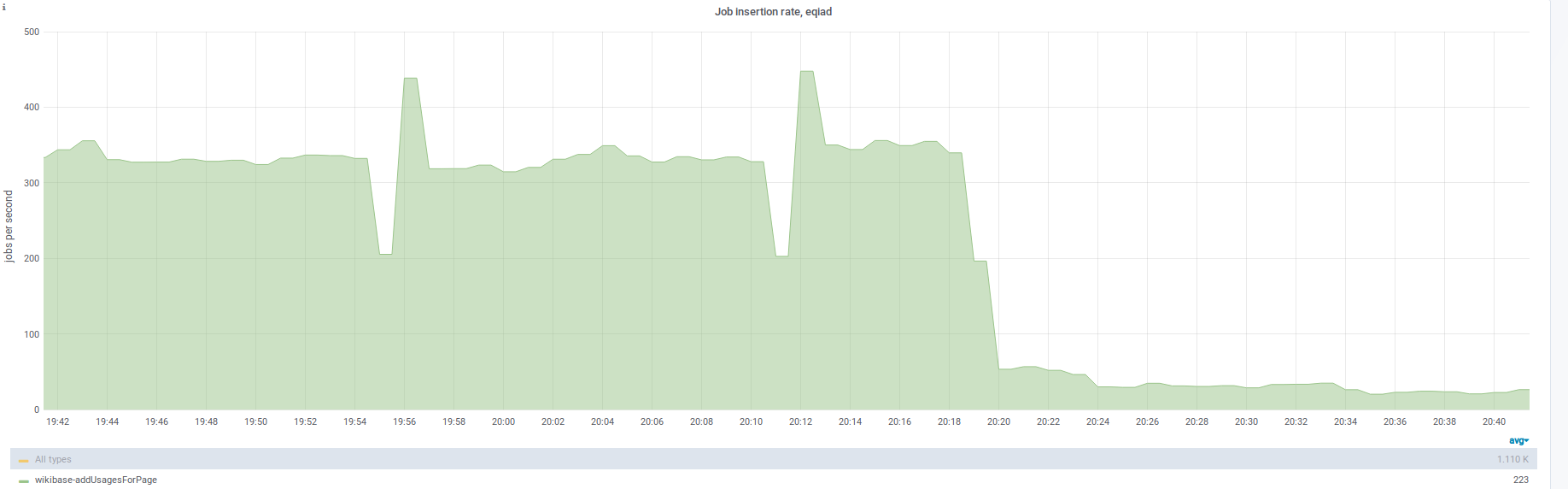
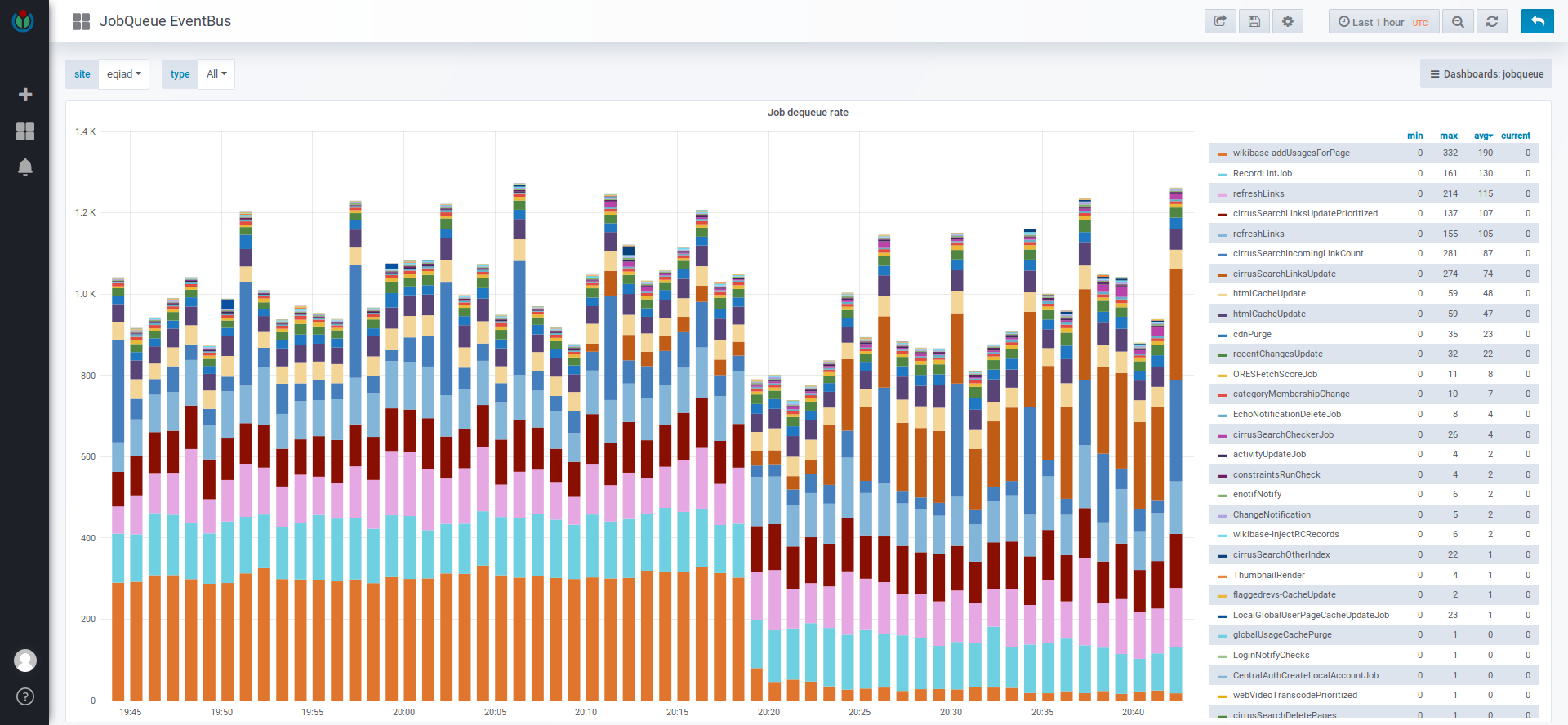
Logstash has 835 records matching this error from the past 30 days (at least since 1.32.0-wmf.16).
Affects commons.wikimedia.org post-edit, ru.wikipedia.org post-edit, and various job executions.
See also: