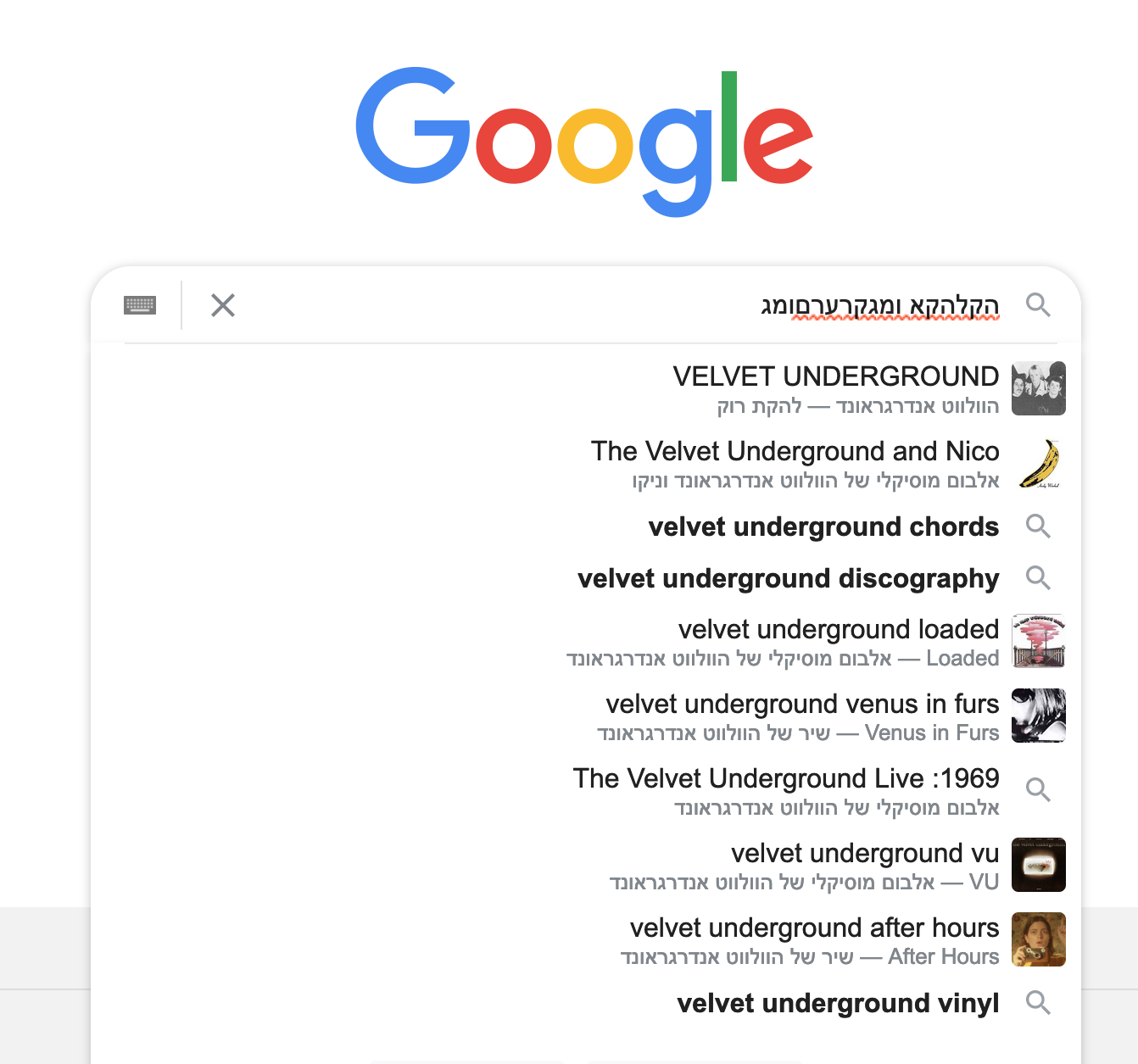
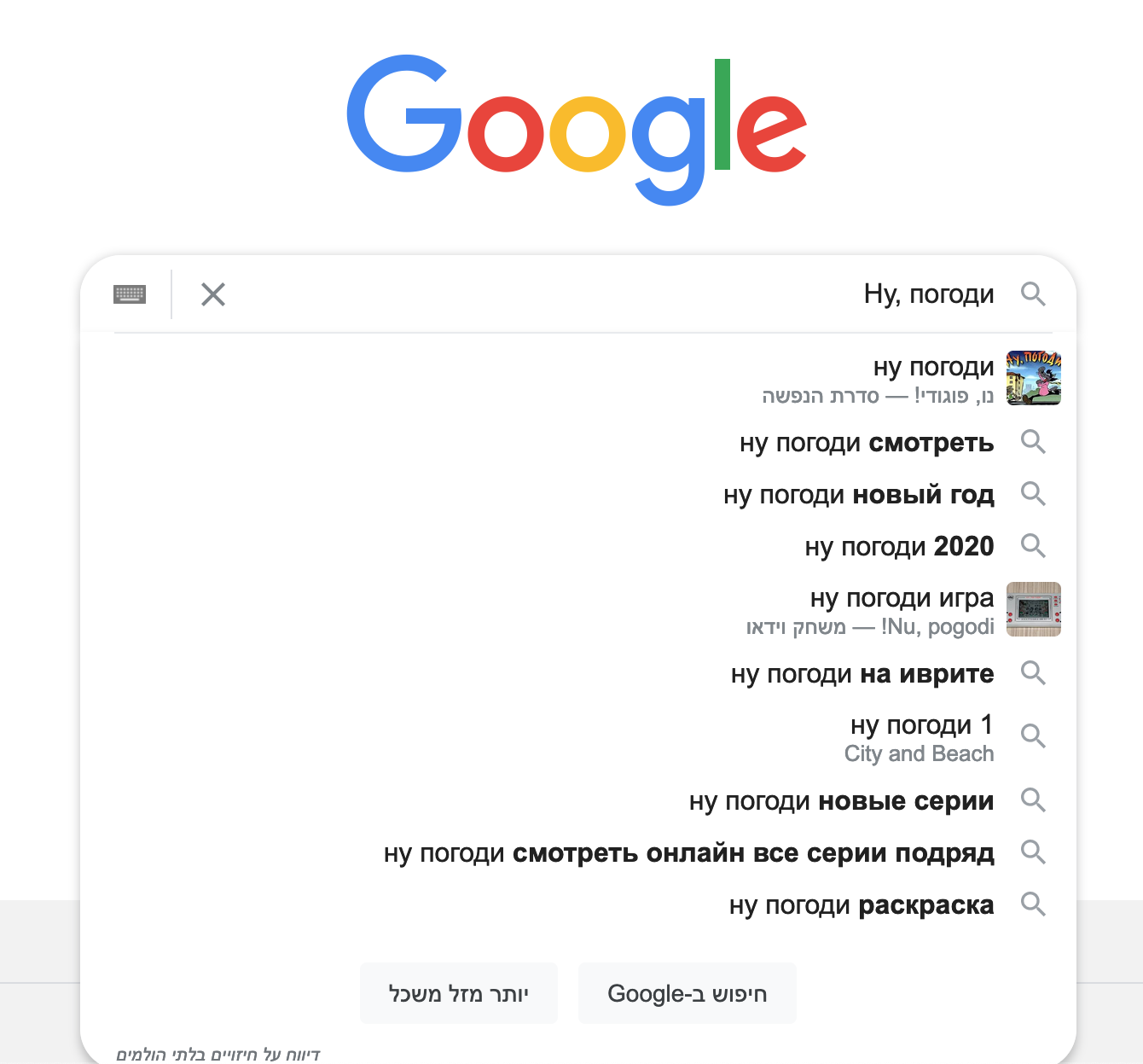
DWIM is a default gadget on hewiki. When a user performs a search that returns fewer than 10 results, any characters in the query string from the US English and Hebrew keyboards are swapped with their corresponding characters and a new search is run. For example, כרקג ("chrkg", which is probably fairly meaningless) becomes fred and tkpch, (with the comma) becomes אלפבית ("alphabet"). The results of the newly mapped search are appended to any existing results.
The implementation is tiny. See the source code, especially:
var hes = "qwertyuiopasdfghjkl;zxcvbnm,./'קראטוןםפשדגכעיחלךףזסבהנמצתץ"; function hebeng( str ) { return ( str || '' ).replace( /./g, function( c ) { var ic = hes.indexOf( c.toLowerCase() ); return ic + 1 ? hes.charAt( ( ic + 29 ) % 58 ) : c; } ); }
[Russian Wikipedia has a version of DWIM that can be enabled in user preferences.]
How should we build it?
Here are some possible approaches:
- Bake it into the network client (T244287) for MediaWiki maintained code, WVUI initially. Now we gotta handle all languages or at least Hebrew initially. We do this for the icons, should we do it for search? This makes the library (or wherever it's implemented) larger and increases the amount of code we formally maintain, but gives us full control, becomes universally available, and doesn't require us to maintain an API for gadgets out the gate.
- Expose, document, and support an API. A gadget will then have to be written by someone to use said API but not necessarily the Vue.js search team. However, any intentional or unintentional complexity will surely backfire on us as people will hack around it.
- Do nothing / wait for backend support. This would be a regression over the current experience for DWIM users so it's not possible. Evan said this was too tricky for the backend to do right now (we asked at All Hands). See T245677 for some exploration notes from the API team.
- Something else?
Option 1 and 3 seems mostly straightforward for at least the initial deployment. Option #2 seems more complex so it gets its own section.
Option 2: expose an API
The API provided by option #2 would need at least the following seams: a) query changed b) fetch complete c) fetch results for arbitrary string and d) append results.
b is the event emitted when any fetch completes. This would let the gadget author know when to issue a request. c is the function that a gadget would call to initiate a subsequent search request. d is an interaction to actually add the results from 3 to the UI. So, an actual use might look like:
- User types "tkpch,".
- A search for "tkpch," is requested.
- The search is performed, fetch resolves, and the UI is updated with any results.
- A "fetch complete" event is dispatched that includes the results.
- The gadget is listening for the event and sees the result count for "tkpch," is less than 10. It performs the keyboard mapping and issues a new search request for "אלפבית".
- The search for "אלפבית" completes and the gadget appends the result to the UI.
Additional notes:
- Does this require a global Vue.js application instance for authors to hook into? If not, how will they reference the network client, for example?
- Is a search(query: string): void and append(results: RestSearchResponse): void exposed?
- I assume that query changed and fetch complete / canceled / failed API would dispatch events.