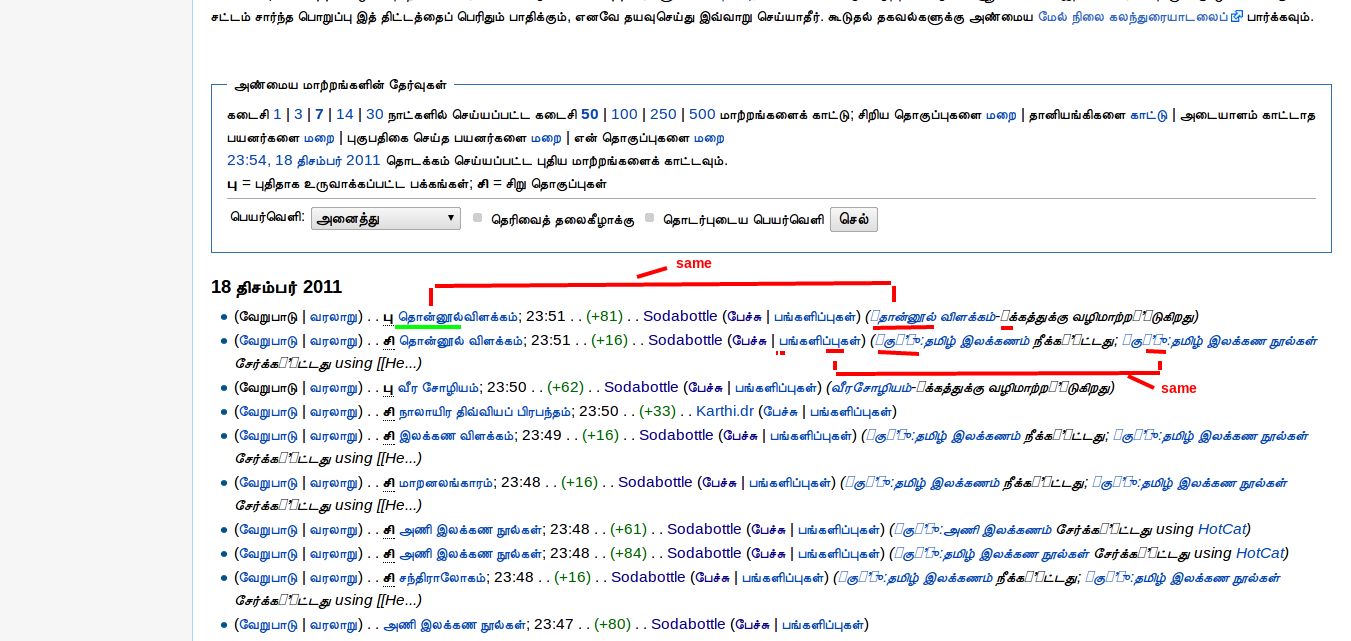
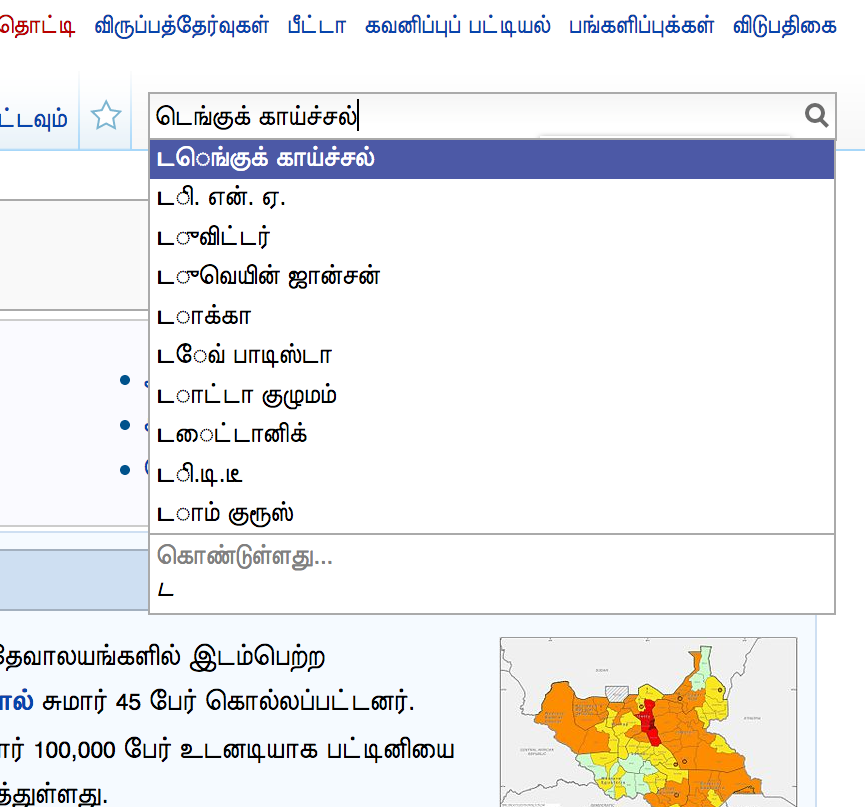
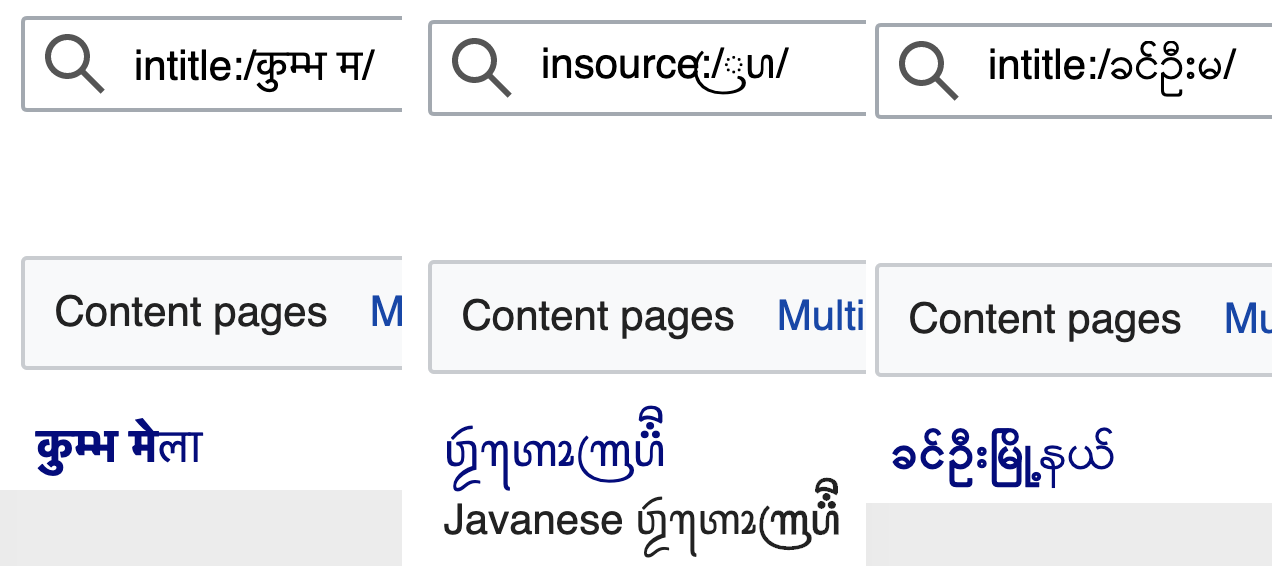
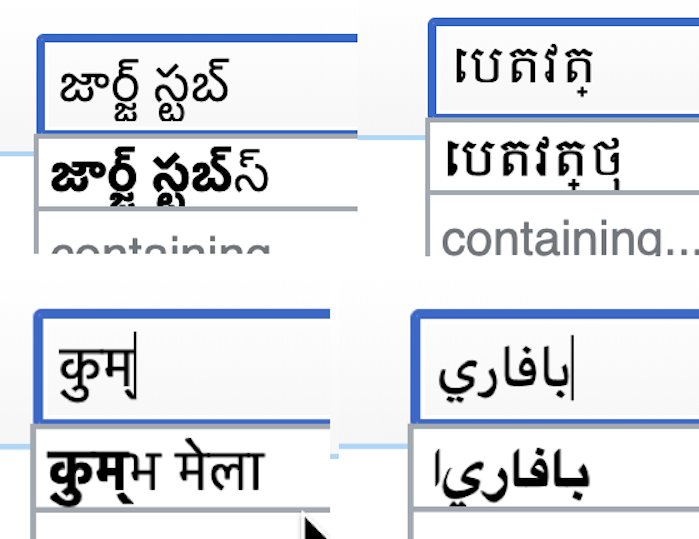
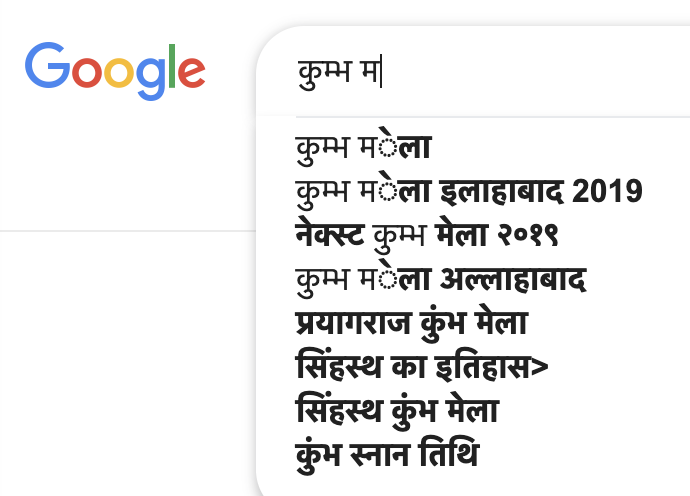
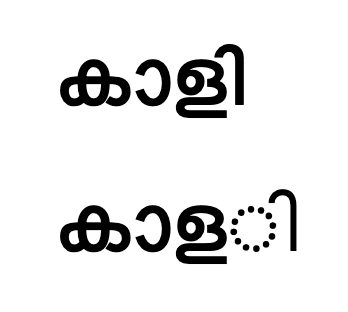
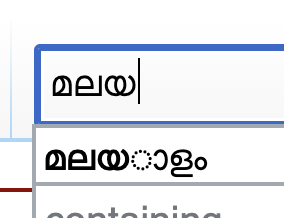
Certain glyphs dont render properly in few places and it occurs randomly.(See attachement) Fonts are not an issue. Most of us who tested across browsers, OS have tamil fonts and a good number of them. This issue is reproducible only on wikimedia sites.
Ravi noticed this rendering bug in the search box on Ubuntu 11.10 and FF8
Bala noticed this rendering bug in the search box on Win XP SP3 and FF5,IE7
I notice this rendering bug in the RecentChanges page on Ubuntu 11.10 and Chrome 16
Version: unspecified
Severity: normal
URL: http://ta.wikipedia.org/wiki/Special:RecentChanges
See Also:
T41101: ULS Search auto-complete suggestions over write the input in Indic