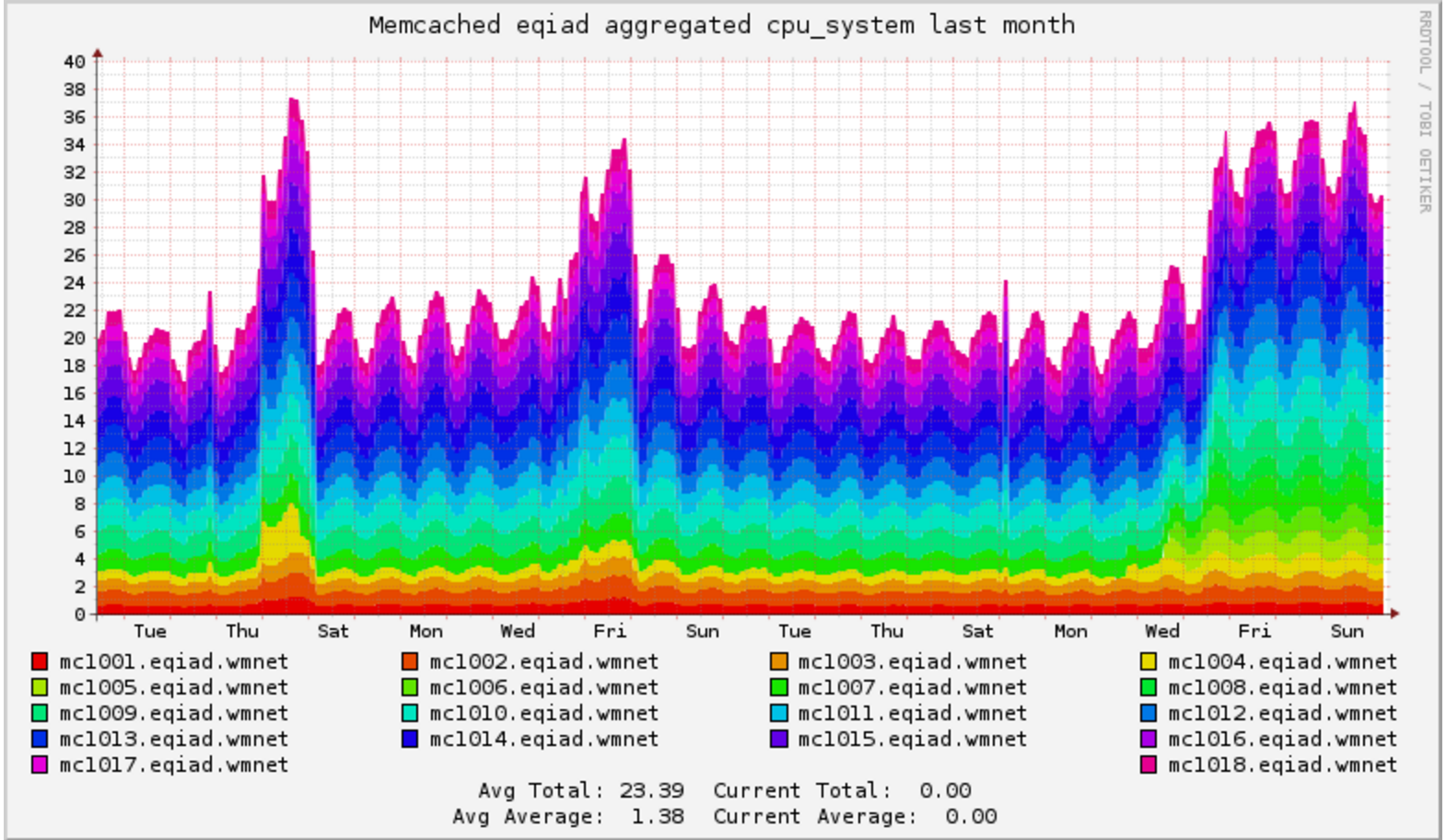
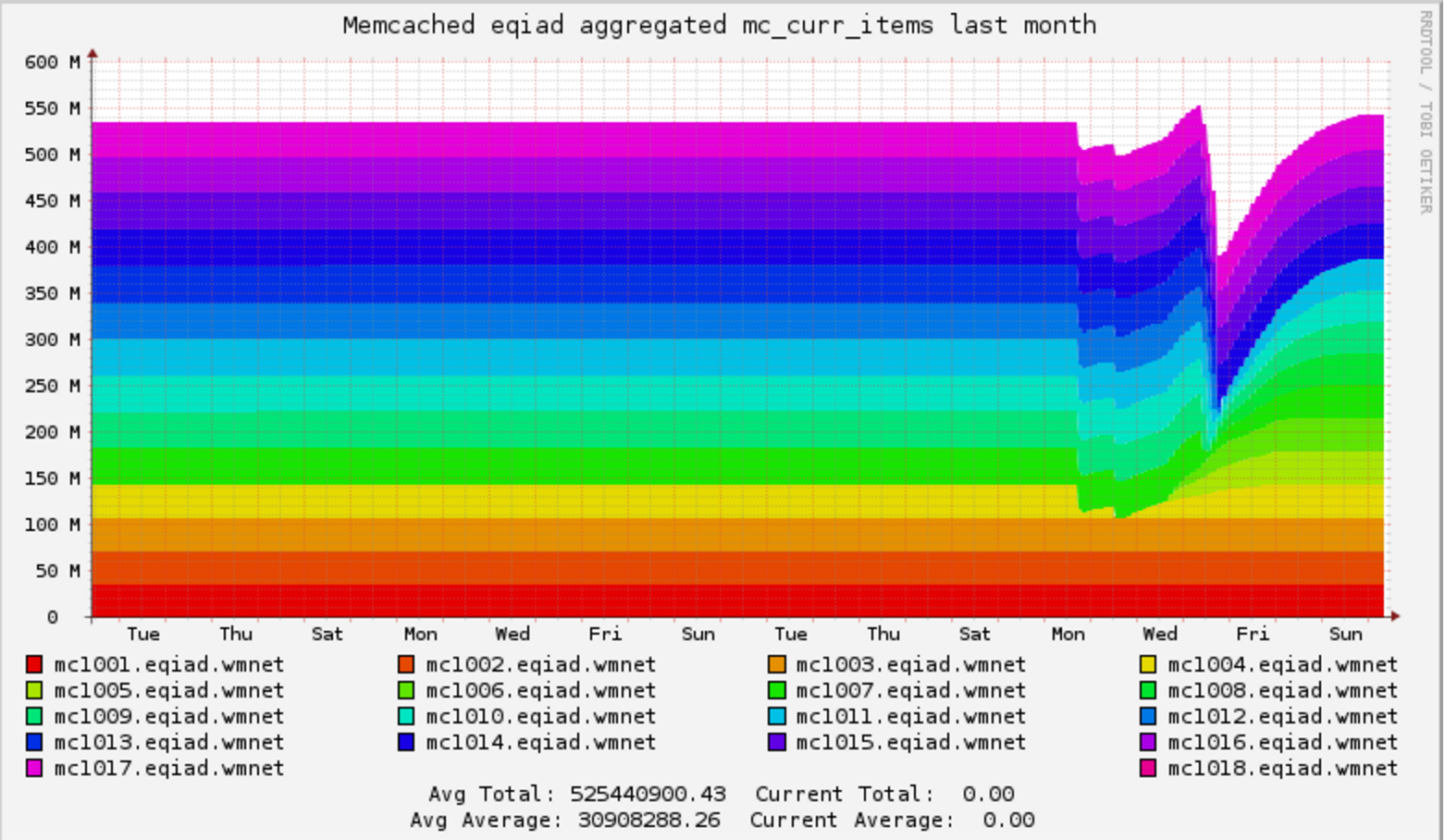
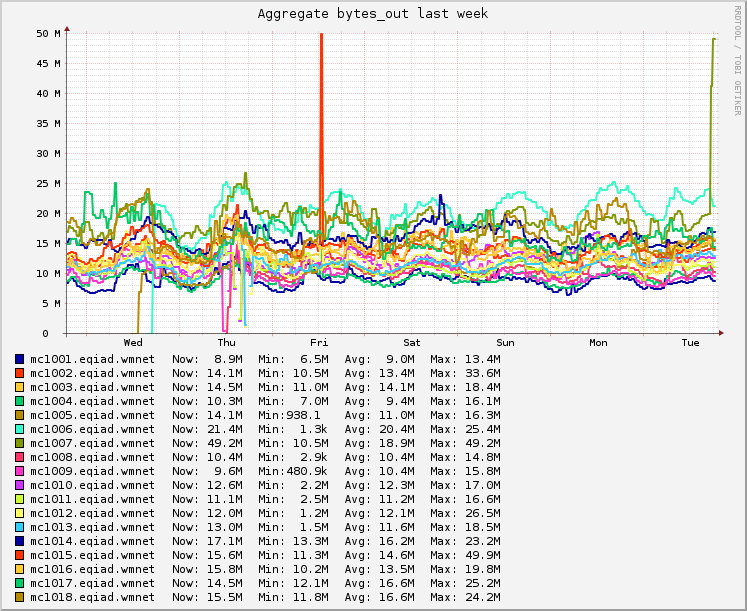
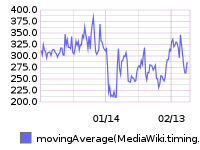
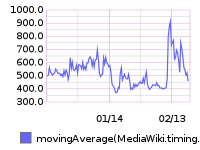
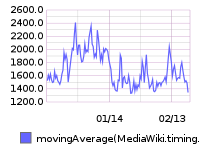
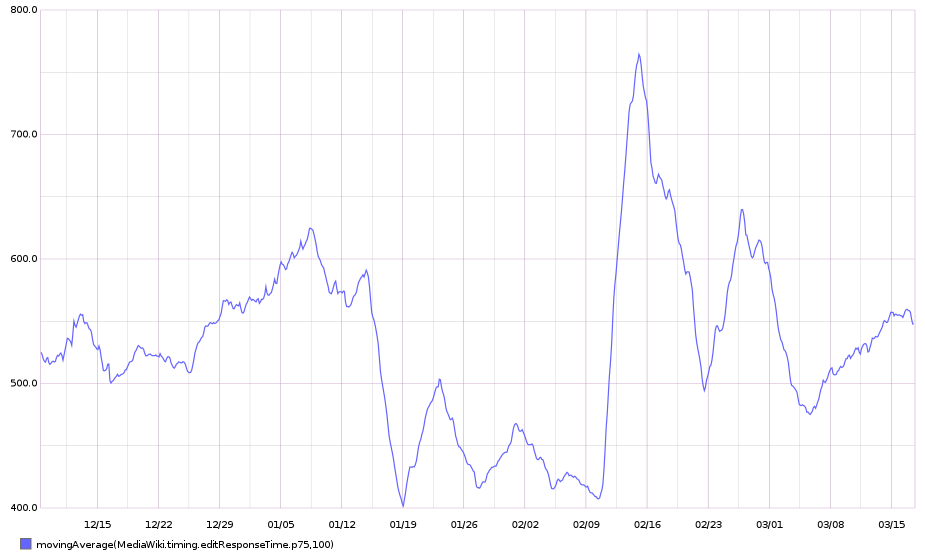
Grafana board https://grafana.wikimedia.org/dashboard/db/t126700
Experimental board for Nutcracker https://grafana.wikimedia.org/dashboard/db/nutcracker
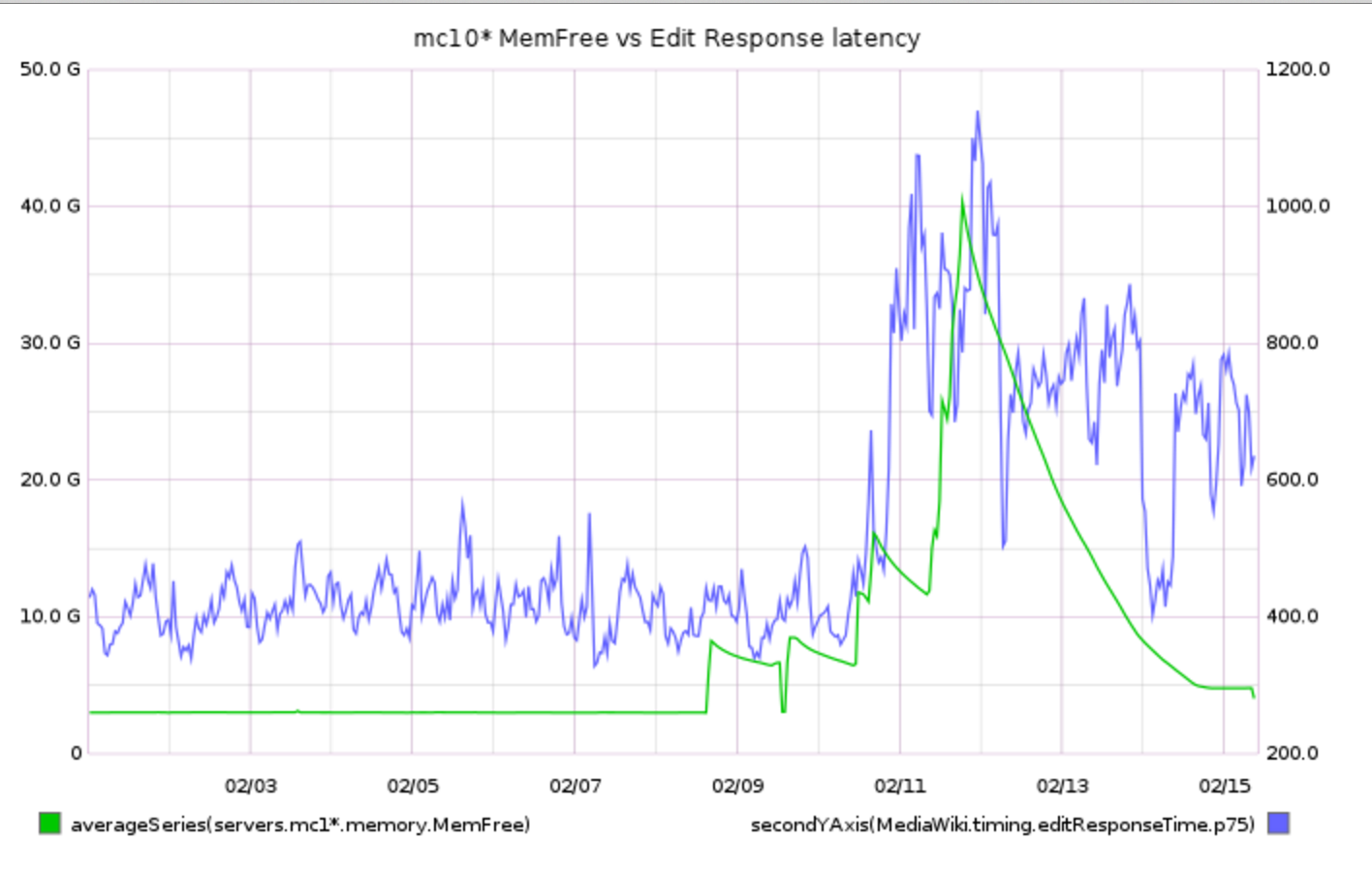
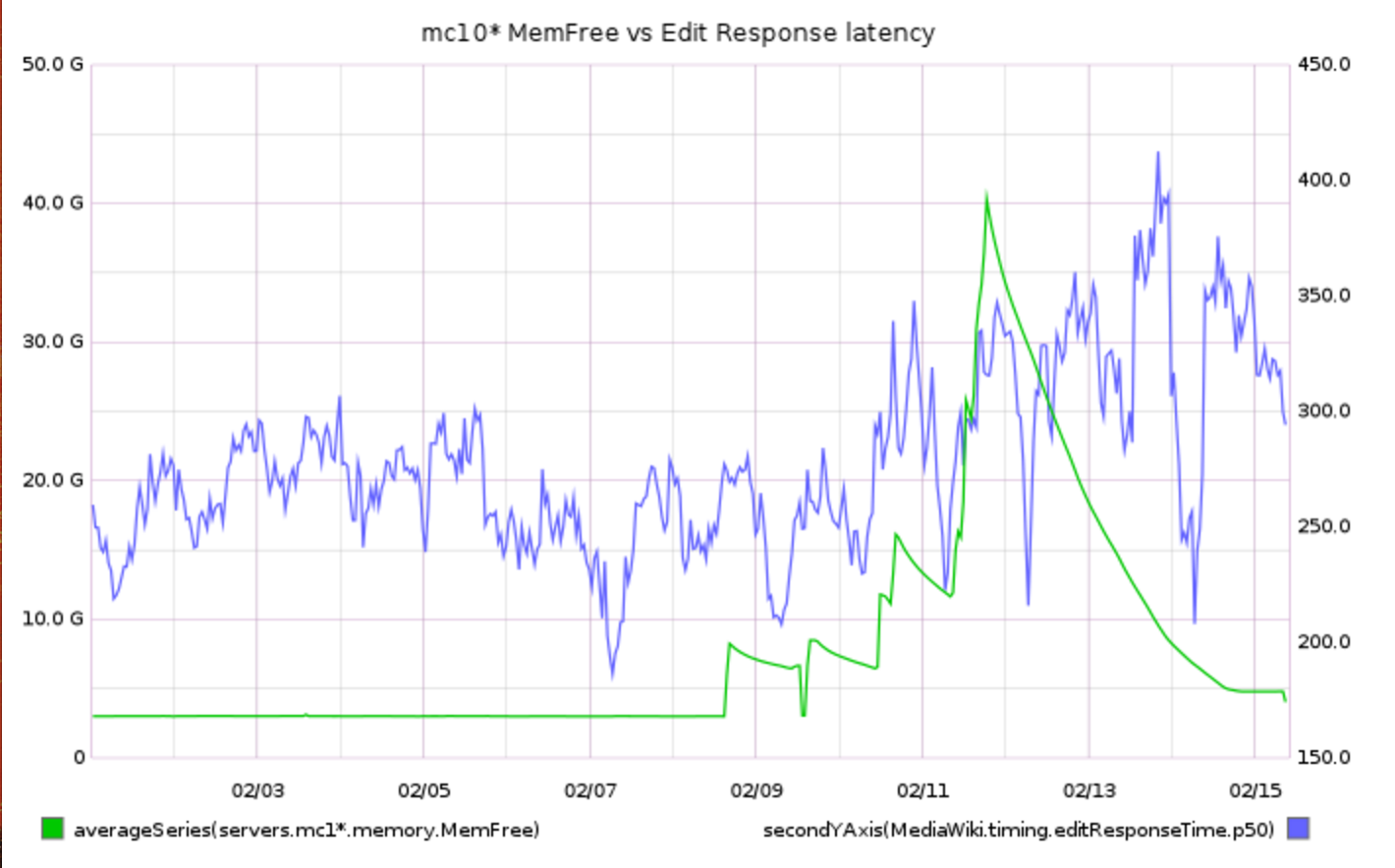
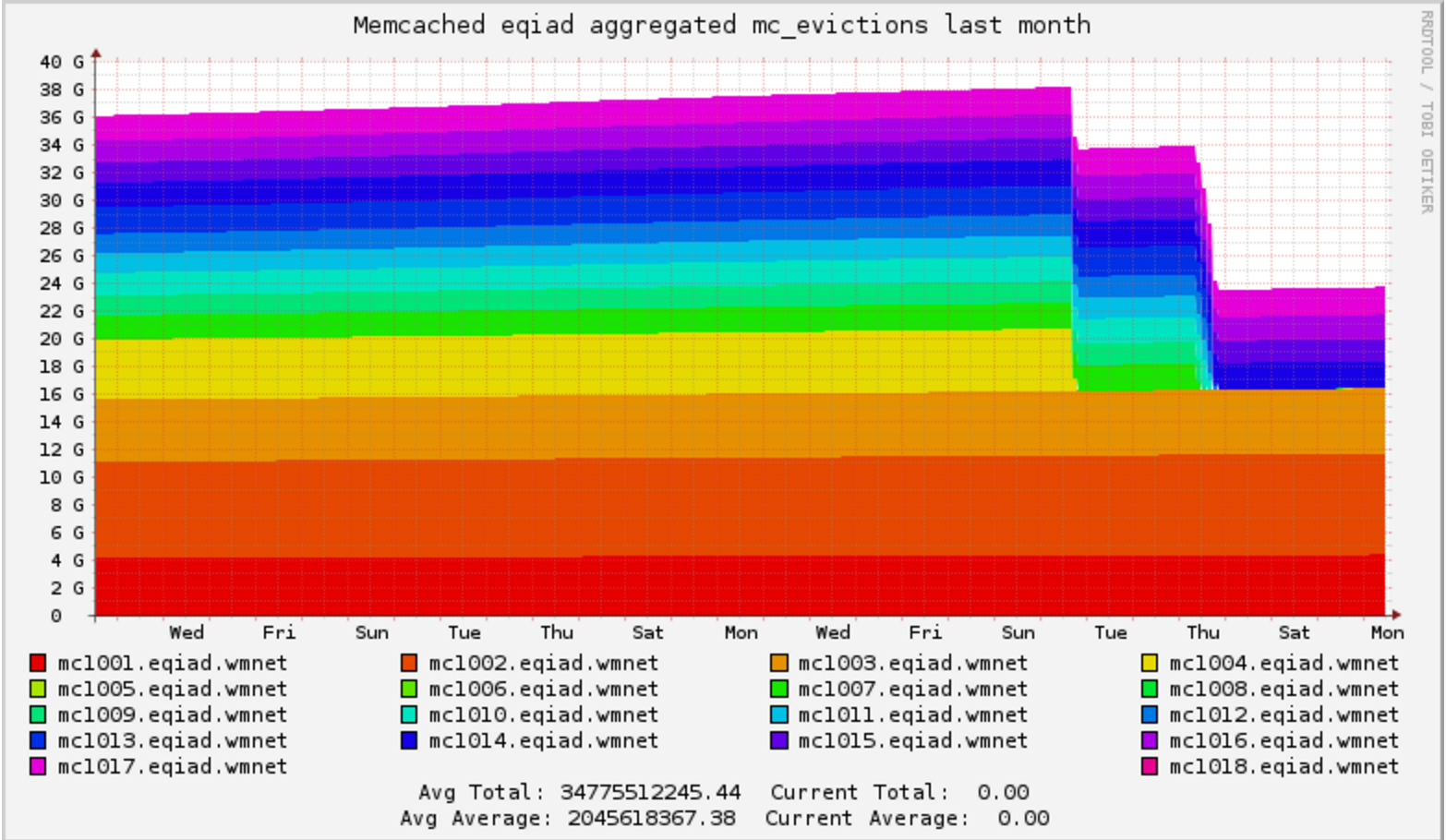
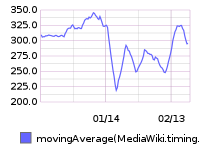
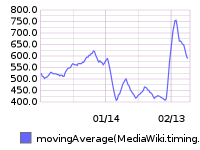
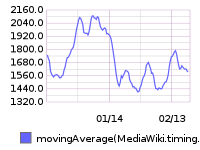
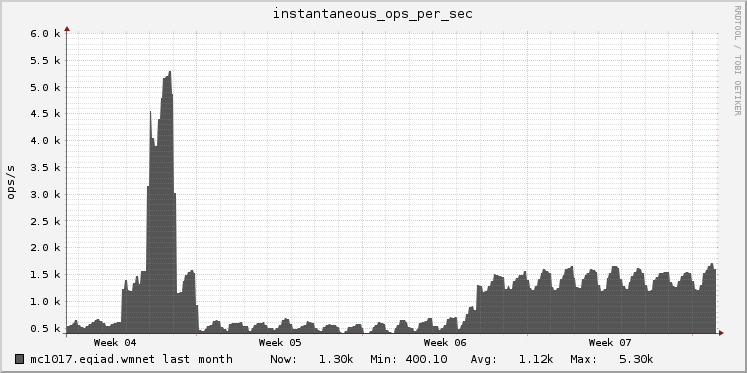
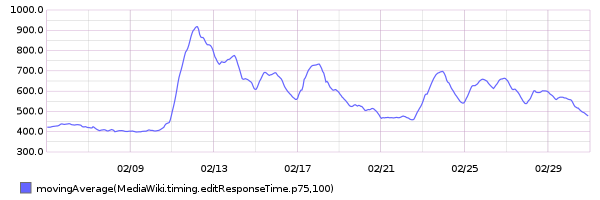
75th percentile save latency has nearly doubled over the past 32 hours. The spike started around 15:00 UTC on Wednesday, February 10:
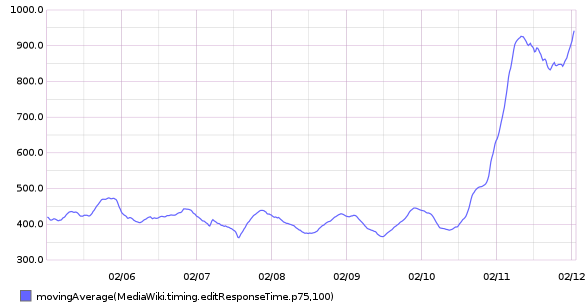
From 20160209 00:00 until 20160216 23:59:
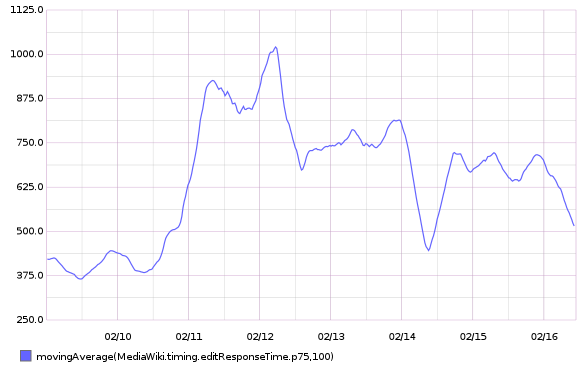
This metric is calculated within MediaWiki, so it can't be related to T125979: Disable SPDY on cache_text for a week.
SAL entries from that time (+/- 1hr):
- 15:22 elukey: disabled puppet/memcached/redis on mc1006.eqiad
- 15:02 bblack: SPDY disable for cache_text: test starts in a few minutes!
- 14:48 elukey: removed mc1006 from the redis/memcached pool for Jessie migration
- 13:48 godog: restbase1002 nodetool setstreamthroughput 500
- 13:24 elukey: adding mc1005.eqiad back into service (redis/memcached)
- 12:51 jynus: restarting hhvm at mw1015 - db errors continue