There's a report at en.wp by @Nthep, about "a rash of vandalism occurring adding porn pictures to articles that are featuring in 'In the news' e.g. North India and I can't work out how to remove the vandalism."
@TheDJ points out that the content would have come via the "aggregated featured content" RESTBase feed (where that article and presumably also its vandalized image appeared that day), and suggests that aggressive caching may be at fault. We'd like to find out if there's a specific bug.
Thanks!
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | • Mholloway | T174993 Vandalism in "In the news" articles persisting in the app ? | |||
| Resolved | • Pchelolo | T179412 Stop storing feeds in Cassandra |
Event Timeline
There are a very large number of changes, so older changes are hidden. Show Older Changes
Comment Actions
Not sure if there's any action to be taken at this point but tagging with RI to evaluate that.
Comment Actions
@bearND can you take a minute here to investigate this?
Would be nice to know if this is just some caching on the back end or within the apps themselves.
Comment Actions
Adding the Services team to see if they have any more input on this or to correct anything I write here if necessary.
The incident reported on [[en:VPT]] happened last week (8/31). By the time I was notified on IRC the vandalism was already reverted and not visible in the feed anymore. The feed content was automatically updated after the pageimage of the page associated with the news item was changed.
The client caches the complete feed content for 1 minute, proxies cache it for 5 minutes:
curl -sI "https://en.wikipedia.org/api/rest_v1/feed/featured/2017/08/31" | grep cache-control cache-control: s-maxage=300, max-age=60
The summary data for articles is cached on clients for 5 minutes. It's cached much longer in Varnish proxies but when a change is detected ChangeProp should queue up the update shortly[1] thereafter depending on server load, and update the respective cache entries.
curl -sI "https://en.wikipedia.org/api/rest_v1/page/summary/North_India" | grep cache-control cache-control: s-maxage=1209600, max-age=300
[1] Page-edit_delay is usually around 1s, max is 1 minute. Mw-purge_delay is usually around 1s, max is 2 minutes.
Comment Actions
@bearND, until recently the cache timeout for the trending response was 30 minutes. @Pchelolo lowered it to five minutes in https://gerrit.wikimedia.org/r/#/c/374648/, after the issue was reported on the staff channel by @jynus.
Comment Actions
@GWicke This is not about trending-edits. The Explore feed content does not include trending-edits information yet.
Comment Actions
The article names for the feed are stored in Cassandra, but these are just the names, not the summaries and for the current day they are expired in 1 hour.
The image of the day, that comes from the MCS is also stored in Cassandra for 1 hour for the current day, and indefinitely for historic days. I guess if the image is replace with some vandalized URI it could be shown to the users if it's picked up by MCS and stored in Cassandra.
Comment Actions
@Pchelolo If there's a change in the summary data for a page included in the feed, is there a ChangeProp rule to trigger a purge of Varnish/CDN caches for the feed response?
Assuming a change to a page included in the feed content affects the summary data, how long should it take from the time that change is made to appear in the client?
Comment Actions
Nope, we don't really know which pages are included in the feed.
Assuming a change to a page included in the feed content affects the summary data, how long should it take from the time that change is made to appear in the client?
At most 1 hour.
Comment Actions
@Pchelolo What can we do to reduce this time? Where is the bottleneck or most of the time spent? I thought it would only in the order of minutes.
Comment Actions
@JMinor or others, any guidance about how long is acceptable? Is 10 minutes max without intervention good enough?
Comment Actions
This is a tough one. As "voice of the customer" I think the editors would ideally see it happen on the same time scale as the web. Stepping back, though, for me 10 minutes seems reasonable.
@Elitre @TheDJ do you think lowering this to 10 minutes would satisfy the editors concerned or would they just come back with "why not make it instant?"
Comment Actions
My 2 cents as an Android app user: there is no difference to me if the time frame is 10 mins or 1h since the typical workflow is (i)) spot something is wrong; (ii) refresh 2, 3 times (takes way less than a second); and then either complain or ignore. As somebody that on the back-end side of this story, I opt for ignoring it (if I'm not in the capacity to purge it from Varnish right away), but I can relate to people that complain about it. I think that informing users about this edge case would go a long way. Posting something somewhere where people complain most often would greatly help, given the fact that solving this problem properly is not a small endeavour in technical terms.
Comment Actions
@mobrovac by "properly" do you mean monitoring changeprop for all the page changes and purging the cache like that?
As opposed to the current proposed solution of just lowering the max age of the cache to 10 minutes?
Comment Actions
@JMinor doing it in "real time" (by monitoring changeprop) is the solution I believe that @mobrovac is talking about… and yeah that is probably not going to happen soon. The best we can do is probably lower the time which was suggested.
Maybe we should go a bit lower?
@Pchelolo is there much difference between going with 10 minutes or 5 minutes?
Comment Actions
I think personal use cases and expectations vary quite a bit, so I agree that we should take different perspectives and situations into account. A 10 minute delay might look pretty bad in quite a few situations (e.g. you make an edit and want to show people the result).
For context, do we know what a typical caching-induced delay might be in an analogous situation on desktop or mobile web?
Comment Actions
(e.g. you make an edit and want to show people the result).
@Tbayer If you are talking about making an edit to a page and then seeing the results being reflected in the summary and mobile-sections endpoints, this should be near-instant (within a few seconds) since ChangeProp knows how to actively update the MCS contents in RB for that particular page.
The case we're discussing here is slightly different since this involves the Explore feed which contains summaries for many pages but ChangeProp doesn't know when any of the million pages in a WP project that needs updating also should trigger an update for the Explore feed, at least according to the current implementation.
To get updates to the Explore feed coming in near instantly we would need a quick lookup table available in ChangeProp to see if a page is included in any of the Explore feeds for the current WP domain and for which date. Changes to most pages don't trigger Explore feed updates but changes to some prominent pages could require updates to multiple days of the Explore feed (esp. if the page appears in most-read).
This might be a bit too much custom code for the level of ChangeProp, and that is why it hasn't been implemented like that, as far as I understand.
@mobrovac I think the aim is to reduce the time vandalism appears in the apps and the chance of a more users noticing it, reducing also the fun factor and incentive for more vandalism.
Comment Actions
@Pchelolo is there much difference between going with 10 minutes or 5 minutes?
We can basically stop fetching from Cassandra for the current day completely - that will get us down to 5 minutes. Generating the feed is pretty expensive, but given that the variability of parameters is super low most of the cases will be served from Varnishes, so that wouldn't affect latency too much.
We can also decrease Varnish caching time, but that comes with a price obviously of lower cache hit rate.
Comment Actions
Thank @bearND, that's good to know! But I was also thinking about desktop, and about edits to templates and the possible delay for their result being reflected in pages where these templates are transcluded. I seem to recall long delays in that situation - up to a week or more in the dark ages 5 or more years ago - but was curious about the situation today.
On desktop though, editors can remedy the problem themselves by doing a manual purge. So I guess another question would be if we could enable such manual purges for the RESTBase endpoints that are at issue in this task.
Comment Actions
The proper solution would be to have a component-dependency-tracking system that tracks which component is included/connected to which other component and then purge the dependency as well. In this concrete case, this would mean that every time the feed is generated, this system would create links between the current day's feed and the page titles/summaries referenced in them, so that if one of the summaries changes, the feed is purged. And this is not that trivial given our scale. There is a proposal out there for this - T105766: RFC: Dependency graph storage; sketch: adjacency list in DB - but there has been no movement on it (yet?).
Comment Actions
@Nthep just wondering; could you describe as exact as possible, what fragment of content (where exactly (screenshots would be cool), type (text/thumb), etc) was not up-to-date after the revert, what you tried to do in the app to check or rectify (closing, reopening, navigation actions, refresh buttons), and what amount of time you tried to do this ?
That might help people to identify where to focus there attention on, and what scenarios to check.
Comment Actions
DJ thanks for asking for comments. I first became aware of the issue via some OTRS tickets (#2017083110022701 for example which also contains screenshots) and what I witnessed for myself was the aftermath of at least these edits https://en.wikipedia.org/w/index.php?title=North_India&diff=prev&oldid=798119728&unhide=1 and https://en.wikipedia.org/w/index.php?title=Typhoon_Hato&type=revision&diff=798119725&oldid=798119611&unhide=1
All the stories featured in the "In the news" section of the front page of en:wp on 31 August and although the vandalism was reverted very soon i.e. within minutes of occurring and the offending edits being revdel'd the images still appeared on the app some hours later. The vandalism occurred about 0300, as repaired by 0315 and revdel'd by 0530 yet the images were reported as being present at 1300 (per the OTRS ticket) and visible to me about the same time. Refreshing the app made no difference to me, neither did completely closing the app and re-opening it, the images remained stubbornly in place both in the headline view and as the article header image when the articles were opened in the app.
As a side issue to the appearance of the images appearing in the app some time after the vandalism has been fixed as a reader it is pretty disconcerting having clicked on the images to get panels appearing days later saying "On 31 August you viewed <name of image> do you want to find out more" or pretty much the same suggestion. Now I know enough to realise what was happening but for a casual reader to a) have encountered the images in the first place and b) to get subsequent reminders/suggestions is not putting WP in the best light. I do appreciate that this subsequent behaviour of the app is an unfortunate consequence but perhaps there needs to be a different way of proposing content to readers
N
Comment Actions
If possible, could someone with OTRS access possibly make them 'decent' by overlaying with black squares or something and upload them here. Just to make sure we are all looking at the right data fields in the various APIs, instead of making guesses.
This sounds seriously longer than any of the systems is supposed to be caching information, so somewhere there's a problem for sure. Thank you @Nthep
Comment Actions
(This was probably already explained in this task, but: the issue that Nthep saw where vandalism seemed to be persisting hours after it was fixed, could the same thing happen to an edit to a Wikidata description? Or the type of content, position etc. makes the difference here? Thanks.)
Comment Actions
" in the headline view and as the article header image when the articles were opened in the app"
To me this sounds like an old version of a PageImages selection got stuck somewhere. Maybe the PageImages read an old revision from a slave when it received the purge of the original vandalism revert, instead of the new version and that would then get cached. The next purge for both of those pages was some vandalism around 14:35. If no one purged the page in question until 14:35, than that cached version might have well lingered around to 14:35 + 30 minutes or so as explained above..
Comment Actions
I think that when the issue is that an ugly vandalism stayed around for over 10 hours (per user's report), 10 minutes (or another threshold that is easily accomplishable at this moment without breaking anything else or having to invest massive resources, that is, a low hanging fruit kind-of-thing) should be a big improvement. I think topics such as "would it be possible for reverts to be instant if performed on main page and other highlighted articles" could be discussed at a later stage.
Comment Actions
WRT the 10h lag, one theory could be that it is connected to T173710: Job queue is increasing non-stop, where the backlog of refreshLinks jobs (used to trigger updates to page properties as well) has been very high lately, especially on commons. If that is indeed the case (this is yet TBD), then no caching setting would help us.
Comment Actions
Ok, so it seems like we have 2 things here:
- An unknown cause of a 10 hour lag before vandalism was purged from the cache
- A normal 1 hour lag before vandalism is purged from the cache (unrelated to the issue in this ticket)
For #2, I am going to make a separate ticket to lower the cache time to 10 minutes so that can be discussed / implemented independently of this investigation.
For # 1, @mobrovac it sounds like maybe we need to wait for T173710: Job queue is increasing non-stop to be resolved and see if this happens again? Or is there a way to validate our assumptions of this being the cause?
Comment Actions
FWIW, I happened to talk to @Dbrant earlier today about this ticket and about Wikidata descriptions in the app. He pointed out that the app loads the description together with the main (Wikipedia) article content, in the same request to the same endpoint (which differs from the feed-based endpoint being discussed here). That said, as mentioned above, even Wikipedia content on desktop has not been immune from such delays, in particular when it involves templates.
Comment Actions
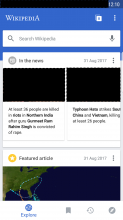
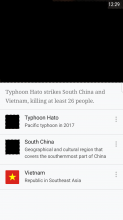
Here are the screenshots I found in OTRS regarding this issue, with black rectangles overlaid for decency and privacy protection.
The same image was used for all blacked out images, which means pageimages of at least four articles were vandalized using the same method, from what I can see in the screenshots and the above report.
- [[2017_Northern_India_riots]] (first screenshot: likely the selected main image since it's first in the list of articles for this news story of the feed that day)
- [[North_India]] since that was mentioned in VPT
- [[Typhoon_Hato]] (second screenshot)
- [[South_China]] (second screenshot)
Since the same pictures were used for the first two, unrelated news stories (and the first two articles in each stories) it seems to me that someone targeted the Android app specifically. ITN on the main page (desktop) only shows a single picture.
Comment Actions
Just to clarify what exactly happened here: The offending edits were adding an image to the featured page itself, and also nominated that image to be the pageimage?
Comment Actions
@GWicke Not to the featured articles. This was for pages linked from In the News.
I believe it was the pageimages designation for those articles I mentioned above. Not exactly sure what happened on wiki since the revisions have been deleted from public archives (and I don't have the permission to view it).
Comment Actions
I believe it was the pageimages designation for those articles I mentioned above. Not exactly sure what happened on wiki since the revisions have been deleted from public archives (and I don't have the permission to view it).
Yeah, I am asking for that reason as well. Basically, if this is edits exclusively in the article content itself (no transclusions or image re-uploads), then refreshLink jobs would be unlikely to contribute to propagation delays.
Comment Actions
In all four cases the image link was added at line 1 in the articles. So if pageimages picks up the first non non-free image in the article to display in the mobile or app version then this is the image that would display.
In response to the previous comment about this being deliberately targeted at the Android app, I don't think that is the case. This is someone targeting ITN articles and related subjects (check the contribution history at https://en.wikipedia.org/w/index.php?title=Special:Contributions/172.56.13.53) and adding a pornographic image and a level 1 heading and text to the top of the page to be seen when the article is viewed - that it got picked up by the Android app they would probably see as a bonus reward if they were aware of it.
Comment Actions
If this happens again, please check the pageimages output (e.g. https://en.wikipedia.org/w/api.php?action=query&prop=pageimages&pilicense=any&titles=North_India ) and report whether it contained the offending image. It's probably impossible to figure out after the fact at what layer did the old content get stuck. If it's PageImages, one possible precaution is to record the base revision along with the image name, and clear the page property immediately when that revision gets revdeleted.
Comment Actions
As far as I can tell, the page image(s) are handled as part of deferred linksUpdate processing. This means that the updates would be executed after the main web request, but on the same PHP thread that handled the original edit request.
Assuming this is correct, this would rule out the job queue backlog as a direct cause for delayed or lost pageimage updates. Failures in deferred update processing could however cause a pageimage update to be permanently lost. @aaron, does this make sense to you?
Comment Actions
I don't think they are post-send. I see WikiPage::doModify => AtomicSectionUpdate added; runs post-send => doEditUpdates() => LinksUpdate added; runs post-send and is enqueued since it implements EnqueueableDataUpdate and the postsend (and pre-send) DeferredUpdates::doUpdates() call in MediaWiki.php has 'enqueue'.
Assuming this is correct, this would rule out the job queue backlog as a direct cause for delayed or lost pageimage updates. Failures in deferred update processing could however cause a pageimage update to be permanently lost. @aaron, does this make sense to you?
Exceptions are logged (and there is fatalmonitor for fatals), but even when errors are caught, the task is lost.
Comment Actions
I think LinksUpdate for the page directly edited can probably be moved (back) to doing the actual work post-send.
The 'enqueue' parameter can be removed from MediaWiki::restInPeace() since, unlike in the PRESEND run, the user is not waiting on it to run. If a caller really wants to enqueue a job post-send, it can always use lazyPush() instead of adding an EnqueueableDataUpdate to the POSTSEND deferred update list.
Comment Actions
Thanks @aaron!
This seems to address the most probable reason for the vandalism, but from reading the comments we can't be 100% sure right?
If that is the case, should we leave this task open or close it optimistically?
Comment Actions
I'd leave it open. The above change avoids the jobqueue and thus fast tail jobs piling due to slow wikidata jobs in the head of the queue. It should help, I'd assume.
Comment Actions
We had a similar series of incident today, this time with the thumbnail of yesterday's featured article.
The October 20th TFA thumbnail was vandalized several times starting on October 21st at 00:02 UTC with a series of reverts and another counter attack.
00:02 First vandalism edit.
00:07 The 2nd vandalism was removed.
00:13 The page was edited to restored the correct pageimage.
00:36+ I updated the RESTBase storage for the feed for this day (from scb1001):
curl -H 'Cache-Control: no-cache' http://restbase1007.eqiad.wmnet:7231/en.wikipedia.org/v1/feed/featured/2017/10/20
00:46 James reported that it was fixed.
As a follow-up I've updated the instructions for refreshing RESTBase storage so they are easier to find and execute. I would like to ask @Pchelolo or someone else from the Services team to add info about purging the Varnish cache for this, too.
Comment Actions
If this comes up in the future, it would be nice to have
- contents of the request vs. a direct RESTBase request and pageimages API request (e.g. output of curl -s 'https://en.wikipedia.org/api/rest_v1/feed/featured/2017/10/20' and curl -s 'http://restbase1007.eqiad.wmnet:7231/en.wikipedia.org/v1/feed/featured/2017/10/20' and `curl -s 'https://en.wikipedia.org/w/api.php?action=query&prop=pageimages&pilicense=any&titles=Boogeyman_2'), to see where the wrong information got stuck
- if that's Varnish then header dumps for the request (e.g. curl -vso /dev/null 'https://en.wikipedia.org/api/rest_v1/feed/featured/2017/10/20'), especially the X-Cache header which helps identify which Varnish box the information came from
Comment Actions
We've discussed this issue during the Services-Reading meeting and here're some ideas from the discussion:
We're using Cassandra permanent storage for 2 reasons.
- Most importantly - we cannot regenerate in the news section for previous days, we can only fetch it for the current day.
- To save some latency and resources of MCS. It does give us a pretty significant latency improvement for Varnish cache misses, from 500 ms generating it each time to 230 ms using Cassandra. However, Varnish hit rate is quite high on this particular endpoint: out of 28 req/s that hit Varnishes only about 1.5 req/s is a cache miss.
If we're storing historic content it's always possible to make vandalism persist in the stored content requiring manual purging, there's simply no way of solving this issue generically. Currently Android app only shows the news card for the current day anyway and on iOS I personally don't see the news card at all, but I'm not really sure if that's just a bug. So the proposal is to stop persisting the feed content in Cassandra entirely.
Pros:
- Solve persistent vandalism issue
Cons:
- Can only show in the news card for the current day
- Increased latency
- Increased load on MCS
I personally think that we should do it, but it's mostly product decision whether the benefit of the possibility to show the in-the-news card for previous days overweight the potential persistent vandalism.
Comment Actions
The "in the news" text itself can't really be vandalized as it gets cascade-protected (or semiprotected) on virtually all wikis due to being included on the main page. It's only the image added by MCS (by getting the page image of the first news item, I think?) that's susceptible. So you could
- keep persisting "in the news" but do the image lookup dynamically. There's still some overhead associated with that, but less, and it does not prevent news for previous days from being retrieved.
- use the image(s) included in the "in the news" section instead of trying to come up with an image via custom logic. Those images cannot be vandalised; OTOH they tend to be chosen specifically to look good on the main page (e.g. large images are often cropped) which might not work well for the app use case.
- make page images more vandalism-resistant, e.g. by only using images from patrolled revisions.
Comment Actions
It does give us a pretty significant latency improvement for Varnish cache misses, from 500 ms generating it each time to 230 ms using Cassandra. However, Varnish hit rate is quite high on this particular endpoint: out of 28 req/s that hit Varnishes only about 1.5 req/s is a cache miss.
I've already done the performance evaluation and it's ok.
Comment Actions
Seem to still be an issue. Vandalism to template:Sidebar person at 0709 on 1 January and reverted at 0723 same day still persisting on Wikipedia Android App 36 hours later. Look up George Washington on the Android app to see the result.
Comment Actions
After we've stopped storing the feed content in RESTBase the only place where it can be cached on the server side is Varnish. I've made many requests to https://en.wikipedia.org/api/rest_v1/feed/featured/2017/01/01 and all the responses are fresh and don't contain the news section completely.
Does the app cache the results on the client side?
This comment was removed by • bearND.
Comment Actions
@Pchelolo I cannot find any error log entries for the George_Washington article in the prod logs, and running this locally on my box and on a machine works, so it doesn't seem like an MCS issue to me. Would you see if this page was updated so far this year through ChangeProp?
Comment Actions
@bearND Can't find any logs as well.
Going trough the Kafka logs for change-prop.transcludes.resource-change topic I can see that there were events that triggered mobile-sections refresh and varnish purges for the sections at 07:23 and 07:35 and the events were caused by the Template:Sidebar_person revision creations. Several minutes of delay from the actual revision creation is expected.
Something fishy is going on here..
Comment Actions
So I've looked into renders stored in RESTBase for mobile-sections. There are 2 renders with TIDs that correspond to those rerender events at 07:23 and 07:35, so to me it seems like everything is correct on the storage and update propagation side..
Comment Actions
I've rerendered the affected article, but I've also run a script to find if other articles using this template were affected and apparently there's quite a lot of them. Here's the list
I will run a modified script to purge all of them shortly
Comment Actions
Update: Pchelolo wrote a script to rerender the outstanding pages. So, the pages have been updated.
Comment Actions
Update: the issue was tracked down to the fact that MCS was requesting the Parsoid HTML from RESTBase in eqiad instead of codfw due to the fact that restbase.discovery.wmnet was pointing to restbase.svc.eqiad.wmnet. Because MCS requested the HTML very soon after it has been re-rendered, in certain instances it got the stale version from eqiad's Cassandra. We have switched restbase.discovery.wmnet to point to the local DC this morning, so such cases should not occur any more.