Similar to T148506.
This is about row A only:
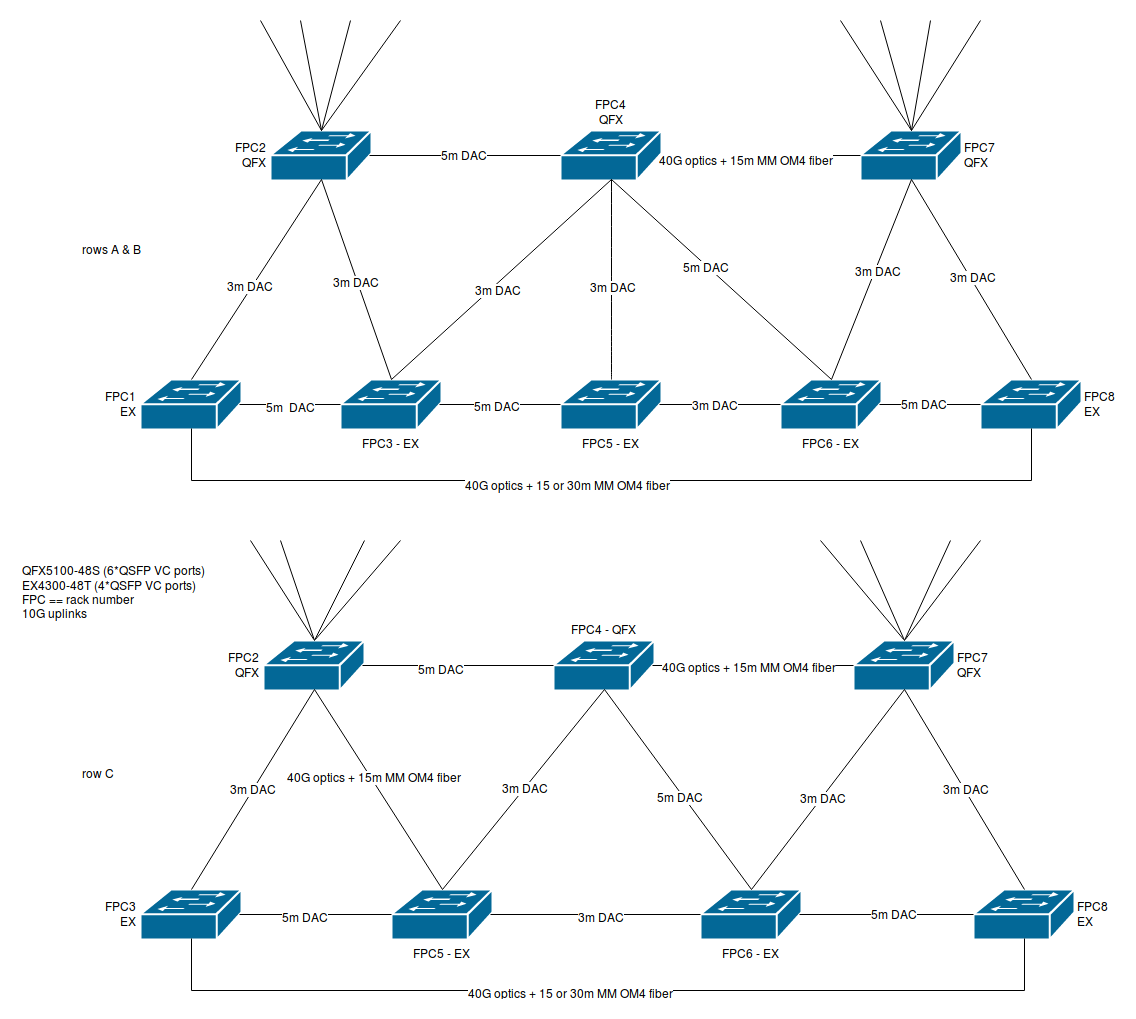
- Rack and cable the switches according to diagram (blocked on T187118) [Chris]
- Connect mgmt/serial [Chris]
- Check via serial that switches work, ports are configured as down [Arzhel]
- Stack the switch, upgrade JunOS, initial switch configuration [Arzhel]
- Add to DNS [Arzhel]
- Add to LibreNMS & Rancid [Arzhel]
- Uplinks ports configured [Arzhel]
- Add to Icinga [Arzhel]
Thursday 22nd, noon Eastern (4pm UTC) 3h (for all 3 rows)
- Verify cr2-eqiad is VRRP master
- Disable interfaces from cr1-eqiad to asw-a
- Move cr1 router uplinks from asw-a to asw2-a (and document cable IDs if different) [Chris/Arzhel]
xe-2/0/44 -> cr1-eqiad:xe-3/0/0 xe-2/0/45 -> cr1-eqiad:xe-3/1/0 xe-7/0/44 -> cr1-eqiad:xe-4/0/0 xe-7/0/45 -> cr1-eqiad:xe-4/1/0
- Connect asw2-a with asw-a with 4x10G (and document cable IDs if different) [Chris]
xe-2/0/42 -> asw-a-eqiad:xe-8/1/0 xe-7/0/42 -> asw-a-eqiad:xe-2/1/0 xe-2/0/43 -> asw-a-eqiad:xe-1/1/0 xe-7/0/43 -> asw-a-eqiad:xe-7/0/0
- Verify traffic is properly flowing though asw2-a
- Update interfaces descriptions on cr1
____
- Switch ports configuration to match asw-a (+login announcement) [Arzhel]
- Solve snowflakes [Chris/Arzhel]
| hostname | old port | new port |
|---|---|---|
| labstore1006 | xe-4/1/0 | xe-4/0/35 |
| cp1075 | xe-4/1/2 | xe-4/0/36 |
- Pre populate FPC2, FPC4 and FPC7 (QFX) with copper SFPs matching the current production servers on rack 2, 4 and 7 [Chris]
ge-2/0/1 up up es1011 ge-2/0/2 up up es1012 ge-2/0/3 up up ms-be1019 ge-2/0/4 up up db1074 ge-2/0/5 up up db1075 ge-2/0/6 up up db1079 ge-2/0/12 up up kafka-jumbo1002 ge-2/0/13 up up tungsten ge-2/0/16 up up db1080 ge-2/0/17 up up analytics1012 no-bw-mon ge-2/0/18 up up analytics1013 no-bw-mon ge-2/0/19 up up notebook1002 ge-2/0/20 up up conf1001 ge-2/0/21 up up db1081 ge-2/0/22 up up db1082 ge-2/0/23 up up db1107 ge-4/0/0 up up druid1001 ge-4/0/1 up up aqs1004 ge-4/0/2 up up scb1001 ge-4/0/3 up up logstash1004 ge-4/0/4 up up kubestage1001 ge-4/0/5 up up snapshot1005 ge-4/0/6 up up analytics1070 ge-4/0/8 up up oxygen ge-4/0/9 up up maps1001 ge-4/0/12 up up holmium ge-4/0/15 up up conf1004 ge-4/0/16 up up db1111 ge-4/0/17 up up rhenium ge-4/0/19 up up lvs1001 ge-4/0/20 up up lvs1002 ge-4/0/21 up up lvs1003 ge-4/0/22 up up netmon1002 ge-4/0/25 up up kafka1001 ge-4/0/26 up up contint1001 ge-4/0/27 up up ganeti1005 ge-4/0/30 up up restbase1007 ge-4/0/31 up up stat1004 ge-4/0/32 up up oresrdb1002 ge-4/0/34 up up wdqs1003 ge-4/0/43 up up rdb1003 ge-7/0/6 up up mw1267 ge-7/0/7 up up mw1268 ge-7/0/8 up up mw1269 ge-7/0/9 up up mw1270 ge-7/0/10 up up mw1271 ge-7/0/11 up up mw1272 ge-7/0/12 up up mw1273 ge-7/0/13 up up mw1274 ge-7/0/14 up up mw1275 ge-7/0/15 up up mw1276 ge-7/0/16 up up mw1277 ge-7/0/17 up up mw1278 ge-7/0/18 up up mw1279 ge-7/0/19 up up mw1280 ge-7/0/20 up up mw1281 ge-7/0/21 up up mw1282 ge-7/0/22 up up mw1283
- Ping service owners 30min before moving link (see bellow) [Arzhel]
In maintenance window - 3h - Tuesday 19th 14:00UTC - https://everytimezone.com/s/de2dcd7c
- Move servers from asw-a to asw2-a [Chris]
No special need or easy depool (one at a time)
A1: ge-1/0/6 - wdqs1006 ge-1/0/7 - kafka-jumbo1001 - ping Luca before moving host ge-1/0/8 - dns1001 ge-1/0/9 - labsdb1009 no special need A2: ge-2/0/1 - es1011 ge-2/0/2 - es1012 ge-2/0/3 - ms-be1019 ge-2/0/4 - db1074 ge-2/0/5 - db1075 ge-2/0/6 - db1079 ge-2/0/12 - kafka-jumbo1002 - ping Luca before moving host, wait for 1001 to be full up ge-2/0/16 - db1080 ge-2/0/17 - analytics1012 ge-2/0/18 - analytics1013 ge-2/0/19 - notebook1002 ge-2/0/20 - conf1001 - spare - do at any point in time ge-2/0/21 - db1081 ge-2/0/22 - db1082 A3: ge-3/0/3 - dbproxy1001 spare ge-3/0/4 - dbproxy1002 spare ge-3/0/5 - prometheus1003 - ok to have a network blip of a few seconds, depool optional ge-3/0/7 - cp1008 - depool first ge-3/0/8 - elastic1032 ge-3/0/9 - elastic1033 ge-3/0/10 - elastic1034 ge-3/0/11 - elastic1035 ge-3/0/12 - dbproxy1003 spare ge-3/0/13 - db1103 ge-3/0/14 - relforge1001 ge-3/0/16 - restbase1010 1G - pybal depool ge-3/0/17 - restbase1011 1G - pybal depool ge-3/0/20 - kubernetes1001 ge-3/0/21 - restbase1016 eth0 - pybal depool ge-3/0/22 - restbase1016 eth1 - should be down, remove cable ge-3/0/23 - restbase1016 eth2 - should be down, remove cable ge-3/0/24 - elastic1030 ge-3/0/25 - elastic1031 ge-3/0/26 - analytics1052 ge-3/0/27 - analytics1053 ge-3/0/28 - analytics1054 ge-3/0/29 - analytics1055 ge-3/0/30 - analytics1056 ge-3/0/31 - analytics1057 ge-3/0/32 - cloudservices1004 - Ping WMCS team before ge-3/0/33 - analytics1059 ge-3/0/34 - analytics1060 A4: ge-4/0/0 - druid1001 ge-4/0/1 - aqs1004 - ensure aqs1007 is up ge-4/0/2 - scb1001 - poweroff gracefully to drain traffic, can do at any time ge-4/0/3 - logstash1004 - spare, can be done at any time ge-4/0/4 - kubestage1001 ge-4/0/6 - analytics1070 ge-4/0/8 - oxygen - spare - do at any point in time ge-4/0/9 - maps1001 ge-4/0/12 - labservices1002 - Ping WMCS team ge-4/0/15 - conf1004 - etcd/zookeeper, make sure a service ops person is around ge-4/0/16 - db1111 test host ge-4/0/17 - rhenium ge-4/0/21 - lvs1003 ge-4/0/22 - netmon1002 ge-4/0/25 - kafka1001 - Ping Luca to stop Kafka ge-4/0/30 - restbase1007 - pybal depool ge-4/0/31 - stat1004 - Analytics ge-4/0/32 - oresrdb1002 - Fine to do at any time ge-4/0/34 - wdqs1003 xe-4/1/2 - cp1075 - depool first A6: ge-6/0/0 - db1096 ge-6/0/2 - mw1307 ge-6/0/3 - mw1308 ge-6/0/4 - mw1309 ge-6/0/5 - mw1310 ge-6/0/6 - mw1311 ge-6/0/7 - mw1312 ge-6/0/8 - labcontrol1003 - Ping WMCS team ge-6/0/9 - restbase-dev1004 ge-6/0/10 - ores1001 ge-6/0/11 - db1116 - backups host ge-6/0/12 - druid1004 ge-6/0/13 - labmon1002 - Ping WMCS team ge-6/0/14 - db1115 tendril master (no special need) ge-6/0/18 - weblog1001 - make sure a serviceops person is around ge-6/0/23 - elastic1048 ge-6/0/24 - aqs1007 - ensure aqs1004 is up ge-6/0/25 - mc1019 - One at a time check with Luca or Joe before proceeding to next ge-6/0/26 - mc1020 - One at a time check with Luca or Joe before proceeding to next ge-6/0/27 - mc1021 - One at a time check with Luca or Joe before proceeding to next ge-6/0/28 - mc1022 - One at a time check with Luca or Joe before proceeding to next ge-6/0/29 - mc1023 - One at a time check with Luca or Joe before proceeding to next ge-6/0/30 - wtp1025 ge-6/0/31 - wtp1026 ge-6/0/32 - dbproxy1013 - spare ge-6/0/34 - elastic1044 ge-6/0/35 - elastic1045 ge-6/0/36 - wtp1027 ge-6/0/37 - wdqs1004 A7: All mw*, one at a time A8: ge-8/0/2 - db1118 ge-8/0/3 - torrelay1001 ge-8/0/4 - bohrium eth0 - status planned ge-8/0/5 - bohrium eth1 - status planned ge-8/0/8 - labstore1003 - Sync up with Brooke (needs Icinga downtime) ge-8/0/10 - Core: mr1-eqiad:ge-0/0/1 ge-8/0/13 - helium - fine to do at any point in time, graceful poweroff
Special needs or unsorted
A1: ge-1/0/5 - db1069 x1 master - set read only (coordinate with @Addshore to set Cognate in read only) A2: ge-2/0/13 - tungsten - xhgui:app - test system, check with performance team ge-2/0/23 - db1107 - Give 10min head's up to elukey A3: ge-3/0/2 - ganeti1007 - Ensure other hosts are up, drain VMs - will probably need a different timeslot that ganeti1005, ganeti1006 ge-3/0/19 - rdb1005 - ?? A4: ge-4/0/5 - snapshot1005 - Ariel? ge-4/0/19 - lvs1001 - Ensure other hosts are up, disable pybal ge-4/0/20 - lvs1002 - Ensure other hosts are up, disable pybal ge-4/0/26 - contint1001 - Ping hashar, need to shutdown CI ge-4/0/27 - ganeti1005 - Ensure other hosts are up, drain VMs - will probably need a different timeslot than ganeti1004, ganeti1006 ge-4/0/43 - rdb1003 - ?? xe-4/1/0 - labstore1006 - Sync up with Brooke (need service failover) A6: ge-6/0/1 - ganeti1006 - Ensure other hosts are up, drain VMs - - will probably need a different timeslot than ganeti1004, ganeti1005 ge-6/0/15 - an-master1001 - Ping Luca for failover before ge-6/0/16 - db1066 - s2 master see T217441 ge-6/0/45 - lvs1004:eth1 - Ensure other hosts are up, disable pybal ge-6/0/46 - lvs1005:eth1 - Ensure other hosts are up, disable pybal ge-6/0/47 - lvs1006:eth1 - Ensure other hosts are up, disable pybal
- Failover VRRP master to cr1-eqiad and verify status + traffic shift [Arzhel]
cr2 set interfaces ae1 unit 1001 family inet address 208.80.154.3/26 vrrp-group 1 priority 70 set interfaces ae1 unit 1001 family inet6 address 2620:0:861:1:fe00::2/64 vrrp-inet6-group 1 priority 70 set interfaces ae1 unit 1017 family inet address 10.64.0.3/22 vrrp-group 17 priority 70 set interfaces ae1 unit 1017 family inet6 address 2620:0:861:101:fe00::2/64 vrrp-inet6-group 17 priority 70 set interfaces ae1 unit 1030 family inet address 10.64.5.3/24 vrrp-group 30 priority 70 set interfaces ae1 unit 1030 family inet6 address 2620:0:861:104:fe00::2/64 vrrp-inet6-group 30 priority 70 set interfaces ae1 unit 1117 family inet address 10.64.4.3/24 vrrp-group 117 priority 70 set interfaces ae1 unit 1117 family inet6 address 2620:0:861:117:fe00::2/64 vrrp-inet6-group 117 priority 70 On cr1/2: show vrrp summary -> master/backup
- Disable cr2-eqiad:ae1 [Arzhel]
- Move cr2 router uplinks from asw-a to asw2-a (and document cable IDs if different) [Chris/Arzhel]
xe-2/0/46 -> cr2-eqiad:xe-3/0/0 xe-2/0/47 -> cr2-eqiad:xe-3/1/0 xe-7/0/46 -> cr2-eqiad:xe-4/0/0 xe-7/0/47 -> cr2-eqiad:xe-4/1/0
- Enable cr2-eqiad:ae1 [Arzhel]
- Re-move VRRP master to cr2-eqiad [Arzhel]
- Update interfaces descriptions on cr2
- Verify no more traffic on asw-a<->asw2-a link [Arzhel]
- Disable asw-a<->asw2-a link [Arzhel]
- Verify all servers are healthy, monitoring happy [Arzhel]
After maintenance window
T208734