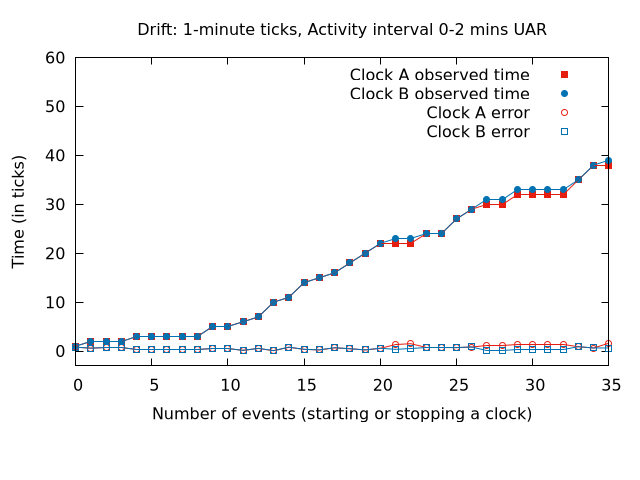
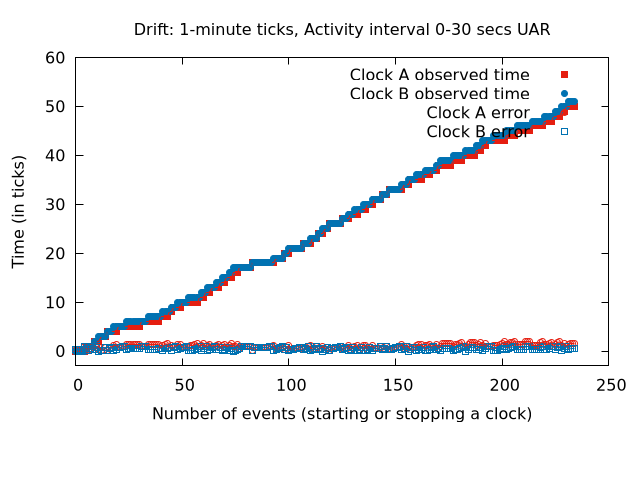
Implementing session length on top of refactored eventlogging code that can post events to eventgate.
- session length schema creation: T254897
- heartbeat algorithm implementation (https://wikitech.wikimedia.org/wiki/Analytics/Data_Lake/Traffic/SessionLength)
- oozie job to compute session length metrics based on heartbeat per wiki
We need to decide whether to sample the data or- at the beginning- just enable the computation in one wiki