Update
This is an instruction page for "undelete archiving" functionality, deployed at http://undeltest.wmflabs.org/.
What does it do?
It implements the functionality of indexing deleted pages via ElasticSearch (CirrusSearch extension). This complements indexing usually available for existing pages, so you can now search for partial and unexact matches for the name of the deleted page in Special:Undelete page.
How can I test it?
Note: You may need to fill a captcha when editing - use word "mellon" for it.
- Go to http://undeltest.wmflabs.org/.
- Create a new page, for example "Mac and Cheese" - be creative and invent your own name though, if everybody uses the same title it would not give diverse feedback.
- Login as Admin with the password described here: MediaWiki-Vagrant docs at number 7.
- Delete the page you created in (2).
- Go to http://undeltest.wmflabs.org/wiki/Special:Undelete and search for "'''chease'''" (note partial and inexact match) - again, be creative with your own title but not ''too creative'' - the name should be still close to what you are looking for to be found.
- Observe that the page deleted in (2) is in the list.
- Give us feedback!
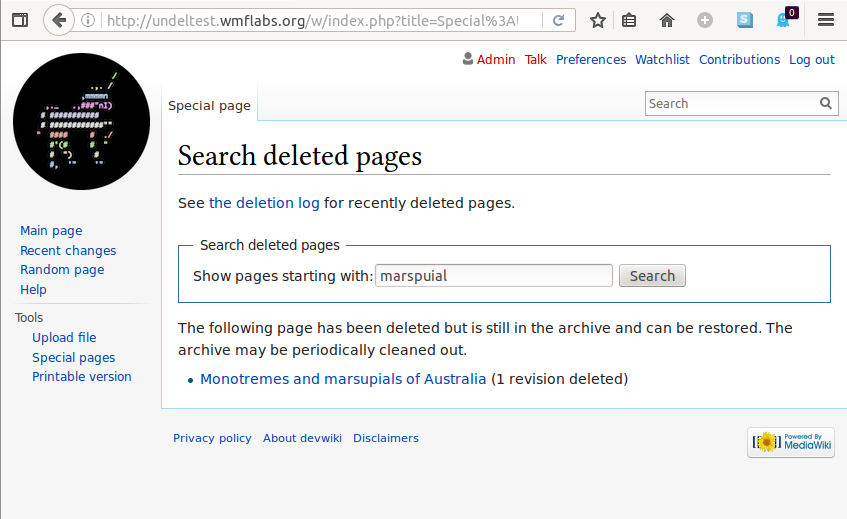
It will look and function, something like this:

What unholy magic is this?
The patches are at:
https://gerrit.wikimedia.org/r/#/c/281078/ (core part)
https://gerrit.wikimedia.org/r/#/c/281077/ (CirrusSearch part)
You are welcome to review/comment.
Original description
As an administrator, I want to search the archive table for deleted pages whose title I don't exactly remember, or are similar in nature -- e.g. "Dr. John Smith", "John Anthony Smith" and "John Smith".
Discussion on en.wp's admin noticeboard.
This card tracks a proposal from the 2015 Community Wishlist Survey: https://meta.wikimedia.org/wiki/2015_Community_Wishlist_Survey
This proposal received 37 support votes, and was ranked #27 out of 107 proposals. https://meta.wikimedia.org/wiki/2015_Community_Wishlist_Survey/Search#Provide_a_means_of_searching_for_deleted_pages