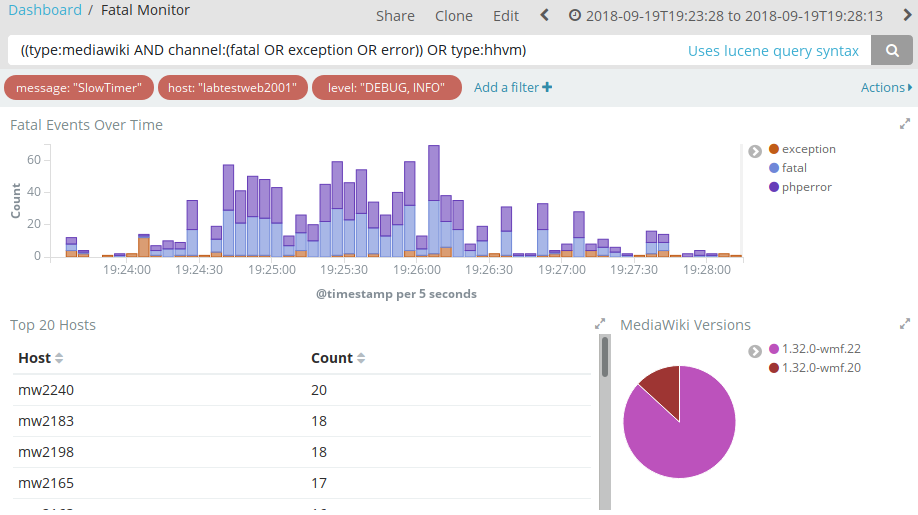
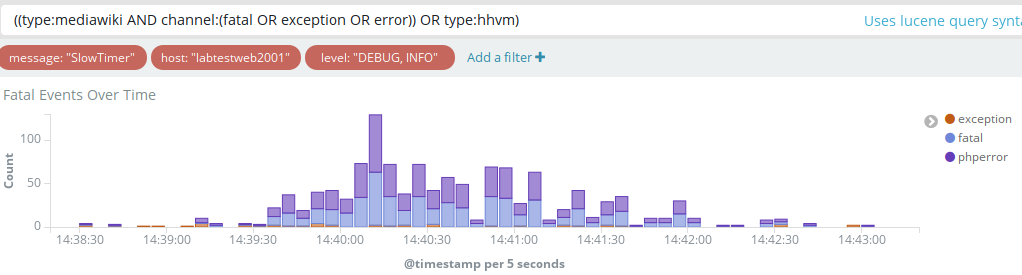
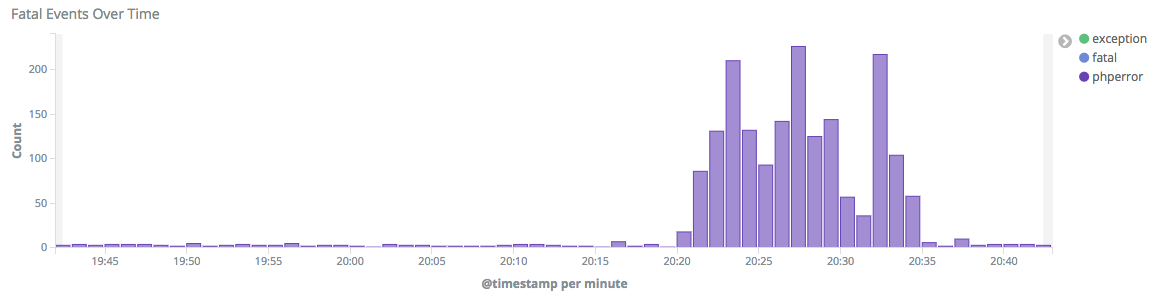
After promoting group1 to 1.32.0-wmf.22 I noticed a spike of web request took longer than 60 seconds and timed out. Roughly from 19:24 to 19:28. That happened after the deployment:
19:19:43 <wikibugs> (Merged) jenkins-bot: group1 wikis to 1.32.0-wmf.22 [mediawiki-config] - https://gerrit.wikimedia.org/r/461456 (owner: Hashar)
19:24:50 <logmsgbot> !log hashar@deploy1001 rebuilt and synchronized wikiversions files: group1 wikis to 1.32.0-wmf.22
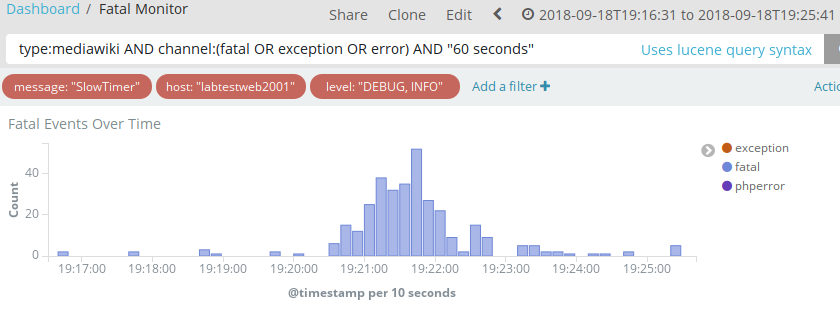
From logstash query type:mediawiki AND channel:(fatal OR exception OR error) AND "60 seconds":