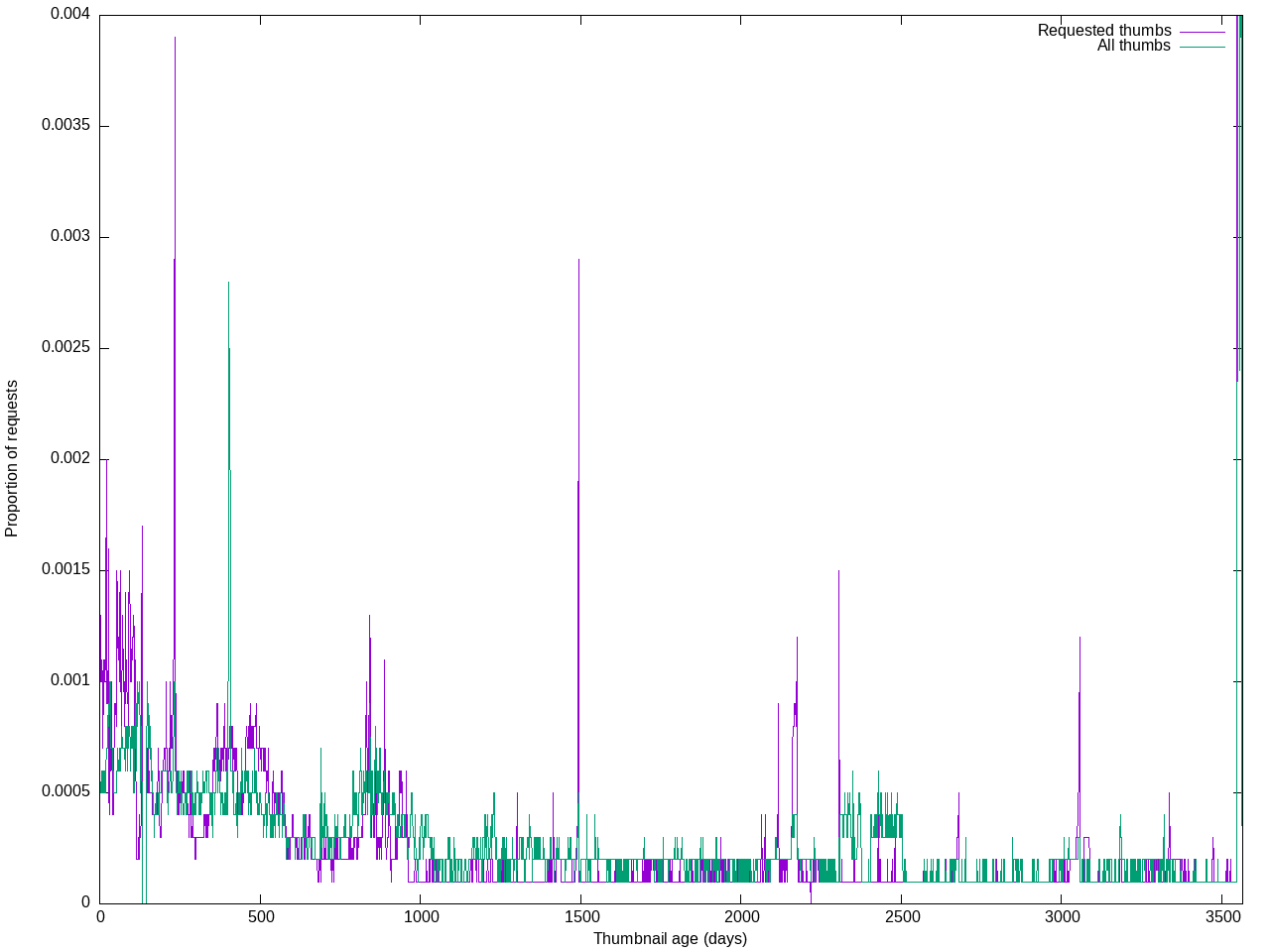
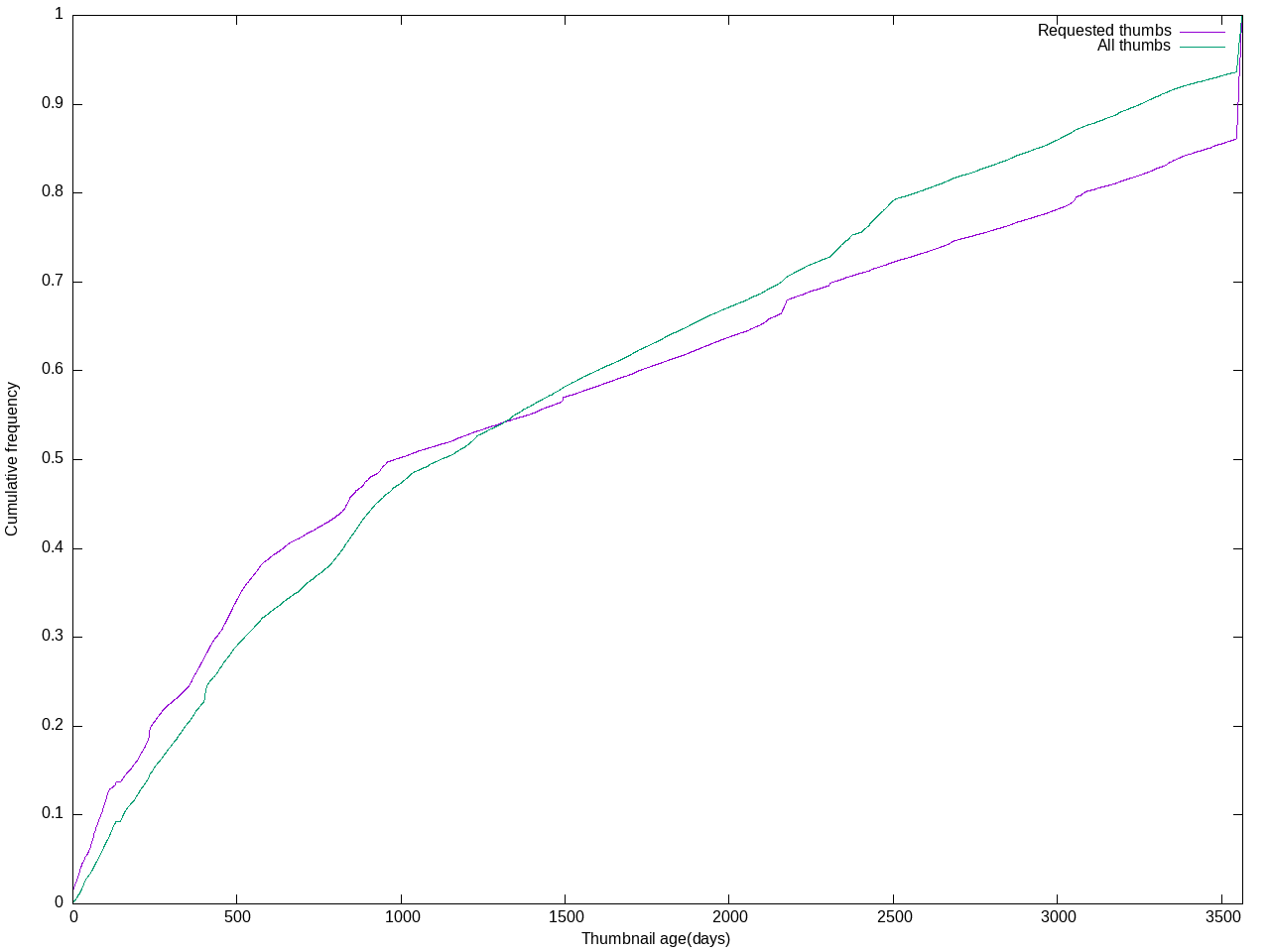
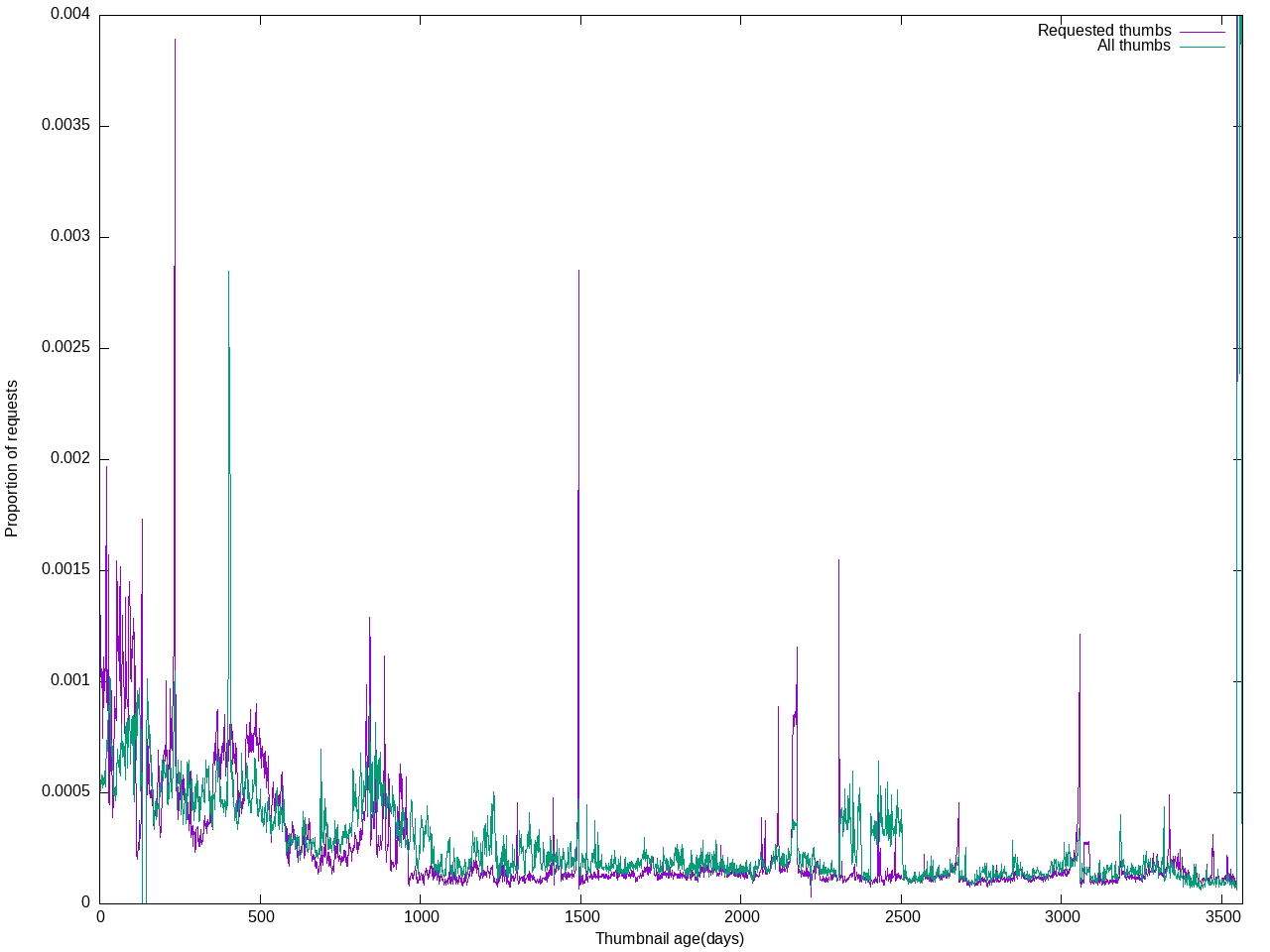
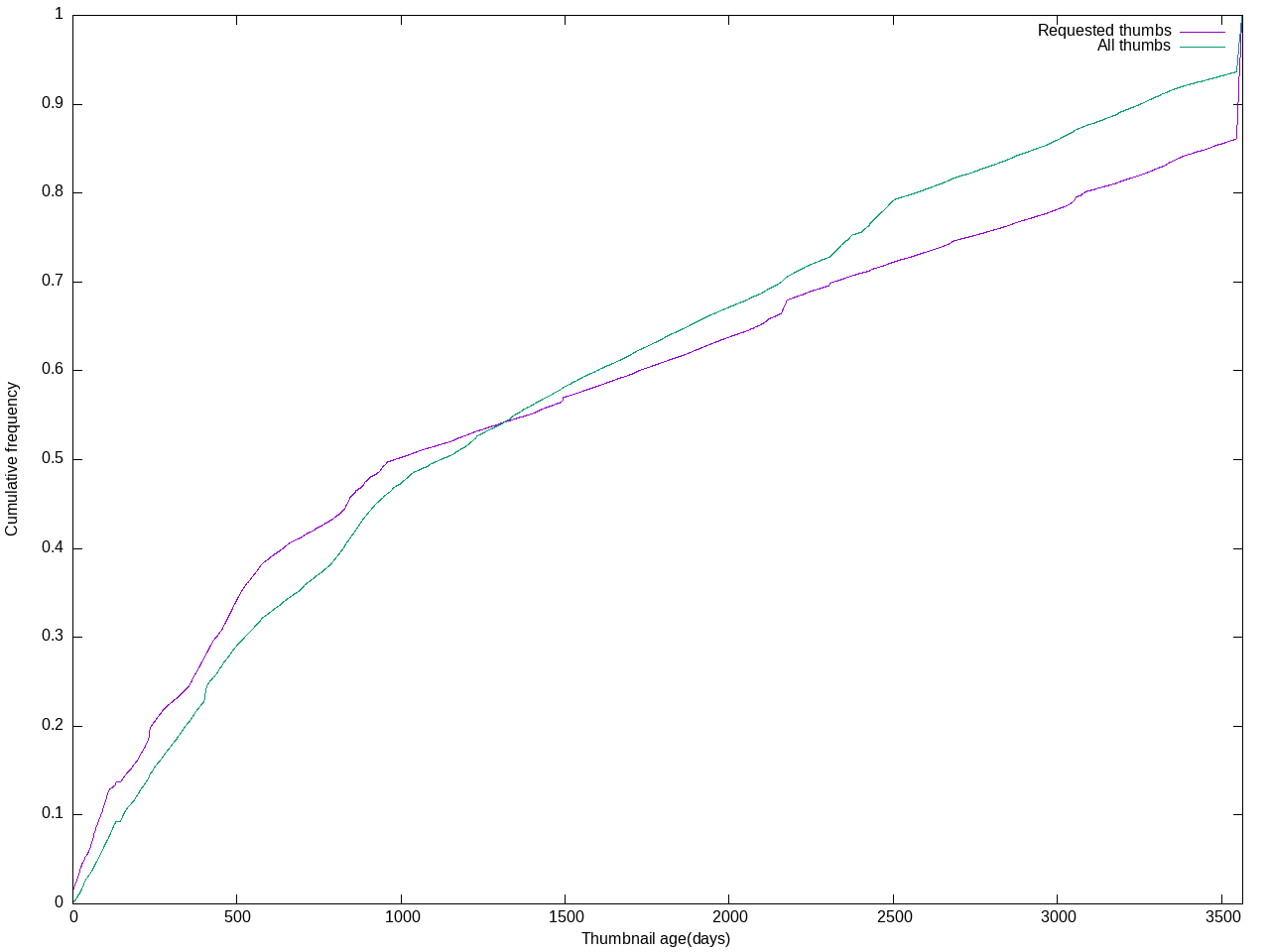
In order to make room for enabling WebP thumbnail generation for all images, we need to have a continuous (or regular) cleanup mechanism for little-accessed thumbnails on Swift.
This job would delete thumbnails that meet the following criteria:
- hasn't been accessed in 30 days
- still has an original
The continuous/regular nature of the job is useful to allow us to introduce new thumbnail formats in the future. For example, serving thumbnails of lower quality to users with Save-Data enabled, or new formats on the horizon like AVIF (AV1's equivalent of WebP, which is said to vastly outperform WebP).