Library: https://github.com/rahiel/open_nsfw--
It uses python and some weird "coffee" serialization format. We could probably include this in ORES without too much trouble depending on what memory usage looks like.
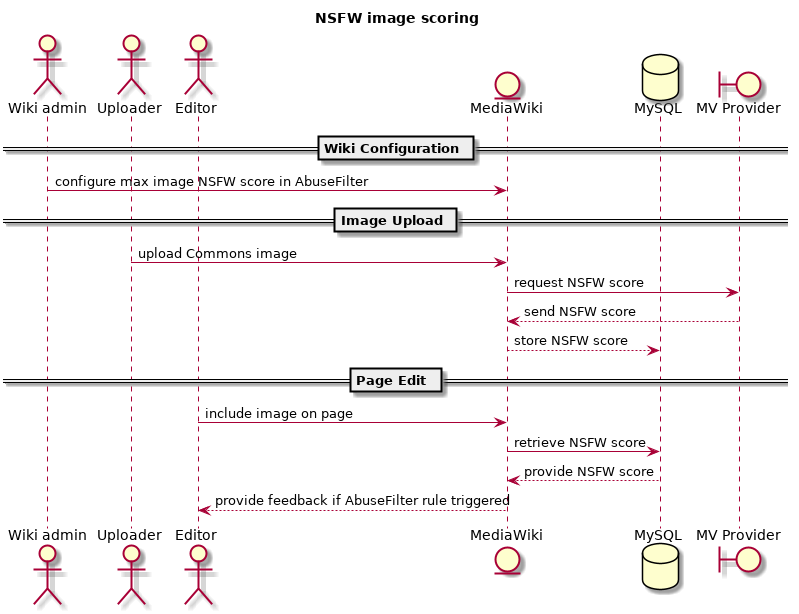
Intended use: Flag edits to Wikipedia articles that add NSFW images/media for review.
Strategy:
- See if ORES can even handle this.
- Try hosting a model in labs.
- Look into tools that might help reviewers who are trying to catch vandalism that follows this pattern.
Background:
Some vandalism comes in the form of edits that inappropriately add NSFW images to articles. The clear intention behind this type of vandalism is to shock an innocent reader. By flagging edits that add NSFW for secondary review, we can help patrollers track these types of edits.
For clarity, there is no plan to use this to filter images from articles for which they are appropriate. Many NSFW images are welcome on commons and in various Wikipedia articles. The intention is instead to help patrollers work with a specific type of vandalism.
Diagram: