Steps to replicate the issue (include links if applicable):
- Pick a page created months ago on Wikisource, for instance, https://de.wikisource.org/w/index.php?title=Zedler:Puppenwerck&oldid=3795414 (June 2021)
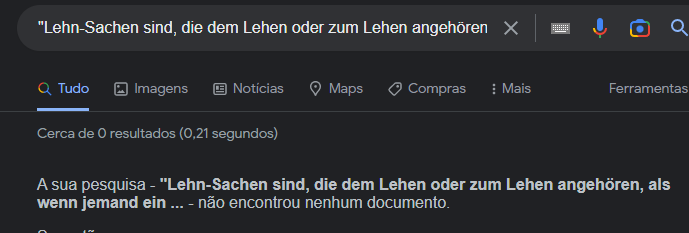
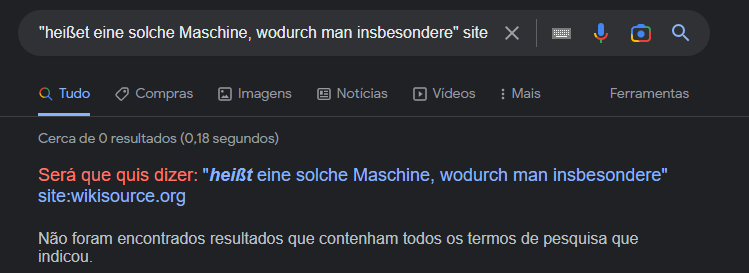
- Pick a sentence from the page and search for it on Google.
- If that works, then try with a different page (e.g. via Special:Random), because often the URLs used to talk about this bug do end up getting indexed and so no longer show the bug in operation.
What happens?:
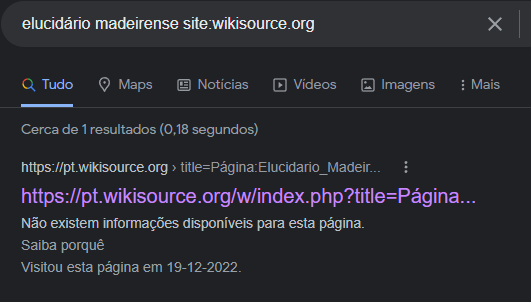
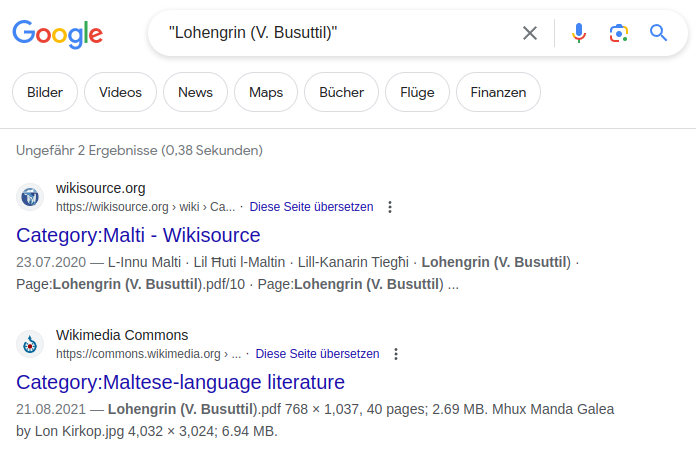
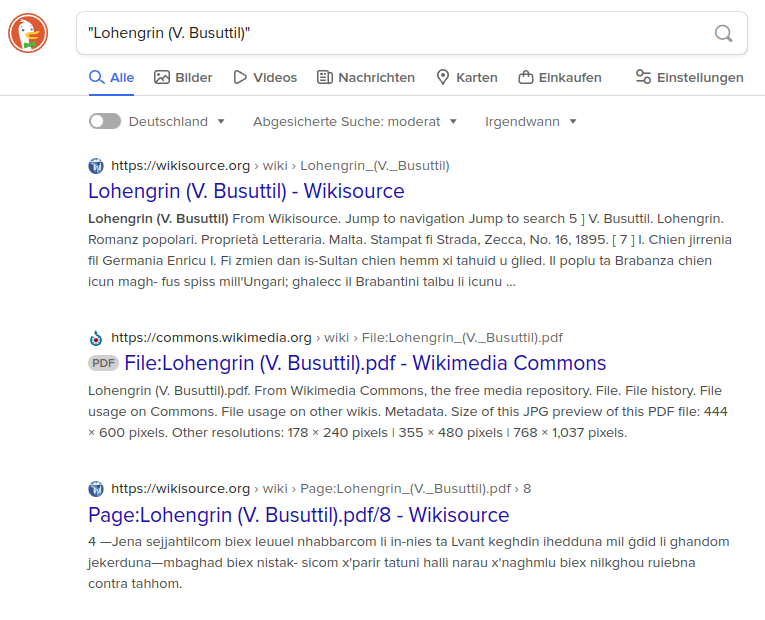
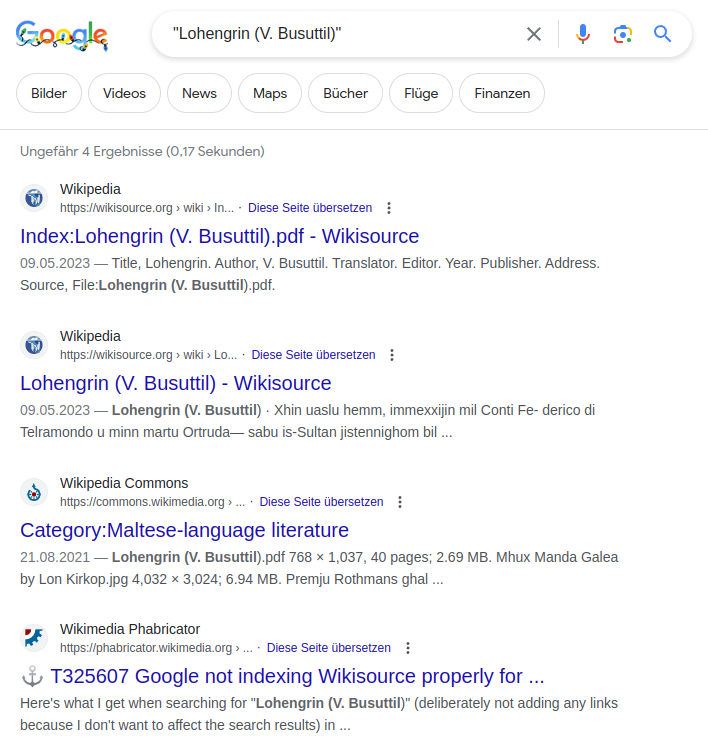
No results on Wikisource appear.
What should have happened instead?:
Should be indexed by Google.
Software version (skip for WMF-hosted wikis like Wikipedia):
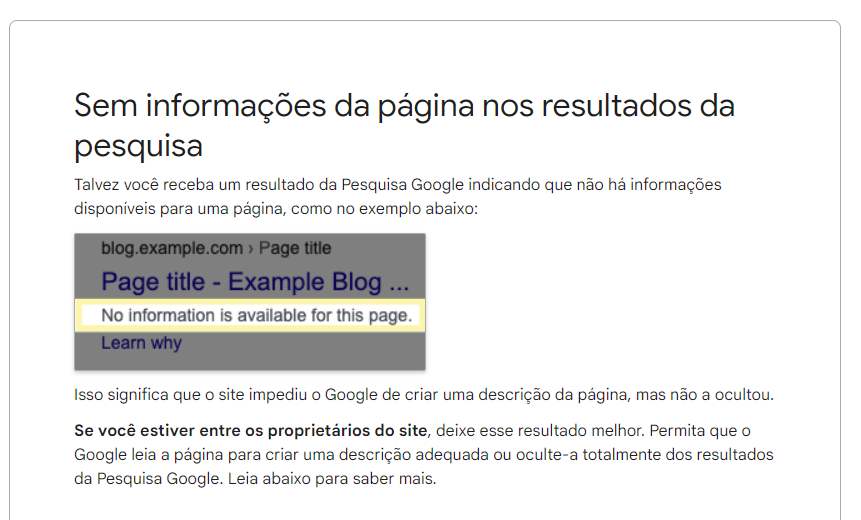
Other information (browser name/version, screenshots, etc.):
Detected first on ws.pt, tested on ws.es, ws.he, ws.fr, ws.de, ws.en, with similar results: Google doesn't seem to be indexing new pages from Wikisource, which greatly diminishes the value of this project, and renders basically impossible any partnership based on it - we are preparing one with the National Library of Portugal, with other tasks running related to a number of other Portuguese archives and repositories.
This one seems to have been an exception, as it appears in the Google search, even if with an outdated version - https://pt.wikisource.org/wiki/Solicita%C3%A7%C3%B5es_do_Bangu%C3%AA/C001/10
Somewhat similar results on Bing.
Can someone have a look at this with the Google Search Console?
Seems to be related to T238090 and https://support.google.com/webmasters/thread/16243149/google-no-longer-indexing-some-wikisource-pages?hl=en
Possibly related to this T318046