Type of activity: Pre-scheduled session.
Main topic: Handling wiki content beyond plaintext
The problem
VisualEditor is a friendly means to edit *content*, but it presently provides no means to author *templates*, which are an important component of our projects.
We can use Visual Editor to edit templates, and in the process better separate code, content, and presentation. I'm going to call these "Visual Templates".
Here are the key ideas:
- A minimal "logic-less" template language, like the Spacebars or htmlbars variants of Handlebars/mustache templates. There are only three basic template constructs (variable interpolation, block tags, and partials), which can all be visualized in the editor. There are no hidden directives.
- All logic is written in a real programming language, via Scribunto (or something very much like it). In the examples below I'll be using a version of Scribunto that supports ECMAScript 2015 as well as Lua; forgive my eccentricities.
- All data is escaped and hygienic by default. String data is automatically escaped. The Scribunto code manipulates and returns [DocumentFragments](https://developer.mozilla.org/en-US/docs/Web/API/DocumentFragment), not wikitext strings.
- Similarly, arguments are provided as JSON types (strings/numerical data), DocumentFragments, or wikidata queries, not wikitext.
- Composition of content is structural, not string concatenation. You can't "accidentally" create a list item if your template result happens to start with a : or *.
So: every Visual Template is composed of two parts: a Scribunto module (edited with a code editor), and a "layout" (edited with Visual Editor).
Here's what the layout of a particular template might look like:
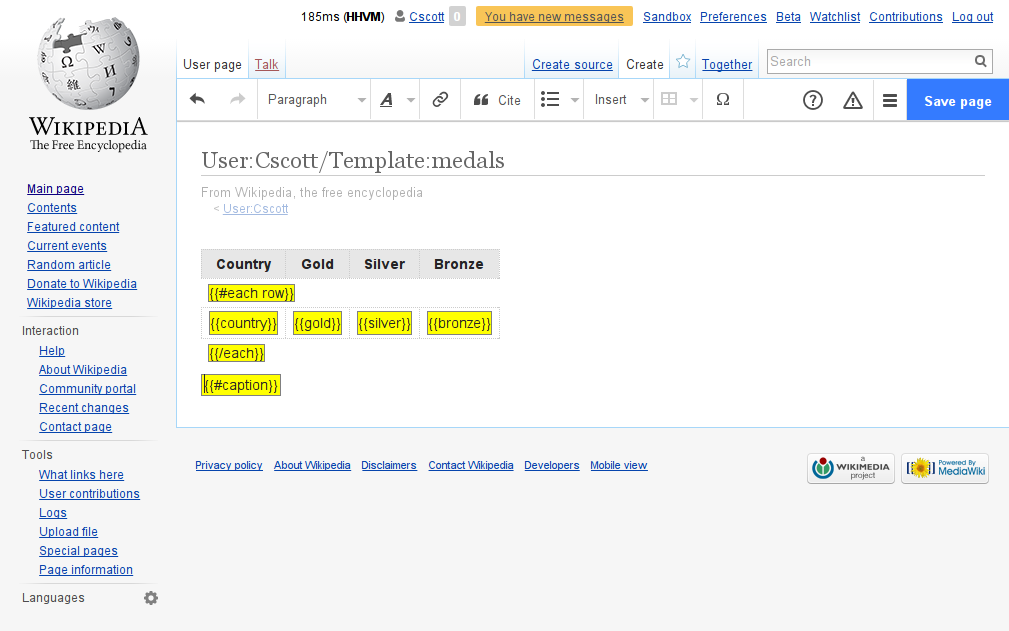
Forgive the terrible yellow; a designer could make this look much nicer. Note that there are two "block helper" invocations, each and caption. The each helper is a built-in, and it is given row from the template data context object. The caption helper is defined by the Scribunto module. Each row of the table gets "variable" invocations to fill in the table cells.
There are only three new functions added to the VE toolbar in template mode, for inserting "variable", "block helper", and "partial" elements. Context-sensitive help will be given to choose from available variable, block helper, and partial names.
The invocation of this template would, for this example, take structured data of the following form, perhaps from a wikidata query:
| event | gold | silver | bronze |
| Shotput | USA | GER | MEX |
| Discus | MEX | USA | GER |
| Javelin | GER | MEX | USA |
The Scribunto module transforms this raw data by computing medal counts for each country. Here's what it might look like, using JavaScript 2015 (ES6) module syntax,
// The main module entry point is a transformation of a "data context".
// In this example the data context comes from a wikidata query.
export default function(events) {
// `events` is an array: each item has `event`, `gold`, `silver`, and `bronze` props
// (the latter three holding country names)
let totals = new Map(), countries = new Set(), allColors = ['gold','silver','bronze'];
function mget(m, key, defaultval) {
if (!m.has(key)) { m.set(key, defaultval); }
return m.get(key);
}
function inc(country, color) {
let old = mget(mget(totals, country, new Map()), color, 0);
totals.get(country).set(color, old + 1);
countries.add(country);
}
// count up how many medals of each color a given country has.
events.forEach( (e) => {
for (let color of allColors) { inc(e[color], color); }
}):
// Now sort the countries by medal count
let rows = Array.from(countries).sort( (a,b) => {
let aa = totals.get(a), bb = totals.get(b);
for (let color of allColors) {
let c = aa[color] - bb[color];
if (c!==0) { return c; }
}
return c;
}).map( (c) => totals.get(c) );
// our resulting data context object has just one
// property, named 'rows', which is an array.
return { row: rows };
}
// Additional block helper. Helpers must return a `DocumentFragment`,
// though for brevity we allow `Node` or `Array<Node>` as well.
// In fact, if you returned a string we'd make a text node for you,
// but that would make this example even more trivial.
export function caption() {
return document.createTextNode('caption');
}The default entry point transforms the template arguments to set up the template data context. It does no text manipulation. There is a second caption entry point, which defines the caption block helper. The exact API used in block helpers definitions might be tweaked: one obvious improvement would be to allow jquery methods for DOM construction, instead of using the DOM API directly. The key point is that the result is conceptually a chunk of structural DOM, not a wikitext string.
Visual Template invocation in Visual Editor
The primary authoring mechanism for Visual Templates is expected to be Visual Editor. The UX is expected to be roughly the same as exists now for templates: a mechanism like TemplateData exposes the expected types of arguments and descriptive text, so that Visual Editor can expose appropriate editing widgets. Initially the expected types are: "markup" (edited with VE recursively), JSON (edited with a JSON editor, as with TemplateData), and "wikidata" (a SPARQL wikidata query).
Visual Template Invocation in wikitext
This is a strawman for the wikitext serialization of a template invocation:
{{#visual
template_name
param1=<markup>'''bold'''</markup>
param2=<json>{"foo":"bar"}</json>
param3=<wikidata>
SELECT ?spaceProbeLabel ?date ?picture
WHERE {
?spaceProbe wdt:P31 wd:Q26529 ;
wdt:P18 ?picture ;
wdt:P619 ?date .
SERVICE wikibase:label {
bd:serviceParam wikibase:language "fr,en" .
}
}
ORDER BY ?date
</wikidata>
}}The parameter name entity is reserved; the data context object for the template always includes the wikidata entity object (equivalent to mw.wikibase.getEntityObject()) as an implicit parameter named entity. This makes it easy to generate infoboxes (for example), since you can just insert {{#formatproperty entity.P17}} in your template (equivalent to entity.formatPropertyValues( 'P17' ).value). Hopefully there will be a friendly shortcut for entity.<something>, which will include mapping wikidata identifier <something> to a label in your language.
Since arguments are delimited by html-style tags, the usual & and < escapes are all that are required to include arbitrary data inside a parameter, and whitespace can be used to separate arguments. The parameter names can be omitted for positional arguments.
Perhaps we can allow for an abbreivated format for certain arguments: "..." -> literal string, \d+ -> number, {...} -> JSON value. Then unit conversion (for example) can still be simply {{#visual convertToMiles 5 km}}
*Syntax details can be tweaked: your input wanted!*
Expected outcome
- The primary goal for the summit would be to stimulate discussion of "visual template editing" in general, and agree on a strategy. Is template authorship always going to be a function of wikitext? Or do we want to build a specialized IDE with little resemblance to VE? What's the 10-year view for templates?
- From this discussion, hopefully a subset of this proposal could be identified which can achieve consensus as a reasonable "first step" for experimental implementation.
- A secondary goal would be to stimulate interest in/discussion of/development of related technologies, for example alternate templating engines or Scribunto/Js.
Current status of the discussion
Mailing list discussion: https://lists.wikimedia.org/pipermail/wikitech-l/2015-October/083467.html
Discussion below as well.
Links
*See also:* T114251: [RFC] Magic Infobox implementation