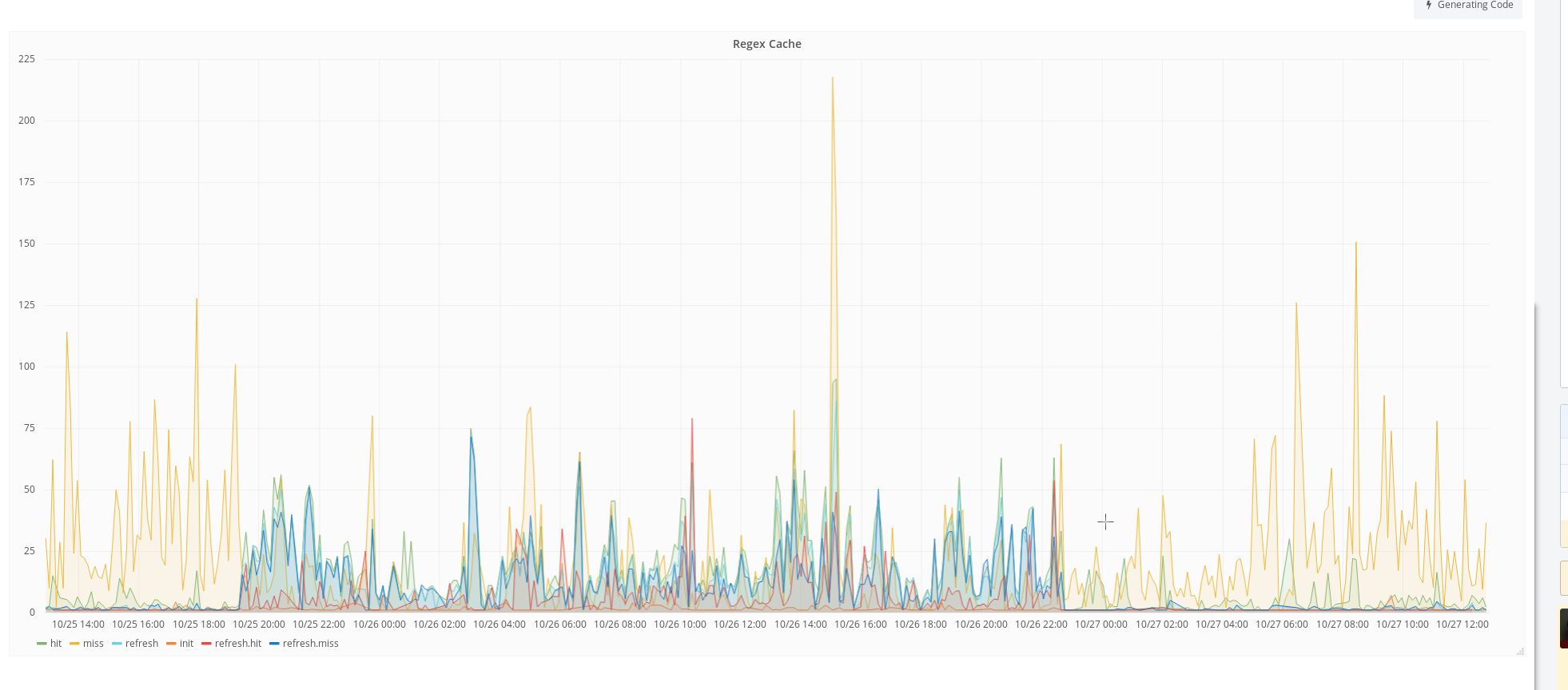
Starting at around 18:45 on October 26 we had a huge spike of 503s.

The perceivable problem on cp1053 were to many open connections to the backend, leaving no room for new requests. As we weren't able to identify what actually caused the connection limit exhaustion, we tried to disable several recently deployed/ potentially troublesome things.
Finally lifting the connection limit from 1k to 10k on cp1053 mitigated the problem, but the underlying issue is most likely still not resolved.
Related SAL entries:
03:02 bblack: cp1067, cp4026 - backend restarts, mailbox lag 22:47 demon@tin: rebuilt wikiversions.php and synchronized wikiversions files: wikidata to wmf.4 22:39 bblack: restarting varnish-backend on cp1053 (mailbox lag from ongoing issues elsewhere?) 21:40 bblack: raising backend max_connections for api.svc.eqiad.wmnet + appservers.svc.eqiad.wmnet from 1K to 10K on cp1053.eqiad.wmnet (current funnel for the bulk of the 503s) 21:32 hoo@tin: Synchronized wmf-config/InitialiseSettings.php: Temporary disable remex html (T178632) (duration: 00m 50s) 21:30 hoo@tin: Synchronized wmf-config/InitialiseSettings.php: Temporary disable remex html (T178632) (duration: 00m 50s) 21:00 hoo: Fully revert all changes related to T178180 20:59 hoo@tin: Synchronized wmf-config/Wikibase.php: Revert "Add property for RDF mapping of external identifiers for Wikidata" (T178180) (duration: 00m 50s) 20:02 ladsgroup@tin: Synchronized wmf-config/InitialiseSettings.php: UBN! disbale ores for wikidata (T179107) (duration: 00m 50s) 20:00 ladsgroup@tin: Synchronized wmf-config/InitialiseSettings.php: UBN! disbale ores for wikidata (T179107) (duration: 00m 50s)
Changes done during investigation that need to be undone:
- Move wikidatawiki back to wmf5
- Re-enable remex html (T178632)
- Re-enable the RDF mapping of external identifiers on Wikidata (T178180)
- Re-enable constraints check with SPARQL
- Re-enable ORES on wikidata (T179107)
- Revert https://gerrit.wikimedia.org/r/387028 if needed (but maybe not to 100s which seems a little excessive)
Also the train was halted due to this (T174361).