This is a parent task for the work to be done for the Modern Event Platform Program, and the 2022+ Event Platform Value Stream.
Engineering teams should be able to easily produce instrumentation events, as well as build event driven systems, on top of Event Platform components.
For some historical context see:
Background reading
Components
Each of the components described below are units of technical output of this program. They are either deployed services/tools, or documentation and policy guidelines.
Let's first define a couple of terms before the individual technical components are detailed below.
- Event - A strongly typed and schemaed piece of data, usually representing something happening at a definite time. E.g. revision-create, user-button-click, page-load, etc.
- Stream - A contiguous (often unending) collection of events (loosely) ordered by time.
Stream Intake Service
from internal and external clients (browsers & apps). EventLogging + EventBus do some of this already, but are limited in scope and scale. This is EventGate.
Event Schema Repositories
This is comprised of several git repositories, all pulled together and easily accessible over a simple HTTP service / filebrowser. It may eventually also have a nice GUI.
Event Schema Guidelines
Some exist already for analytics purposes, some exist for mediawiki/event-schemas. We should unify these.
Stream Connectors for ingestion to and from various state stores
(MySQL, Redis, Druid, Cassandra, HDFS, etc.). Engineers should be able to use configuration to choose where their streams should be ingested.
Stream Configuration Service
Product needs the ability to have more dynamic control over how producers and consumers of events are configured. This includes things like sampling rate, time based event producing windows etc, downstream ingestion settings, etc.
Stream Processing Framework
Engineers should have a standardized way to build and deploy and maintain stream processing jobs, for both analytics and production purposes.
Timeline
FY2017-2018
- Q4: Interview product and technology stakeholders to collect desires, use cases, and requirements.
FY2018-2019
- Q1: Survey and choose technologies and solutions with input from Services and SRE.
- Q2: Begin implementation and deployment of some chosen techs.
- Q3: Deployment of eventgate-analytics stream intake service - T206785,
- Q4: Deployment of eventgate-main stream intake service - T218346
- Q4: Decommission Avro streams in favor of eventgate-analytics JSON based ones, T188136
- Q4: (new) CI support for event schemas repo - T206814
FY2019-2020
Stream Intake Service - T201068
Migrate Mediawiki EventBus events to eventgate-main & deprecate eventlogging-service-eventbus
- Q1: Continue migrating events to eventgate-main - T211248
- Q2: Decomission eventlogging-service-eventbus (Done in Q1)
Event Schema Repositories - T201063
- Q1: Schema repository hooks to generate dereferenced canonical version - T206812
- Q2: Support $ref in JSONSchemas - T206824
- Q2/Q3: Set up public HTTP endpoint for - T233630
- Q2/Q3: Create a new 'primary' and 'secondary' schema repositories.
-
Q3: Deprecate 'mediawiki' schema repository.(Moved to Q1 2020-2021)
Stream Configuration Service - T205319
- Q1: start planning with Audiences - Design Document
- Q2: implementation prototype - T233634
- Q3: Deployment and use by EventLogging and eventgate-analytics-external - T242122
Replace EventLogging Analytics
This is a long term project to be worked on in collaboration with Audiences engineers which includes work on the Event Schema Repositories and Event Stream Configuration Service components.
- Q1: Begin planning this work with Audiences - Design Document
- Q2: Coding work on all of these pieces (e.g. client side library to use Stream Config and POST to eventgate) - T228175
- Q2-Q4: deployment of Stream Config Service and some usages of eventgate-analytics-external
- Q4: Begin migrating existent EventLogging streams to EventGate - T238230 and T238138
See also: T225237: Better Use of Data
FY2020-2021
(As of 2020-06 these are timeline guesses, not goals.)
- Q1-Q3: Migrate all legacy EventLogging streams to Eventgate (see also)
- Q1: Deprecate 'mediawiki' schema repository
- Q1: Centralize all event stream configuration in mediawiki-config
- Q1: Automate Analytics Event Ingestion jobs using EventStreamConfig - T251609
- Q1: Improve monitoring of Analytics Event Ingestion using canary events - T251609
FY2022-2023 (Event-Platform)
Stream Connectors
NOTE: 2019-09: This work was stalled due to licensing issues with Confluent's HDFS Connector
Stream Processing Framework
- T308356: [Shared Event Platform] Ability to use Event Platform streams in Flink without boilerplate
- T324689: [EPIC] Streaming and event driven Python services
Use case collection
- JADE for ORES
- Fundraising banner impressions pipeline
- WDQS state updates - T244590: [Epic] Rework the WDQS updater as an event driven application
- Job Queue (implementation ongoing)
- Frontend Cache (varnish) invalidation
- Scalable EventLogging (with automatic visualization in tools (Pivot, etc.))
- Realtime SQL queries and state store updates. Can be used to verify real time that events have what they should/are valid
- Trending pageviews & edits
- Mobile App Events
- ElasticSearch index updates incorporating new revisions & ORES scores
- Automatic Prometheus metric transformation and collection
- Dependency tracking transport and stream processing
- Stream of reference/citation events: https://etherpad.wikimedia.org/p/RefEvents
- Client side error logging rate limiting and de-duping via Stream Processing - T217142
- Stream processing: Filtering exit text stream for specific keywords
- Stream processing: diff stream
- Stream processing: revision token stream, for ORES and for search.
- Stream processing: realtime historical data endpoint T240387: MW REST API Historical Data Endpoint Needs
- Stream processing: DDoS and other traffic anomaly detection:
- Outlier detection
- adaptive rate limiting
- Emitting structured metadata about page edits at save+parse time (links added, images added, wikidata items added, templates used, etc.)
- monitoring and alerting in spikes of referrers (Isaac)
(...add more as collected!)
- Stream of diffs for checking formulae in <math/> tags (cc @Physikerwelt)
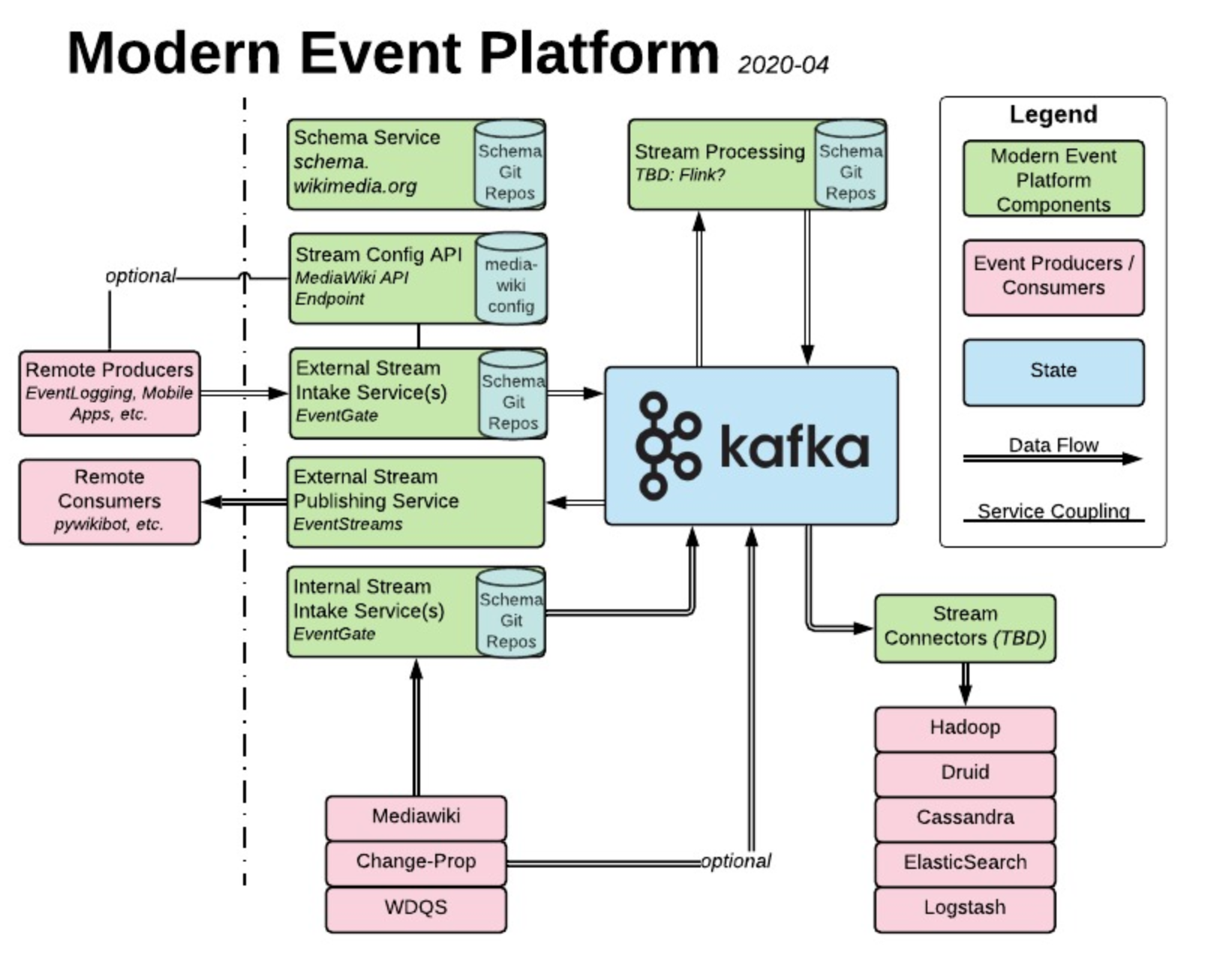
System Diagram
Diagram Here: https://www.lucidchart.com/documents/view/ca3f0d6b-9b45-4524-aed7-299e38908d0f/0_0