Instead of creating new deployment branches every Tuesday, I'd like to instead maintain 3 longer-lived deployment branches:
To continue the same release cadence that we currently have in place, we would do this instead:
- Merge from master into group0 on Tuesday.
- Merge from group0 to group1 on Wednesday.
- Merge from group1 to group2 on Thursday.
What has to change
Current practices during backports often involve either committing the same change twice (once on master, once on deployment branch) or cherry-picking the commit from master to the deployment branch. Neither of these practices are really practical for long lived branches. Since master will be merged into deployment, we end up with the same change happening twice and that results in a merge conflict. Since cherry-picking introduces the same change but isn't tracked by git, this too causes merge conflicts.
So the solution is for hotfixes to be prepared as follows:
- Branch from master -> new topic branch
- Make the change and commit
- Merge your topic branch to master
- During backport window, merge that same topic branch into the deployment branch.
This will ensure clean merges and sane branch history.
Historical rambling follows:
The way we deploy MediaWiki is horribly convoluted, tedious and error prone. The process has grown a lot of cruft over the years and very little has gotten cleaned up. Those who have had to deal with the complexity have been more or less content to live with it / too busy to do anything about it.
As the new guy saddled with the weekly 'train deployment' responsibilities, I am not numb to the problems and I'm not content to continue with a system that is so badly broken.
Problems with the current system
For those who are not fully familiar with the process, see Train_deploys. Even after multiple deploys it's still very difficult to follow without making any mistakes.
- Way too many steps - it's time consuming, tedious and error-prone
- Steep learning curve, low bus-factor
- Very fragile, lots of opportunities to kill entire groups of wikis.
- Every week we create a full clone of MediaWiki core, plus one for each of the deployed extensions.
- This is slow and wastes a lot of storage/bandwidth.
- Even worse, this stresses gerrit and in turn lowers everyone's productivity by delaying CI test results, slowing developer commits, pulls, code reviews, merges...
- We create a new branch on every deployed extension, then proceed to pin them to a specific commit (rather than a branch) via submodules. Branches are not necessary or even appropriate. We are just creating lots of digital garbage that won't ever be collected. Tags would be much more appropriate for marking weekly release milestones.
- There is no automated clean-up of old data, so removing old branches and related cached files must be performed manually (yet another error prone and easily overlooked task)
- Security patches aren't automatically carried forward from one week to the next, the must be manually applied each time we cut a new branch.
Proposed improvements
- Use git-new-workdir instead of cloning the entire remote repo each time we push a new release
- Use tags instead of a new branch for each weekly revision. We should only branch for a new 1.x version number, a weekly milestone hardly justifies an entirely new branch.
- We need to deal with the multiple versions of mediawiki in production symbolically instead of referring to specific versions.
- The deployment process should be one or two commands at most, not a whole series of complex and interdependent commands interrupted by gerrit submissions, rollbacks, +2ing of one's own patches, etc.
- security patches that aren't merged in gerrit should be carried forward automatically, no intervention required.
Branching
For a history lesson in how we got to where we are, see this mailing list thread: MediaWiki core deployments starting in April, and how that might work
@RobLa-WMF wrote:
One plan would be to have a "wmf" branch that does not trail far
behind the master. The extensions we deploy to the cluster can be
included as submodules for that given branch. The process for
deployment at that point will be "merge from master" or "update
submodule reference" on the wmf branch. Then on fenari, you will git
pull and git submodule update before scapping like you're currently
used to. The downside of this approach is that there's not an obvious
way to have multiple production branches in play (heterogeneous
deploy). Seems solvable (e.g wmf1, wmf2, etc), but that also seems
messy.
...
Another possible plan would be to have something somewhat closer to
what we have today, with new branches off of trunk for each
deployment, and deployments happening as frequently as weekly.
master
├── 1.20wmf01
├── 1.20wmf02
├── 1.20wmf03
...
├── 1.20wmf11
├── 1.20wmf12
├── REL1_20
├── 1.21wmf01
├── 1.21wmf02
├── 1.21wmf03
...
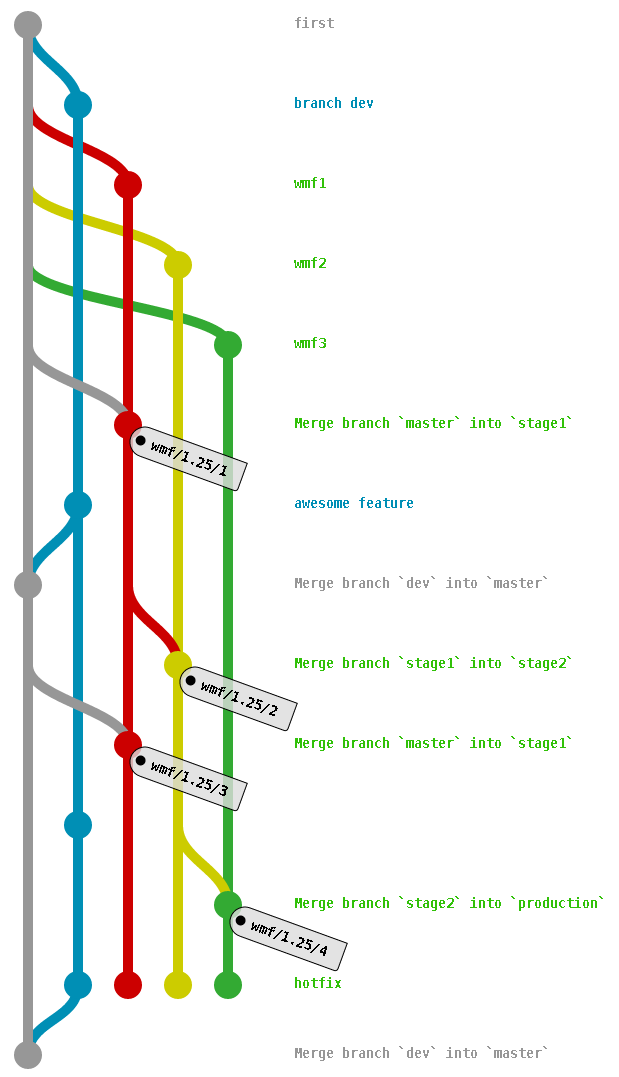
The conclusion was that it was decided to go with option #2. Honestly I'm not sure this was the right choice. I think we should have 3 "release" branches, instead of constantly making new ones, and use tags for the release pointers.
One branch represents each 'staged' group of wikis, referred to as group 0, 1 and 2 in the current system.
- release-staging (Group 0)
- release-next (Group 1)
- release-stable (Group 2)
Assuming we were to maintain the current release schedule as-is, the process would look something like this:
Tuesday
- merge staging -> next
- tag the head of next with a 1.25wmfXX-next release tag
- move group 1 wikis to the new tag
Wednesday
- merge: next -> stable
- tag the head of stable with a 1.25wmfN-stable release tag
- move group 2 to the new stable tag
- merge: master -> staging
- tag head of -staging with a 1.25wmfXX-staging release tag
- move group 0 wikis to the new tag
Pictures really are worth 1000 words (or at least a few hundred)
This is essentially the same thing as gitflo but using 2 staging branches.
Static Files
Static files are currently served from static-1.25wmfXX versioned directories with varnish in front caching for up to 30 days, which necessitates keeping around several complete copies of the core repo and all extensions, one for each revision that has been deployed within the past 30 days.
These are currently handled somewhat manually, along with the php-1.25wmfXX code checkouts. One elegant solution to this would be to serve the static files directly from a bare git repository. the first path component of the url could represent a git tag with the remaining path matching a file within the repository at the revision matching the requested tag.
mod_git
We could probably implement this using an apache module that calls libgit2. mod_git looks like it would work, with just a few minor modifications:
- mod_git uses a cookie to supply the git tag, we would want to use part of the url.
- don't serve php files (return 500 errors?)
- only allow release tags to be specified? mod_git currently will serve any branch, tag, or specific commit hash.
- We would probably need to perform a security audit and possibly some performance optimization.
This would drastically simplify deployment of static files and it would eliminate the need to periodically clean up a bunch of stale static files that get left behind from old deploys.
php-git2
Another option would be to serve the files from git using php-git2 - the libgit2 bindings for php5.3
Related tasks
There are a bunch of tasks related to overhauling the deployment systems and processes. Here are a few relevant links: T97068, T94620, T93428, T95375