This ticket documents the development needs around the OpenRefine Wikidata reconciliation interface.
Background
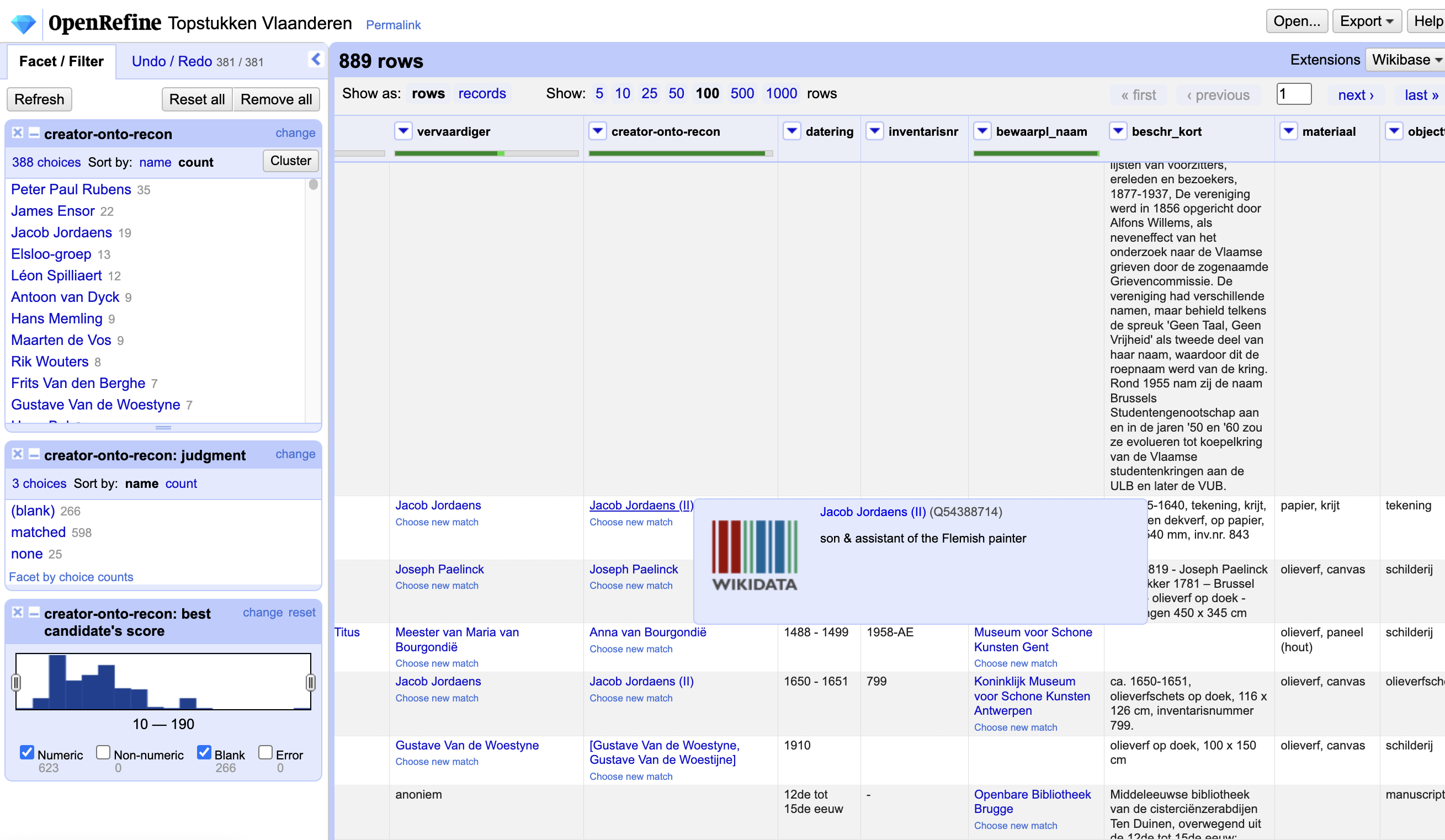
When using OpenRefine reconciliation to match table cells to Wikidata items, OpenRefine communicates with Wikidata via a protocol called the reconciliation API. This is a generic API for data matching which is implemented by other data providers too.
For Wikidata, this API is implemented by a Toollabs project: https://tools.wmflabs.org/openrefine-wikidata/. This is a Python web service which implements the API on top of Wikidata's existing APIs. It is developed on GitHub. This web service is also used by other Wikibase instances to provide a reconciliation service for these.
Where should this service live, in which language should it be written?
Since the current wrapper is relatively lightweight, it could well be rewritten in any other language (for instance in the interest of using a more suitable web framework, or just because the people developing it are more familiar with another stack).
I have tried to suggest to WMDE that it could potentially be something that would live closer to Wikibase itself, either developed as a MediaWiki extension, or a microservice, but I have not sensed a lot of interest in these discussions (for very good reasons - they have bigger fish to fry and rightfully so). Therefore we should not count on this API being implemented in Wikibase itself any time soon.
It is also worth noting that we can totally have different implementations of the reconciliation API for Wikidata running at the same time, and users picking the one they prefer to run their reconciliation queries. The current wrapper can currently be run locally (for instance with Docker) and this is something I recommend regularly to users when the main endpoint is overloaded.
Things that should be improved
- Performance
The current reconciliation service is slow and unreliable. At the moment processing a single reconciliation query can take about one second, which is extremely long. This comes from the fact that a lot of MediaWiki API calls need to be made to answer a query: we search for the entity using two search endpoints (action=query&list=search and action=wbsearchentities) and we retrieve the items JSON serialization via wbgetentities. We also need to perform occasional SPARQL queries to retrieve the list of subclasses of a given target type, to support type filtering. This could be improved in the following ways:Analyze and optimize the way queries are made, by processing queries in parallel and/or using asynchronous data loaders;done: we cannot make huge gains with the current architecture.- Eliminate one of the search API calls, either by working with WMF to have them expose a single search endpoint which fits our needs, or run our own search index on top of Wikidata (which requires running an updater to stay in sync, just like the WDQS or EditGroups - so this is quite involved);
Migrate away from the toollabs project infrastructure which is not designed to provide a high service availability.done: https://wikidata.reconci.link/
- Flexibility of the scoring mechanism
Scoring of reconciliation candidates is opaque. It is hard to understand for users why a certain candidate got some score. It is hard for reconciliation service maintainers to change the scoring mechanism as users are relying on the current behaviour for their reconciliation workflows. This could be improved in the following ways:- Explain the current reconciliation scoring mechanism publicly;
- Add support for returning individual reconciliation features which are exposed to the user. This requires adaptations to the protocol and to the client, OpenRefine.
- Running our own search index would also help with exposing more useful reconciliation scores (as we don't have access to term frequencies or search scores in general via the MediaWiki API).
- Documentation
The reconciliation interface is essentially undocumented.Current documentation is mostly written up in OpenRefine's wiki, but that is not appropriate: the reconciliation endpoint should have documentation on its own. (And then OpenRefine can document it as "the default reconciliation enpdoint"). This is especially important to document property paths, scoring and other similar features which cannot be easily discovered from OpenRefine's UI.We now have some technical documentation here: https://openrefine-wikibase.readthedocs.io/en/latest/
- Robustness of the web API
The web API does not react well to malformed input. This is mostly because it is written with a web framework that does not come with much input validation on its own. This could be improved in the following ways:- Now that we have JSON schemas to validate queries (via the W3C community group), these could be used in the service itself to validate queries;
- The service could be rewritten in a web framework that provides better validation for APIs (Swagger-based, for instance).