Recentchanges table powers one of core functionalities of Wikipedia and Co. It is the basically the backbone of every patrolling tool. From Special:RecentChanges to Watchlist to Huggle, and so on.
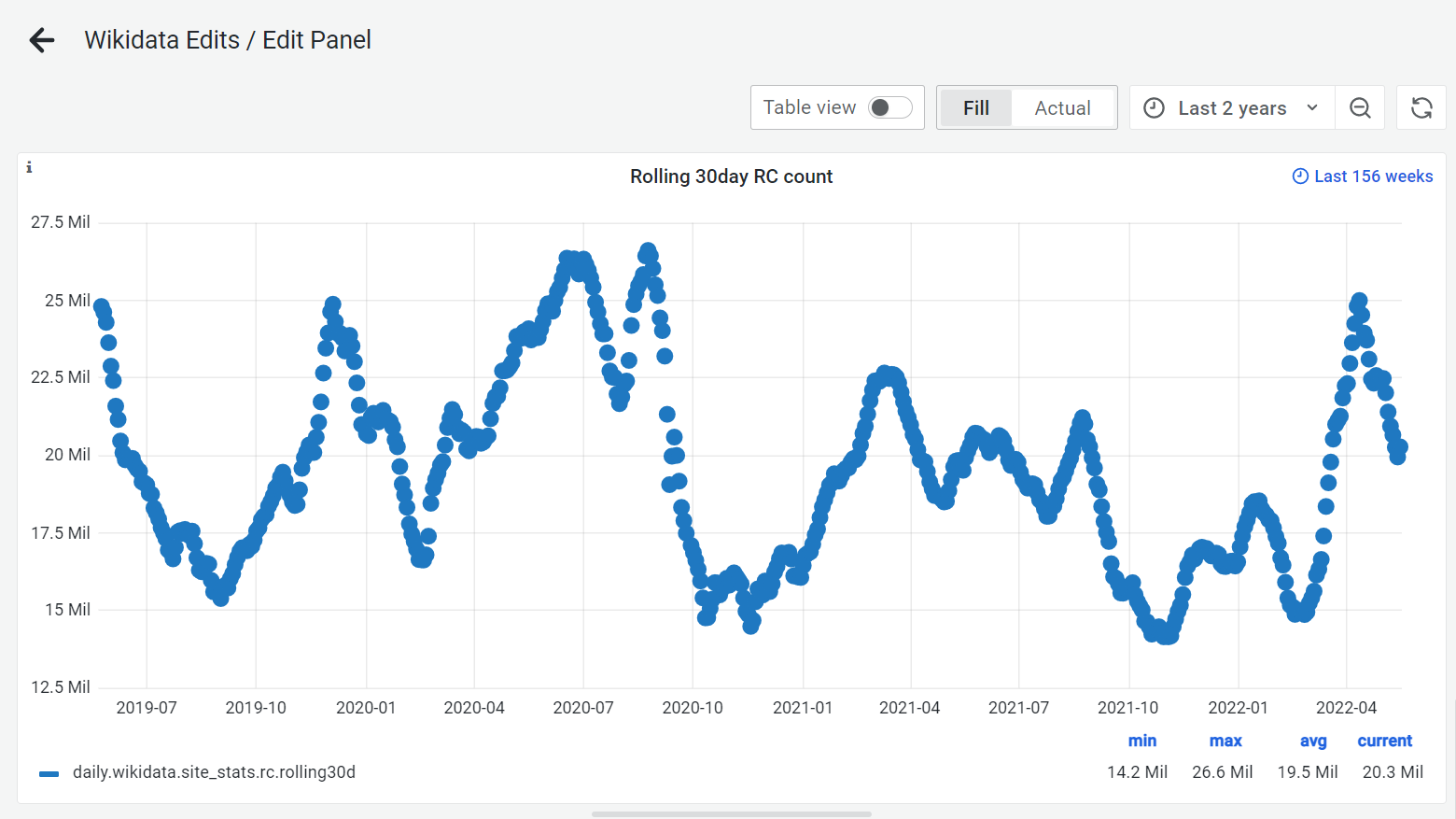
Since most of these tools provide a practically free-form SQL query builder, it easily can lead to "full table scan" queries. That is partially part of the design of rc table. It should small and nimble but pretty hot and being read in different ways as it has 10 indexes atm. The problem starts when a wiki gets really large due to bot edits or just the size of the wiki. For example Wikidata's rc table right now has 22M rows which is clearly bigger than what it should be. Currently, only three wikis have issues with recentchanges table: English Wikipedia, Wikidata, and Wikimedia Commons.
Here are several bugs caused by rc table getting large:
- T276699: Loading RC on en.wikipedia with a specific set of filters throws out an exception
- T239192: WMFTimeoutException in Wikidata recentchanges
It is also blocking adding more features such as T179010: [C-DIS][SW] Re-enable Wikidata Recent Changes integration on Commons
The underlying problem is that RC table is trying to juggle two things:
- Vandalism and problematic edits detection, which requires complex queries on non-patrolled edits (which are a small subset of edits). e.g. get me all edits that have high ores score but also certain tag.
- General pulse check of what's going on. For example, watchlist (=What is happening on pages I care about). This requires seeing all edits but on a more simpler, narrower query. No complex magic but needing the firehose of edits.
Proposed solutions (some mutually exclusive, some not):
- Normalizing the table: This is not a good design and won't help much. This table is the de-normalization table of mediawiki. It's a summary table.
- Reduce the time of storage rc actions in large wikis. Currently it's 30 days. This number has not came from any research and it's used just because it's round. In my role of Wikipedia volunteer, I barely went to older than a week.
- Split autopatrolled[1] actions out of rc table, into something like patrolled_recentchanges. In which querying it would be much limited (e.g. no tag filtering, no ores scores filtering, etc.)
- Reduce the time to store autopatrolled actions. This is basically hybrid of solution 2 & 3. That way we reduce the size without losing much.
- Store one week of data in one table, the rest of the month in another table (or one week for the first table and all of the month in the other meaning first week would get duplicated.) and make the query on the second table more restricted For example no tag filtering, no ores filtering, etc.
- Move it to a NoSQL solution. While I can see the reasoning, I'm not sure it would fix anything. These massive firehose of data would be slow to query in any system.
- That being said, Using Elastic sounds like a good idea (see T307328#7894820)
[1] "autopatrolled" can be useful for wikidata and commons only because "RC patrolling" is not enabled in English Wikipedia. RCPatrolling is a feature of mediawiki to find vandalism and reduce the work of patrollers in English Wikipedia. I find it disheartening it's not enabled there (which can be done with a bit community consultation and small design fixes)