The WVUI search widget used in the new Vector skin is not yet providing Wikidata the same functionality as the search box in the legacy Vector skin. There are multiple functional requirements that are not yet met:
Functional requirements
Related to the API queried for results:
1. The search must search through Labels and Aliases in any language and Entity-Ids
In the current search in the legacy Vector skin, the search box uses the action=wbsearchentities API endpoint. We need to write some new adapter code for the new Search box in the new Vector skin that does that as well.
The API used by the search box in the new Vector skin currently searches only page titles (Q-IDs in case of Wikidata) which is not helpful.
Note: Descriptions are intentionally not searched by the action=wbsearchentities API.
Related to how the results are displayed to the user:
1.: Show matches outside the Label in the current language
On Wikidata, the search goes not only through the Entities' Labels in the current Language, but also through their Aliases, and all the Labels and Aliases in all other languages. If any of these match, then that must also be shown in the search result. Also, if one searches for an Entity-ID directly (e.g., "Q42"), then that matching Entity must be shown as well.
2.: Handle multiple languages
Each "text object" (i.e. title, description, alias/search match)'s language should be explicitly set in a HTML lang="" attribute. This is because the language can be different due to language fallbacks and this change allows screen readers to function. We will also need to account for the possibility of different writing directions.
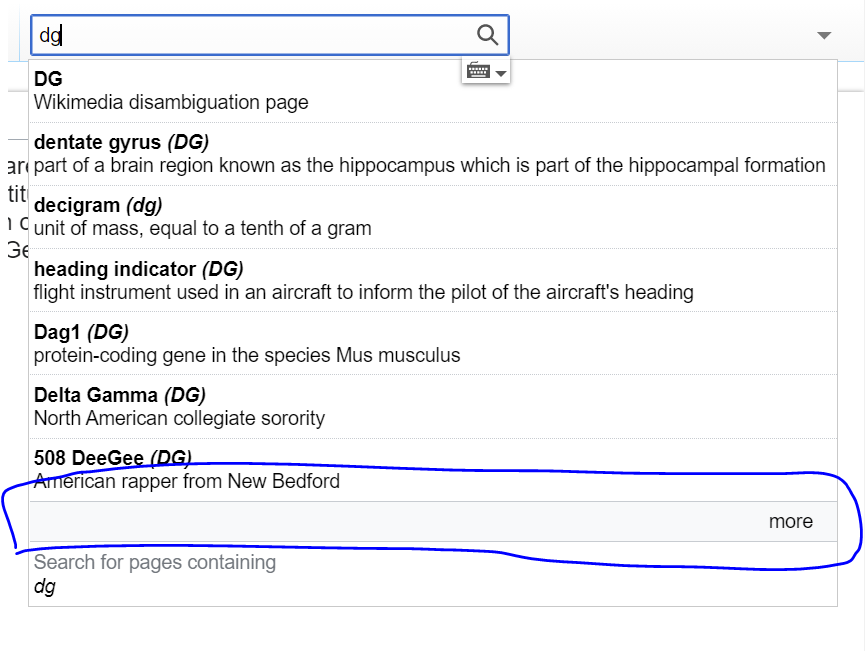
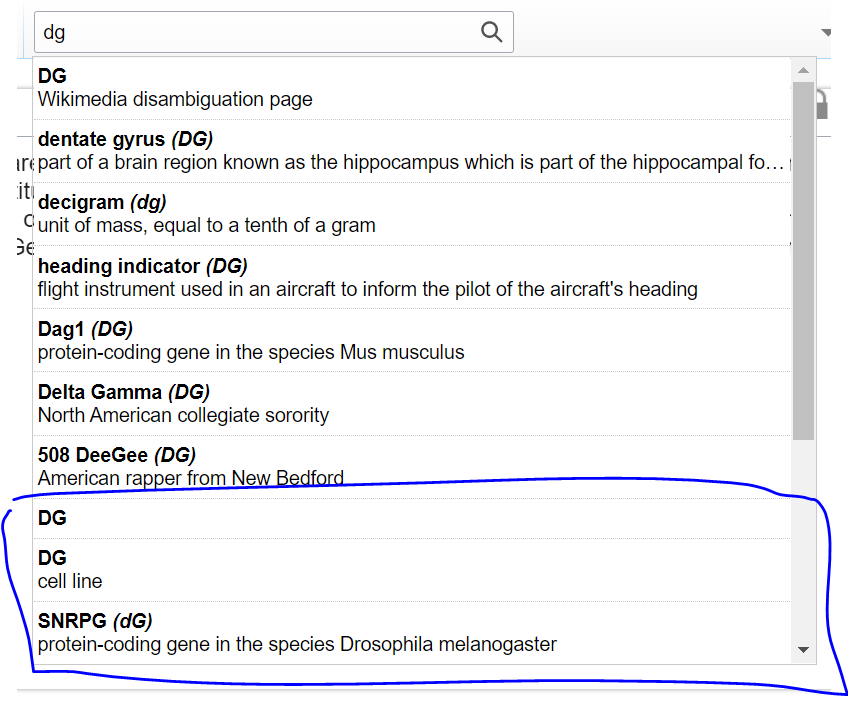
3.: Allow for loading more results in an obvious way
The current WVUI TypeaheadSearch component seems to limit the number of results being displayed in the menu to 10 (probably configurable). Wikidata provides a high amount of matching results per search, and one often doesn't usually find what one is looking for in the first couple of suggestions.
Therefore, we require users to be able to (maybe implicitly) request further results. The solution that we find must be obvious to users and the pattern should be the same across Wikidata (e.g. property lookup).
Possible solutions for 3.:
3.1. We provide users with an option (e.g., a “more”-pseudoresult) that they can click to load more results within the results menu.
3.2. We allow users to scroll within the dropdown results menu and load more results in the background on scroll
Original task description:
The existing search API only works with queries containing "Q" and returns results without the correct display title
https://wikidata.org/w/rest.php/v1/search/title?q=Q3&limit=10
This means in future Wikidata will become useless with the roll out of the latest version of Vector and will stall further adoption efforts of the wikimedia wvui library.