One challenge for the Content Translation tool is translate templates. While finding the template in target language can be done through Wikidata, finding the mapping between template parameters is not trivial. Currently this task is done heuristically. Here we are going to explore which possibilities offers ML and NLP to improve this task.
Problem: Giving a template with named parameters in language X, find the correspondent parameters in language Y.
Methodology: Considering the lack of labeled data (ground truth to learn from), we scope this as an unsupervised
1-to-1 matching problem. Although that in some cases the matching is 1-to-n or n-to-n (for example date can be spitted in day/month/year in one language and as one variable in another), for simplicity we focus in 1-to-1 matching.
Given this matching problem we explore three alternatives to match parameters:
- Metadata-based solution: We use metadata information contained in the Templata Data to create the matchings.
- Value-based solution: For each usage of a template, we check the values assigned to each parameter in languages X, and Y, assuming that same parameters must point to same values.
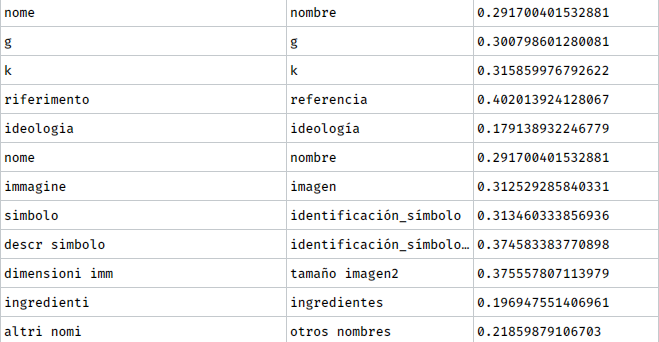
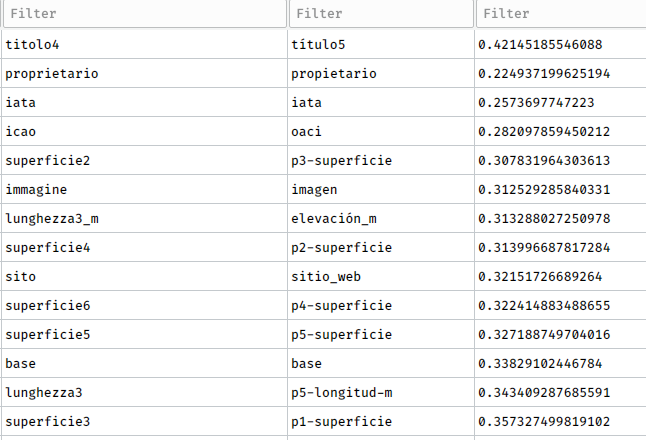
- Parameters named-based solution: We just compare parameters names in each language. (eg. Name in English will point to Nombre in Spanish).
For all cases, we need to compare pieces of text in two languages. To do so, we build our solution on top of aligned word-embeddings. Specifically, we use the Fasttextmultilingual embeddings, but creating our own Wikidata based alignments.
Evaluation: Given the lack of ground truth, we do a expert-based evaluation, given the results to the Language-Team
Code: Check in github.